二次元世界的Linux—东方Project之B站掠影

>>>> 1. 东方 Project
如果你曾看过一个名为「Bad Apple!!」的黑白影绘, 或者在各种音乐社区听歌时注意过「东方 Project」的字样, 但完全不了解这背后到底是什么? 所以好奇的在评论区发问——「这什么动漫?哪追番?」, 却遭到了冷遇甚至意义不明的嘲讽,之后无奈地只把它当作一个奇怪的符号。 那么希望这篇文章能让你有机会从数据的角度重新窥见这个由无数同人创作者构造的奇妙世界。
首先,东方 Project (后简称「东方」), 是指同人社团上海爱丽丝幻乐团所发布的弹幕射击系列游戏和音乐专辑, 广义上也包括了以此 (原作) 为基础进行的各种同人或商业的二次创作作品, 是一个涵盖了游戏、音乐、漫画、小说、动画等不同领域作品的总称。
注 1:同人与一次创作还是二次创作没有关系,可以简单地理解为非商业性创作活动,作者同时负责出版印刷或发行。
注 2: 上海爱丽丝幻乐团(上海アリス幻樂団)不在中国,实际成员仅有被称作 ZUN 的一人,本名「太田順也」

2004 年原作作者 ZUN 宣布开放二次创作以来, 东方在同人创作圈渐有星火燎原之势, 吸引了一大批能力优秀的创作者。此后的各种「三大〇〇」的称号也都从不缺席。 原作游戏剧情非常简单,留给玩家的只是一个又一个个性鲜明又有着强大能力的 少女 , 不少角色连一句对话和一幅立绘都没有, 但无数的二次创作已经为她们注入了灵魂, 作为虚幻之物的幻想乡好像一直以来就存在一样。
在下愚见,东方的魅力主要来源于经久不衰的二次创作, 这种能不断吸引一大群具有高水平创作能力的爱好者的现象在同人圈也不多见, 倒有几分早期的互联网社区和开源社区的自由风采。 虽然东方原作中也有一部分属于商业出版作品, 但这毫不影响 ZUN 继续参与同人创作的热情。
>>>> 2. 清廉正直的爬虫(简)
(完整版请阅读作者博客文章)![]()
由于本人精力有限,无法在短时期内搜集和分析所有领域的东方相关创作。现仅以 B 站为代表调查东方 Project 在视频投稿层面的情况。
B 站自建站之初就有大量的东方相关视频投稿,其中最早的 av2 即是由 bishi 站长投稿的东方音乐集。结合页面表现和浏览器控制台, 可以逐步还原不同的数据接口。调查后得到几个有用的 JSON API:
-
得到本视频投稿的标签信息
-
得到当前的硬币、收藏、播放等反映热度的信息
-
得到投稿中所有分页 (一个投稿可以对应多个视频内容)的基本信息
...(为了不给 B 站添更多麻烦此处不给出具体的 API 构造)
遍历每个视频投稿 av 号 , 使用获取标签信息的 API 判定是否为目标视频, 如果是则利用其他 API 获取数据,即为这一阶段爬虫的基本思路。像这样粗糙地爬取了两万条东方视频后,命中率越来越低, 而且明确的失效投稿(元数据残缺)竟然也统计到了 4000 个。 在一边整理记录从 B 站发现的 API 的时候, 我才下决心使用另一个不够完美的方案——从推荐列表递归的搜索。

由于目前已经采集到了两万份东方视频投稿的元数据, 所以可以把它们作为初始搜索集合,每遍历其中一个投稿的推荐列表, 都将命中成功的目标并入搜索集合,同时从搜索集合中不断筛选掉已搜索过的目标, 那么当搜索集合为空时,爬虫结束。
下表整理了本次爬虫工作得到的主要数据字段,分散在四个 Mongo Collection 中。
| TouhouDouga | Pages | Tag | Member |
|---|---|---|---|
| 投稿 av 号 | 分 P 的 cid |
tag_id | 会员 mid |
| up 主(投稿人) | 分 P 标题 | 关注数 | 会员名 |
| 标题 | 分 P 时长 | 使用数 | 头像 |
| 描述 | 弹幕元数据和弹幕文本 | ... | 注册时间 |
| 上传时间 | |
|
登记信息 |
| 投稿分区 | |
|
关注数 |
| 分页信息 | |
|
粉丝数 |
| 标签列表 | |
|
播放数 |
| 播放、硬币、收藏等热度信息 | |
|
... |
>>>> 3. 东方求闻数据
 投稿概况
投稿概况
利用投稿记录的上传时间,可以按月份聚合投稿数量然后计算累积数,得到以下投稿累积曲线。 
这里同时附上了每月投稿量的分布图。可以结合之后的热度分析食用。

