H.266/VVC代码学习:帧内ISP技术相关代码
ISP预测模式主要是将当前块划分为多个子块,每个子块的重建信号可用于生成下一个子块的预测值。所有子块的预测模式都相同,且只能是PLANAR模式或者DC模式或者帧内角度模式。
帧内预测模式的选择主要是在estIntraPredLumaQT函数中,ISP模式的选择也是在该函数之中,ISP模式的选择在cu.lfnstIdx=0时才会进行。以下是ISP模式大致选择流程:
一、初始化
1、根据当前CU尺寸初始化ISP划分后的水平分区和垂直分区数
2、根据当前CU划分后TU的尺寸的大小是否满足LFNST使用条件(CU::canUseLfnstWithISP函数),决定是否跳过该划分方式和LFNST的组合的检查。
if( testISP )
{
//reset the variables used for the tests
//重置ISP测试用到的变量
m_regIntraRDListWithCosts.clear();
int numTotalPartsHor = (int)width >> floorLog2(CU::getISPSplitDim(width, height, TU_1D_VERT_SPLIT));//水平划分所得分区数
int numTotalPartsVer = (int)height >> floorLog2(CU::getISPSplitDim(width, height, TU_1D_HORZ_SPLIT));//垂直划分所得分区数
m_ispTestedModes[0].init( numTotalPartsHor, numTotalPartsVer );//初始化LfnstIdx为0时ISP测试数据
//the total number of subpartitions is modified to take into account the cases where LFNST cannot be combined with ISP due to size restrictions
//修改子分区的总数以考虑由于大小限制而无法将LFNST与ISP组合的情况。
numTotalPartsHor = sps.getUseLFNST() && CU::canUseLfnstWithISP(cu.Y(), HOR_INTRA_SUBPARTITIONS) ? numTotalPartsHor : 0;
numTotalPartsVer = sps.getUseLFNST() && CU::canUseLfnstWithISP(cu.Y(), VER_INTRA_SUBPARTITIONS) ? numTotalPartsVer : 0;
for (int j = 1; j < NUM_LFNST_NUM_PER_SET; j++)
{
m_ispTestedModes[j].init(numTotalPartsHor, numTotalPartsVer);
}
}二、将ISP模式加入到模式列表中
在estIntraPredLumaQT函数进行RD Cost细选之前,将初始化后的ISP模式加入进候选模式列表中。
if ( testISP )
{
// we reserve positions for ISP in the common full RD list
// 我们为ISP在通用的完整RD列表中保留位置
const int maxNumRDModesISP = sps.getUseLFNST() ? 16 * NUM_LFNST_NUM_PER_SET : 16;
m_curIspLfnstIdx = 0;
for (int i = 0; i < maxNumRDModesISP; i++)
{
uiRdModeList.push_back( ModeInfo( false, false, 0, INTRA_SUBPARTITIONS_RESERVED, 0 ) );
}
}三、准备ISP所使用的的候选模式列表
在estIntraPredLumaQT函数进行第三轮RD Cost细选时,在遍历完常规帧内角度模式和MIP模式之后,就开始ISP模式的遍历。
在第一次进行ISP模式遍历的时候,需要为ISP模式准备用来RD Cost测试的帧内模式候选列表。这里用到m_regIntraRDListWithCosts列表,该列表主要包含的是第三轮RD Cost细选所包含的常规帧内角度模式。首先对该列表进行排序,选出最佳帧内角度模式bestNormalIntraAngle。
然后依次将PLANAR模式、最佳帧内角度模式、m_regIntraRDListWithCosts列表其余模式(除DC模式外)、DC模式加入到保存到水平划分模式列表和垂直划分模式列表中。
//It prepares the list of potential intra modes candidates that will be tested using RD costs
//该函数用来准备使用RD Cost测试的潜在帧内模式候选列表
bool IntraSearch::xSortISPCandList(double bestCostSoFar, double bestNonISPCost, ModeInfo bestNonISPMode)
{
int bestISPModeInRelCU = -1;
m_modeCtrl->setStopNonDCT2Transforms(false);
//ISP快速算法
if (m_pcEncCfg->getUseFastISP())
{
//we check if the ISP tests can be cancelled
//我们检查ISP测试是否可以取消
double thSkipISP = 1.4;
if (bestNonISPCost > bestCostSoFar * thSkipISP)
{ //如果bestNonISPCost > bestCostSoFar * thSkipISP则不再对ISP进行测试
for (int splitIdx = 0; splitIdx < NUM_INTRA_SUBPARTITIONS_MODES - 1; splitIdx++)
{
for (int j = 0; j < NUM_LFNST_NUM_PER_SET; j++)
{
m_ispTestedModes[j].splitIsFinished[splitIdx] = true;
}
}
return false;
}
if (!updateISPStatusFromRelCU(bestNonISPCost, bestNonISPMode, bestISPModeInRelCU))
{ //根据相关CU的信息更新当前ISP状态
return false;
}
}