正如之前发现的那样,在 B 站中存在不少失效或被删除的投稿。 在本文调查过程,将视分P 信息(一个投稿最少一个分 P)和实时热度信息都不为空作为有效视频的判定依据。
总计: 经调查,本次爬虫获取有效投稿总数为 59,611 个, 其中 6049 个投稿有多分 P,总分 P 数累计到接近十万, 总视频时长达到 76,341,480 秒,合 833 天。 总弹幕数(包括当前弹幕池外的部分)达到 12,430,822 条。 参与投稿的 up 主总数达到了 8838。 这个规模大概相当于 B 站建站前一年半的总和。
最多:最疯狂的分 P 是「东方同人音乐博物馆系列」,总计分页达 11,644 件。 up 主一直更新到最近的 C92 展会,然而这一万曲音乐也仅仅是东方同人音乐的冰山一角。 关于东方的音乐是个非常有趣的主题,有社团曾以音乐理论的角度作有《東方 Project 樂曲與音樂理論之考察》一书。

收藏数最多的是古老的 Bad Apple!! 影绘。
弹幕数最多的投稿是一个在 Flash 播放器时代的一个高级弹幕游戏 (利用 Flash 的漏洞在播放器上移动元素躲避弹幕), 同时也是一个仅会员可见的鬼畜向视频。
硬币数最多的投稿是国内同人社团原创的《秘封活动记录(月)》。
在所有投稿了东方相关的 up 主中,投稿最多的是「幻想乡的新月」。
再看一下投稿分区的分布。 随着 B 站投稿量日渐膨胀,分区设计一直是一个大难题。 B 站曾经稳定的分区格局是动画、音乐、游戏、娱乐、合集、新番六大区。 这里的「动画区」最初只是借用日语中「動画(douga)」一词, 翻译成中文是指投稿视频, 而不是指连载中的「TV 动画」。 后来 B 站把此局限于自制或者借助 3D 建模工具做的动画短片。 关于分区的详细介绍,见 B 站分区规范。

饼图中的 MMD・3D、短片・手书・配音、综合、MAD・AMV 其实都是动画区下的分区, 可以看到大概有半数的东方视频投稿都属于动画区。 这个结果也不奇怪,虽然东方原作的主体是弹幕射击游戏。 但是比起考虑怎么通关,显然是人物和故事更有意思。

标签和聚类
在之前爬虫的时候就说明了标签的重要性, 现在先依标签聚合所有投稿,并按聚合投稿的计数排序。 截取前 200 个高频标签生成以下词云。 这个词云至少体现了 B 站的用户对东方 Project 的认识或关注点。
不熟悉东方的读者可以从这里看到东方里的主要角色或者角色的外号。 注意有的人物角色拥有多种称呼, 比如标签「芙兰朵露斯卡雷特」、「芙兰朵露」、「二小姐」指的是同一个角色。

从投稿视频元数据信息中,得到总共 39525 个不同的标签。 其中有超过一半的标签在全站被使用不超过 5 次。 标签的本意是方便检索,可 B 站里很多标签仅仅是评论或者吐槽。 这很可能是早期阶段未曾重视而仅寄托于会员自觉导致的后果。
现在仅对前 500 个 高频标签做共现分析。先统计任意两个标签同时被标记在一个视频投稿里的次数, 由此得到的计数组成共现矩阵 C。(Ci,j 表示第 i 个标签和 第 j 个 标签共同出现的次数, 更精细的模型还可以使用二阶共现矩阵。[1]) 利用共现矩阵, 就可以得到每一个标签的向量化表示(在自然语言处理中经常提到的 Embedding), 此处以余弦值为相似度量编写一个 most_similar 函数就地调查一下与「芙兰朵露 · 斯卡雷特」最接近的标签(向量)。

效果非常不错,(好了我知道看到这里的人一定是萝莉控里的好人对吧)。
有了距离或者相似度定义,很自然的展开就应该是聚类。
有综述类的文章把常用的聚类算法分成了九大类。此处选用基于层次的聚类算法,一般选用自底向上的层次聚类 (Agglomerative Clustering),开始每个样本点都作为独立的一个群集存在,确定距离度量 (affinity) 和群集间距离定义 (linkage criteria) ,不断合并最接近的两个群集。常用的距离度量有欧氏距离、曼哈顿距离、余弦相似度;常用的群集间距离定义方法有群集质心距离 (centroid) ,群集平均距离 (average),群集最远距离 (complete) 等。
现在将之前生成的共现矩阵喂进 scikit-learn 的层次聚类算法库, 发现聚类效果比较一般,调整参数后依然。反思之后,猜测是由于部分绝对占优的标签干扰了数据的尺度, 于是撤下「东方」、「东方 PROJECT」等几个霸权标签后,重新生成了共现矩阵。 并利用奇异值分解(SVD)对每个标签的向量化表示降维,几度调整重新聚类如下, 终于得到了令人满意的聚类结果:

可以看到这几个聚类下都是东方原作系列里不同作品里的人物,有没看到你中意的角色?
共现分析其实是推荐系统中常用的一种技术,目前观察在 B 站的标签主页看到有一栏「相关标签」很可能也利用了标签共现矩阵。
视频热度分析
B 站对每一个投稿视频会实时统计下播放量、弹幕数、评论数、收藏数、硬币数、分享数等。 爬虫抓取的最晚的投稿截止到 2017 年 10 月 6 日, 实时热度统计截止到 2017 年 10 月 21 日。

B 站的评分算法更新过很多次,这里先无视具体排名先后, 把进过单日排行榜(前百)的东方视频先按月聚合统计一下。 结果发现在 2012 年之前的计数非常之少。 可能的原因有三点:1. 2012 年之前没有引入排行榜机制;2. 某次恶性事件引起大规模撤稿 ;3. 改版或迁移时产生的问题。

如果仅从 2013 年看起 (2013 年 5 月开放注册), 可以注意到每月的上榜数几乎是以半年为一个周期振荡。 在 2014 年下半年(睿站时代)后,B 站开始了从泛 ACG 圈向其他领域不断扩张, 分区板块也从一直以来的六大区不断增加到现在的 14 个分区。 即便如此,和东方有关的投稿在单日榜上的存在率虽略有下降, 但没有受到致命伤,甚至可以说还很坚强。 另外,经查,存续于 2014 年 5 月到 2016 年 7 月的由 up 主烤夜雀 创立的 THVideo 东方专属弹幕站分流了 6000 多件东方视频投稿, 它们中大部分稿件没有同时在 B 站投递。
现在开始探索热度基础信息: 播放量
播放量是按 cookie 统计的视频被播放的次数(哪怕只播放一秒), 可以当成本次爬虫所能了解到的 6 个热度指标的基数。 以下数据分析排除了 725 件仅会员才能观看的视频 (对于这一部分稿件,API 返回的播放量是 --。)
直接可视化播放量的分布,会得到一个极端正偏态的「长尾曲线」。 对此,一般的策略是通过取对数来提高可视化的信息效率。 可以看到播放量的分布在对数尺度下的偏度还是比较正的。 直接从图中读出播放量的中位数大概是 1000, (经查中位数实际上是 1408)。 如果将播放量低于 1000 的稿件视为绝对低播放稿件, 发现游戏区的 13000 余视频中有 10000 件左右是如此表现。 这也算意料之中,如果关注过 B 站首页的实时投稿增量, 可以注意到游戏区总是增长最快的。 毕竟录制屏幕的门槛远不及制作一期动画短片。
接下来是收藏、硬币、分享。
这三个指标反映了观众认可的程度,很显然,它们都会远比播放量小。 根据平时逛 B 站的经验,这三者的数量一般是依次递减一个数量级。 因为收藏几乎是不用成本的,所以收藏一般是除了播放量外最多的指标, 接着是硬币,硬币作为 B 站的基本经济单位(不是 Q 币那种代币)在用户之间流通,对一般用户来说是一种比较有限的资源, 每个用户最多为一个视频投出两个硬币。 这三个指标中最少的一般是分享数,因为即使用户受到一时冲击和震撼, 在分享到社交网站时还要承担额外的社交压力。
对以上指标取对数,绘制 kde 化的二维分布图: 发现播放量和收藏数竟然呈现一种近似的线性关系, (使用 numpy 对原始数据计算 Pearson 相关系数为 0.804)。 最集中的情况,播放量大概会是收藏数的 20 倍。 同时参考硬币数和分享数的分布, 播放量不足 1000 的投稿确实很难收获超过十几个硬币和几个分享。 另外,对于那些进入过单日榜单的投稿来说, 一般至少需要两万以上的播放量。
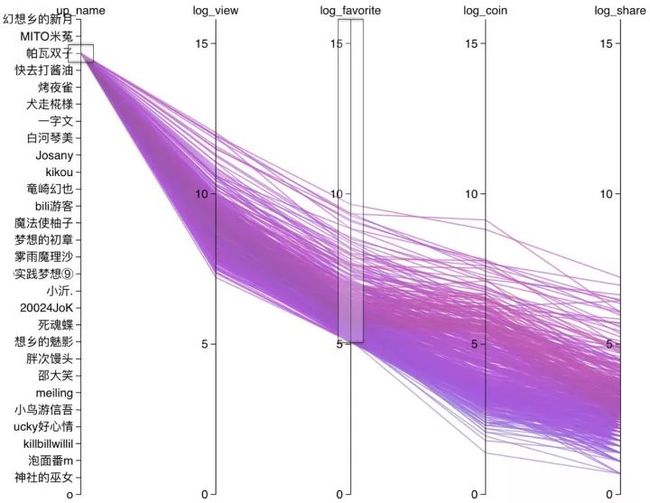
发现播放量和收藏数竟然呈现一种近似的线性关系, (使用 numpy 对原始数据计算 Pearson 相关系数为 0.804)。 最集中的情况,播放量大概会是收藏数的 20 倍。 同时参考硬币数和分享数的分布, 播放量不足 1000 的投稿确实很难收获超过十几个硬币和几个分享。 另外,对于那些进入过单日榜单的投稿来说, 一般至少需要两万以上的播放量。 对于高维数据的可视化策略,除了可以组合不同的低维子空间,还可以利用平行坐标图表示。这里利用 syntagmatic 的 D3 扩展库,选取收藏数较高的一部分,截图如下(交互式图例见原作者博客内容)。
对于高维数据的可视化策略,除了可以组合不同的低维子空间,还可以利用平行坐标图表示。这里利用 syntagmatic 的 D3 扩展库,选取收藏数较高的一部分,截图如下(交互式图例见原作者博客内容)。