for (int k = 0; k < m_ispCandListHor.size(); k++)
{
m_ispCandListHor.at(k).ispMod = HOR_INTRA_SUBPARTITIONS; //we set the correct ISP split type value 设置正确的ISP划分类型
}
auto origHadList = m_ispCandListHor; // save the original hadamard list of regular intra 保存常规帧内模式的原始hadamard列表
bool modeIsInList[NUM_LUMA_MODE] = { false };
m_ispCandListHor.clear();
m_ispCandListVer.clear();
// we sort the normal intra modes according to their full RD costs
// 我们根据它们的RD Costs对常规帧内模式进行排序
std::sort(m_regIntraRDListWithCosts.begin(), m_regIntraRDListWithCosts.end(), ModeInfoWithCost::compareModeInfoWithCost);
// we get the best angle from the regular intra list
// 我们从常规帧内模式列表中得到最佳预测角度模式
int bestNormalIntraAngle = -1;
for (int modeIdx = 0; modeIdx < m_regIntraRDListWithCosts.size(); modeIdx++)
{
if (bestNormalIntraAngle == -1 && m_regIntraRDListWithCosts.at(modeIdx).modeId > DC_IDX)
{
bestNormalIntraAngle = m_regIntraRDListWithCosts.at(modeIdx).modeId;
break;
}
}
int mode1 = PLANAR_IDX;
int mode2 = bestNormalIntraAngle;
ModeInfo refMode = origHadList.at(0);
auto* destListPtr = &m_ispCandListHor;
//List creation
if (m_pcEncCfg->getUseFastISP() && bestISPModeInRelCU != -1) //RelCU intra mode
{ //将相关CU的最佳ISP模式加入到候选列表中
destListPtr->push_back(ModeInfo(refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, bestISPModeInRelCU));
modeIsInList[bestISPModeInRelCU] = true;
}
// Planar
if (!modeIsInList[mode1])
{
destListPtr->push_back(ModeInfo(refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, mode1));
modeIsInList[mode1] = true;
}
// Best angle in regular intra
if (mode2 != -1 && !modeIsInList[mode2])
{
destListPtr->push_back(ModeInfo(refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, mode2));
modeIsInList[mode2] = true;
}
// Remaining regular intra modes that were full RD tested (except DC, which is added after the angles from regular intra)
// 其余的进行完全RD测试的常规帧内模式(除了DC,它是在常规帧内角度模式之后添加的)
int dcModeIndex = -1;
for (int remModeIdx = 0; remModeIdx < m_regIntraRDListWithCosts.size(); remModeIdx++)
{
int currentMode = m_regIntraRDListWithCosts.at(remModeIdx).modeId;
if (currentMode != mode1 && currentMode != mode2 && !modeIsInList[currentMode])
{ //如果当前模式不是Planar模式且不是最佳角度模式且不在模式列表中
if (currentMode > DC_IDX)
{
destListPtr->push_back(ModeInfo(refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, currentMode));
modeIsInList[currentMode] = true;
}
else if (currentMode == DC_IDX)
{
dcModeIndex = remModeIdx;
}
}
}
// DC is added after the angles from regular intra
// 在与常规帧内角度模式之后添加DC
if (dcModeIndex != -1 && !modeIsInList[DC_IDX])
{
destListPtr->push_back(ModeInfo(refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, DC_IDX));
modeIsInList[DC_IDX] = true;
}
// We add extra candidates to the list that will only be tested if ISP is likely to win
// 我们在列表中添加了额外的候选模式,只有在ISP可能胜出的情况下才会进行测试
for (int j = 0; j < NUM_LFNST_NUM_PER_SET; j++)
{
m_ispTestedModes[j].numOrigModesToTest = (int)destListPtr->size();
}
const int addedModesFromHadList = 3;//从hadamard列表添加的模式数
int newModesAdded = 0;
for (int k = 0; k < origHadList.size(); k++)
{
if (newModesAdded == addedModesFromHadList)
{
break;
}
if (!modeIsInList[origHadList.at(k).modeId])
{
destListPtr->push_back( ModeInfo( refMode.mipFlg, refMode.mipTrFlg, refMode.mRefId, refMode.ispMod, origHadList.at(k).modeId ) );
newModesAdded++;
}
}
if (m_pcEncCfg->getUseFastISP() && bestISPModeInRelCU != -1)
{
destListPtr->resize(1);
}
// Copy modes to other split-type list
// 将模式复制到其他划分类型列表
m_ispCandListVer = m_ispCandListHor;
for (int i = 0; i < m_ispCandListVer.size(); i++)
{
m_ispCandListVer[i].ispMod = VER_INTRA_SUBPARTITIONS;
}
// Reset the tested modes information to 0
// 将测试模式信息重置为0
for (int j = 0; j < NUM_LFNST_NUM_PER_SET; j++)
{
for (int i = 0; i < m_ispCandListHor.size(); i++)
{
m_ispTestedModes[j].clearISPModeInfo(m_ispCandListHor[i].modeId);
}
}
return true;
}四、进行ISP 模式RD cost的选择
通过调用:xGetNextISPMode函数决定ISP哪些划分模式和预测模式可以组合使用进行完整的RD Cost测试。
这里涉及到许多快速算法,许多地方没有看明白.......
// It decides which modes from the ISP lists can be full RD tested
// 它决定了ISP列表中的哪些模式可以进行完整的RD测试
void IntraSearch::xGetNextISPMode(ModeInfo& modeInfo, const ModeInfo* lastMode, const Size cuSize)
{
static_vector* rdModeLists[2] = { &m_ispCandListHor, &m_ispCandListVer };
const int curIspLfnstIdx = m_curIspLfnstIdx;
if (curIspLfnstIdx >= NUM_LFNST_NUM_PER_SET)
{
//All lfnst indices have been checked
//所有lfnst索引均已检查
return;
}
ISPType nextISPcandSplitType;
auto& ispTestedModes = m_ispTestedModes[curIspLfnstIdx];
//是否已经完成水平和垂直划分
const bool horSplitIsTerminated = ispTestedModes.splitIsFinished[HOR_INTRA_SUBPARTITIONS - 1];
const bool verSplitIsTerminated = ispTestedModes.splitIsFinished[VER_INTRA_SUBPARTITIONS - 1];
if (!horSplitIsTerminated && !verSplitIsTerminated)//如果既没有进行水平划分也没有进行垂直划分
{
nextISPcandSplitType = !lastMode ? HOR_INTRA_SUBPARTITIONS : lastMode->ispMod == HOR_INTRA_SUBPARTITIONS ? VER_INTRA_SUBPARTITIONS : HOR_INTRA_SUBPARTITIONS;
}
else if (!horSplitIsTerminated && verSplitIsTerminated)//如果已经进行垂直划分且没有进行水平划分
{
nextISPcandSplitType = HOR_INTRA_SUBPARTITIONS;
}
else if (horSplitIsTerminated && !verSplitIsTerminated)//如果已经进行水平划分且没有进行垂直划分
{
nextISPcandSplitType = VER_INTRA_SUBPARTITIONS;
}
else//水平和垂直划分都已经进行完
{
xFinishISPModes();
return; // no more modes will be tested 不再测试模式
}
int maxNumSubPartitions = ispTestedModes.numTotalParts[nextISPcandSplitType - 1];//最大分区数
// We try to break the split here for lfnst > 0 according to the first mode
// 根据第一种模式,我们尝试在这里打破lfnst>0的划分
if (curIspLfnstIdx > 0 && ispTestedModes.numTestedModes[nextISPcandSplitType - 1] == 1)
{
int firstModeThisSplit = ispTestedModes.getTestedIntraMode(nextISPcandSplitType, 0);
int numSubPartsFirstModeThisSplit = ispTestedModes.getNumCompletedSubParts(nextISPcandSplitType, firstModeThisSplit);
CHECK(numSubPartsFirstModeThisSplit < 0, "wrong number of subpartitions!");
bool stopThisSplit = false;
bool stopThisSplitAllLfnsts = false;