平行坐标图中的颜色表示硬币-收藏比,越靠近红色值越高,越靠近蓝色值越低。
数据探索到这里,我翻开了自己在 B 站的收藏夹, 手动检查了一部分我认可的高质量作品。 首先它们全部来源于动画区的 MMD 和手绘动画, 有的是授权搬运+字幕甚至配音, 还有一部分是 up 主原创。 它们没有全部都进入过单日榜前百, 但几乎都有一个共同点是:硬币-收藏比明显偏高,普遍达到了 20% 以上, 极少数接近甚至超过了收藏数。 从交互行为来看,无论在桌面端还是移动端, 收藏和投币是除了播放以外最容易被触及的操作。 单日榜意味着视频投稿在一日内的表现, 对于衡量稿件的综合质量来说可能不算一个特别公平的指标。 于是我对所有硬币数多于 100 播放量多于 4000 的动画区和音乐区的投稿进行调查, 并将硬币-收藏比超过 16% 的查询结果导入了一个公开的 Google 表格里(考古清单) ,欢迎查询。如果以后用空,可以逐步改造成一个专门的东方视频投稿导航站。
在第一轮爬虫进行后,专门针对投稿了东方视频的 up 主的信息进行了收集。现在很想知道投稿过的 up 主都是在什么时候注册的账号: 看来 up 主大都是老用户(2013 年 5 月之前,一年中只有少数时间能够注册)。投稿了 200 件视频以上的 up 主:[ '幻想乡的新月', '指猫', 'R十寻', 'MITO米菟', '帕瓦双子', '梓喵快去打酱油', '犬走椛様', '烤夜雀', '伊吹小秋', '一字文', 'Pain', '白河琴美', 'Josany', '竜崎幻也', 'kikou', 'bili游客', '路过的魔法使柚子', '绝望是梦想的初章', '小沂.', '雺雨魔理沙', '⑨实践梦想⑨', '死魂蝶', '20024JoK', '幻想乡的魅影', '胖次馒头', 'Lucky好心情', 'meiling', '朝夜神社的巫女', '邵大笑', '小鸟游信吾', 'killbillwillil', '泡面番m' ],感兴趣的可以去关注一波。此处将 up 主名字加入平行坐标观察,可以注意到几位高人气 up 主(幻想乡的新月、烤夜雀、帕瓦双子……)线条普遍偏红(可交互版本见原作博客),说明由知名 up 主投稿可以获得更高的硬币-收藏比。
看来 up 主大都是老用户(2013 年 5 月之前,一年中只有少数时间能够注册)。投稿了 200 件视频以上的 up 主:[ '幻想乡的新月', '指猫', 'R十寻', 'MITO米菟', '帕瓦双子', '梓喵快去打酱油', '犬走椛様', '烤夜雀', '伊吹小秋', '一字文', 'Pain', '白河琴美', 'Josany', '竜崎幻也', 'kikou', 'bili游客', '路过的魔法使柚子', '绝望是梦想的初章', '小沂.', '雺雨魔理沙', '⑨实践梦想⑨', '死魂蝶', '20024JoK', '幻想乡的魅影', '胖次馒头', 'Lucky好心情', 'meiling', '朝夜神社的巫女', '邵大笑', '小鸟游信吾', 'killbillwillil', '泡面番m' ],感兴趣的可以去关注一波。此处将 up 主名字加入平行坐标观察,可以注意到几位高人气 up 主(幻想乡的新月、烤夜雀、帕瓦双子……)线条普遍偏红(可交互版本见原作博客),说明由知名 up 主投稿可以获得更高的硬币-收藏比。
![]() 弹幕丛中说弹幕
弹幕丛中说弹幕![]()