if (numSubPartsFirstModeThisSplit < maxNumSubPartitions)
{
stopThisSplit = true;
if (m_pcEncCfg->getUseFastISP() && curIspLfnstIdx == 1 && numSubPartsFirstModeThisSplit < maxNumSubPartitions - 1)
{
stopThisSplitAllLfnsts = true;
}
}
if (stopThisSplit)
{
ispTestedModes.splitIsFinished[nextISPcandSplitType - 1] = true;
if (curIspLfnstIdx == 1 && stopThisSplitAllLfnsts)
{
m_ispTestedModes[2].splitIsFinished[nextISPcandSplitType - 1] = true;
}
return;
}
}
// We try to break the split here for lfnst = 0 or all lfnst indices according to the first two modes
// 根据前两种模式,我们尝试在这里打破lfnst=0或所有lfnst索引的划分
if (curIspLfnstIdx == 0 && ispTestedModes.numTestedModes[nextISPcandSplitType - 1] == 2)
{
// Split stop criteria after checking the performance of previously tested intra modes
// 检查之前测试的帧内模式性能后的划分停止标准
const int thresholdSplit1 = maxNumSubPartitions;
bool stopThisSplit = false;
bool stopThisSplitForAllLFNSTs = false;
const int thresholdSplit1ForAllLFNSTs = maxNumSubPartitions - 1;
int mode1 = ispTestedModes.getTestedIntraMode((ISPType)nextISPcandSplitType, 0);
mode1 = mode1 == DC_IDX ? -1 : mode1;
int numSubPartsBestMode1 = mode1 != -1 ? ispTestedModes.getNumCompletedSubParts((ISPType)nextISPcandSplitType, mode1) : -1;
int mode2 = ispTestedModes.getTestedIntraMode((ISPType)nextISPcandSplitType, 1);
mode2 = mode2 == DC_IDX ? -1 : mode2;
int numSubPartsBestMode2 = mode2 != -1 ? ispTestedModes.getNumCompletedSubParts((ISPType)nextISPcandSplitType, mode2) : -1;
// 1) The 2 most promising modes do not reach a certain number of sub-partitions
// 1)最有前途的两种模式没有达到一定数量的子分区
if (numSubPartsBestMode1 != -1 && numSubPartsBestMode2 != -1)
{
if (numSubPartsBestMode1 < thresholdSplit1 && numSubPartsBestMode2 < thresholdSplit1)
{
stopThisSplit = true;
if (curIspLfnstIdx == 0 && numSubPartsBestMode1 < thresholdSplit1ForAllLFNSTs && numSubPartsBestMode2 < thresholdSplit1ForAllLFNSTs)
{
stopThisSplitForAllLFNSTs = true;
}
}
else
{
//we stop also if the cost is MAX_DOUBLE for both modes
//如果两种模式的成本都是MAX_DOUBLE,我们也会停止
double mode1Cost = ispTestedModes.getRDCost(nextISPcandSplitType, mode1);
double mode2Cost = ispTestedModes.getRDCost(nextISPcandSplitType, mode2);
if (!(mode1Cost < MAX_DOUBLE || mode2Cost < MAX_DOUBLE))
{
stopThisSplit = true;
}
}
}
if (!stopThisSplit)
{
// 2) One split type may be discarded by comparing the number of sub-partitions of the best angle modes of both splits
// 2)通过比较两个划分的最佳角度模式的子分区数,可以丢弃一个划分类型
ISPType otherSplit = nextISPcandSplitType == HOR_INTRA_SUBPARTITIONS ? VER_INTRA_SUBPARTITIONS : HOR_INTRA_SUBPARTITIONS;
int numSubPartsBestMode2OtherSplit = mode2 != -1 ? ispTestedModes.getNumCompletedSubParts(otherSplit, mode2) : -1;
if (numSubPartsBestMode2OtherSplit != -1 && numSubPartsBestMode2 != -1 && ispTestedModes.bestSplitSoFar != nextISPcandSplitType)
{
if (numSubPartsBestMode2OtherSplit > numSubPartsBestMode2)
{
stopThisSplit = true;
}
// both have the same number of subpartitions
// 两者都有相同数量的子部分