弹幕本意指军事上的密集火力(比如战舰的防空弹幕), 在弹幕射击游戏中被指玩家自机或敌机射出的子弹。 「弹幕」的概念扩展到同屏评论,最早是由 Niconico(N 站)引入的。 由于随视频播放时同屏划过的词句很像弹幕射击游戏里的弹幕,由此得名。 B 站算是继承了 N 站的弹幕概念,但是和 N 站不同的是, B 站同时也继承了传统在线视频网站的评论区。 本意可能是希望用户有意识的分离弹幕和评论。 而且 B 站很早就提供弹幕屏蔽规则来保护观感, 然而还是很难抵挡随着大众化带来的用户群素质下降问题。
B 站的弹幕按性质可以分为两种: 第一种弹幕体现了观众对当前画面的评论或描述, 一般含有较丰富的信息量,有一定的描述意义,(信息质量接近微博短文本)。 第二种主要为了增加当前场景的表现力而存在, 而且无论文本长短,信息量一般比较有限,主要是一种情感上的宣泄。 对第二种弹幕的判定除了广泛存在于大家的屏蔽设定里的 ^2333* 和 ^6666*, 还有各种弹幕专用梗,或者纯粹的噪音。 无论哪一种,弹幕内都充斥着未登录词、特殊符号、混杂语言、错别字……, 而且弹幕之间的上下文主要依赖视频内容, 这使得弹幕文本的挖掘工作必然和其他传统场景有所不同。
由于弹幕文本中有非常多的常规语料外的词汇,为了分词的需要,现在先尝试利用全部普通弹幕的文本进行抽词,但是在这之前必须完成适度的文本清洗。
-
仅保留弹幕文本里的字母、数字、汉字、假名。(舍弃绝大部分颜文字和特殊符号,不小心误杀了最强的 ⑨……)。
-
去掉超高频的刷屏弹幕(2333*, 卧槽,噗,第 x……)
-
去掉过长的弹幕,和弹幕用字长度比过低,字母和数字过多的弹幕(包括至少十万个紫 x 脸滚键盘梗)。
此时统计得到总弹幕数 710 余万, 弹幕总字数 5700 余万,共使用字符 8974 个。 (如果每个字都是屏幕前字体的大小,那么这些弹幕可以连续的从杭州东发射到上海虹桥) 参考 Matrix67 博客 [2] 中的无知识库的抽词方法, 计算每个候选词的互信息(mutual information) 和左右邻字熵, 保留尽可能两者都大的候选词。
互信息体现的是一个候选词的凝聚程度,比如「电影院」这三个字的凝聚程度可由 p(电影院) 与 p(电) · p(影院) 比值和 p(电影院) 与 p(电影) · p(院) 的比值中的较小值体现。左右邻字熵体现的是一个候选词与上下文环境接合的自由程度。对所有字符串建立前缀和后缀字典树,可完成所有计算。这里使用了 sing1ee 在 GitHub 上的 Java 实现(根据弹幕实际表现情况修改了部分代码)。
取候选词最长为 5, 凝聚程度最小为 1, 左右邻字熵最小为 2 ,最后抽得潜在候选词 42,368 个, 其中约 96% 的词在弹幕文本中出现频率低于万分之一。 检查本次抽取的候选词有很多算常用词, 将本次抽取的候选词集合排除掉常规中文词库, (如果能完成标注工作,就可以逐步完善一个「弹幕专用词库」) ,取前 200 个高频新词生成以下词云:
对比高频的弹幕抽词和之前的标签用词可以发现二者在语义上高度重复。 只不过标签多用正式的全名,而弹幕则多用简称。 将抽取自弹幕的新词导入 jieba 完成分词。 检查分词的过程中发现含有平/片假名的词语没有被解析, 追溯到 jieba 源码才发现正则筛选的时候仅保留了汉字、字母、数字和少数几个符号。 所幸含有假名的字幕大部分是在一些歌词字幕里出现,无关大局。 现在将分词完的弹幕文本装填进 gensim(word2vec 的 Python 实现),设置词向量维度为 120,看看能训练一个怎样的词向量模型。
和之前共现分析类似,这里的相似度依然使用余弦值。 让我们看看一些有意思的词向量:
>>> 第一问:梅莉何者 <<<

(不知紫之梦为梅莉欤?梅莉之梦为紫欤?)
>>> 第二问:白玉楼何处 <<<

(当然在冥界啦,其他的也都是幻想乡里的场所名)
>>> 第三问:大家都喜欢哪些 CP <<<

>>> 第四问:除了东方,弹幕里还有哪些教 <<<

由于二次设定的广泛存在,东方 Project 几乎不存在绝对严格的人设(Character Design)。现尝试利用词向量的成果探索一部分角色的亲疏关系。利用之前训练好的词向量模型,可以半自动的整理一个角色名同义列表。将东方红魔乡到东方风神录中出场的人物归并之后重新训练了一个词向量模型。并抽取其中的 34 个角色两两之间计算相似度,尝试生成一个人物关系图,这里选用了 Gephi 完成关系图的绘制。线条的粗细表示人物之间的相似度。图中最引人注目的是一个连正式名字都没有的角色——大妖精(大酱),收获了这 34 个角色中最高的关联度,让人不由得想起《被隐藏的生物圈》中的黑暗设定。

红魔乡、妖妖梦、永夜抄、风神录 人物关系图
有不少极端东方粉曾建议 B 站开设「东方分区」,窃以为实在不必。如果能引导好用户增删标签,辅以弹幕主题提取、观众特征等多个维度,完全应该能设计一套弹性的分区机制,这样也可避免固定分区引导的臃肿。但是比起弹性分区,可能是一套精准的推荐系统更紧要(移动端 app 已全面部署)。
>>>> 结语
日本商业 ACG 的发达和数十年同人创作的发展密不可分。 同人创作即可作为商业 ACG 的后备资源,也可为产业方向作出实验性探索。 相比其他投入巨大的商业 ACG, 东方 Project 以其独特的魅力长青于平成世代可谓奇迹。
本文对「东方 Project」在中国重要的 ACG 文化集散中心——bilibili 建站以来的传播和发展。 同时有效地对投稿的标签完成了聚类, 并从不同维度探索了投稿的热度情况, 最后对观众发送的弹幕内容进行了适度的文本挖掘, 提取了重要的新词,同时建立词向量模型完成了角色关系的分析。
[1] Wartena, C., Brussee, R., & Wibbels, M. (2009, November). Using tag co-occurrence for recommendation. In Intelligent Systems Design and Applications, 2009. ISDA’09. Ninth International Conference on (pp. 273-278). IEEE.
[2] 顾森, (2012 年 8 月 10 日). Matrix67 Blog, 互联网时代的社会语言学:基于 SNS 的文本数据挖掘
❈
本名:方堃 ([email protected] 已注册 PGP)
个人博客: http://kwenstring.com/
希望有机会从事数据分析相关工作,求不嫌弃的大佬收留
∈ 伪 ZJUer
∈ Unix、Python、Chrome 深度用户
∈ 失业 失踪人口
∈ 人工智障新手魔法师
❈
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