else if (numSubPartsBestMode2OtherSplit == numSubPartsBestMode2)
{
// both have the maximum number of subpartitions, so it compares RD costs to decide
// 两者都有最大数量的子划分,所以它比较RD Cost来决定
if (numSubPartsBestMode2OtherSplit == maxNumSubPartitions)
{
double rdCostBestMode2ThisSplit = ispTestedModes.getRDCost(nextISPcandSplitType, mode2);
double rdCostBestMode2OtherSplit = ispTestedModes.getRDCost(otherSplit, mode2);
double threshold = 1.3;
if (rdCostBestMode2ThisSplit == MAX_DOUBLE || rdCostBestMode2OtherSplit < rdCostBestMode2ThisSplit * threshold)
{
stopThisSplit = true;
}
}
else // none of them reached the maximum number of subpartitions with the best angle modes, so it compares the results with the the planar mode
{//它们都没有达到具有最佳角度模式的子分区的最大数目,所以它将结果和PLANAR模式进行了比较
int numSubPartsBestMode1OtherSplit = mode1 != -1 ? ispTestedModes.getNumCompletedSubParts(otherSplit, mode1) : -1;
if (numSubPartsBestMode1OtherSplit != -1 && numSubPartsBestMode1 != -1 && numSubPartsBestMode1OtherSplit > numSubPartsBestMode1)
{
stopThisSplit = true;
}
}
}
}
}
if (stopThisSplit) //如果停止这种划分
{
ispTestedModes.splitIsFinished[nextISPcandSplitType - 1] = true;
if (stopThisSplitForAllLFNSTs)
{
for (int lfnstIdx = 1; lfnstIdx < NUM_LFNST_NUM_PER_SET; lfnstIdx++)
{
m_ispTestedModes[lfnstIdx].splitIsFinished[nextISPcandSplitType - 1] = true;
}
}
return;
}
}
// Now a new mode is retrieved from the list and it has to be decided whether it should be tested or not
// 现在从列表中检索到一个新模式,必须决定是否应该测试它
if (ispTestedModes.candIndexInList[nextISPcandSplitType - 1] < rdModeLists[nextISPcandSplitType - 1]->size())
{
ModeInfo candidate = rdModeLists[nextISPcandSplitType - 1]->at(ispTestedModes.candIndexInList[nextISPcandSplitType - 1]);
ispTestedModes.candIndexInList[nextISPcandSplitType - 1]++;
// extra modes are only tested if ISP has won so far
// 只有当ISP目前为止赢了,才测试额外的模式
if (ispTestedModes.candIndexInList[nextISPcandSplitType - 1] > ispTestedModes.numOrigModesToTest)
{
if (ispTestedModes.bestSplitSoFar != candidate.ispMod || ispTestedModes.bestModeSoFar == PLANAR_IDX)
{
ispTestedModes.splitIsFinished[nextISPcandSplitType - 1] = true;
return;
}
}
bool testCandidate = true;
// we look for a reference mode that has already been tested within the window and decide to test the new one according to the reference mode costs
// 我们寻找一个已经在窗口中测试过的参考模式,并决定根据参考模式成本测试新的模式
if (maxNumSubPartitions > 2 && (curIspLfnstIdx > 0 || (candidate.modeId >= DC_IDX && ispTestedModes.numTestedModes[nextISPcandSplitType - 1] >= 2)))
{
int refLfnstIdx = -1;
const int angWindowSize = 5;
int numSubPartsLeftMode, numSubPartsRightMode, numSubPartsRefMode, leftIntraMode = -1, rightIntraMode = -1;
int windowSize = candidate.modeId > DC_IDX ? angWindowSize : 1;
int numSamples = cuSize.width << floorLog2(cuSize.height);
int numSubPartsLimit = numSamples >= 256 ? maxNumSubPartitions - 1 : 2;
xFindAlreadyTestedNearbyIntraModes(curIspLfnstIdx, (int)candidate.modeId, &refLfnstIdx, &leftIntraMode, &rightIntraMode, (ISPType)candidate.ispMod, windowSize);
if (refLfnstIdx != -1 && refLfnstIdx != curIspLfnstIdx)
{
CHECK(leftIntraMode != candidate.modeId || rightIntraMode != candidate.modeId, "wrong intra mode and lfnstIdx values!");
numSubPartsRefMode = m_ispTestedModes[refLfnstIdx].getNumCompletedSubParts((ISPType)candidate.ispMod, candidate.modeId);
CHECK(numSubPartsRefMode <= 0, "Wrong value of the number of subpartitions completed!");
}
else
{
numSubPartsLeftMode = leftIntraMode != -1 ? ispTestedModes.getNumCompletedSubParts((ISPType)candidate.ispMod, leftIntraMode) : -1;
numSubPartsRightMode = rightIntraMode != -1 ? ispTestedModes.getNumCompletedSubParts((ISPType)candidate.ispMod, rightIntraMode) : -1;
numSubPartsRefMode = std::max(numSubPartsLeftMode, numSubPartsRightMode);
}
if (numSubPartsRefMode > 0)
{
// The mode was found. Now we check the condition
testCandidate = numSubPartsRefMode > numSubPartsLimit;
}
}
if (testCandidate)
{
modeInfo = candidate;
}
}
else
{
//the end of the list was reached, so the split is invalidated
ispTestedModes.splitIsFinished[nextISPcandSplitType - 1] = true;
}
}
五、进行划分
在选择好ISP的划分模式(水平或垂直)和预测模式以后,就正式进入ISP的划分、预测、变换等等。这里ISP划分的入口函数是xIntraCodingLumaISP函数。
xIntraCodingLumaISP函数主要是对CU进行划分,并且对划分后的TU调用xIntraCodingTUBlock函数进行编码,计算所得失真、码率,从而计算RD Cost,最后再求出当前ISP模式的总的RD Cost。
bool IntraSearch::xIntraCodingLumaISP(CodingStructure& cs, Partitioner& partitioner, const double bestCostSoFar)
{
int subTuCounter = 0; //TU计数器
const CodingUnit& cu = *cs.getCU(partitioner.currArea().lumaPos(), partitioner.chType);
bool earlySkipISP = false;//提前跳过ISP
bool splitCbfLuma = false;
const PartSplit ispType = CU::getISPType(cu, COMPONENT_Y);//ISP划分类型
cs.cost = 0;
partitioner.splitCurrArea(ispType, cs);
CUCtx cuCtx;
cuCtx.isDQPCoded = true;
cuCtx.isChromaQpAdjCoded = true;
do // subpartitions loop ISP划分循环
{
uint32_t numSig = 0;
Distortion singleDistTmpLuma = 0;//失真
uint64_t singleTmpFracBits = 0;//码率
double singleCostTmp = 0;//RD Cost
// 获得划分后的TU
TransformUnit& tu = cs.addTU(CS::getArea(cs, partitioner.currArea(), partitioner.chType), partitioner.chType);
tu.depth = partitioner.currTrDepth;
// Encode TU
// 编码TU
xIntraCodingTUBlock(tu, COMPONENT_Y, false, singleDistTmpLuma, 0, &numSig);
if (singleDistTmpLuma == MAX_INT) // all zero CBF skip
{
earlySkipISP = true;
partitioner.exitCurrSplit();
cs.cost = MAX_DOUBLE;
return false;
}
{
if (m_pcRdCost->calcRdCost(cs.fracBits, cs.dist + singleDistTmpLuma) > bestCostSoFar)
{
// The accumulated cost + distortion is already larger than the best cost so far, so it is not necessary to calculate the rate
// 累计成本 + 失真已经大于目前为止的最佳成本,因此不必计算码率
earlySkipISP = true;
}
else
{
// 计算码率
singleTmpFracBits = xGetIntraFracBitsQT(cs, partitioner, true, false, subTuCounter, ispType, &cuCtx);
}
// 计算RD Cost
singleCostTmp = m_pcRdCost->calcRdCost(singleTmpFracBits, singleDistTmpLuma);
}
cs.cost += singleCostTmp; //计算总RD Cost
cs.dist += singleDistTmpLuma;//计算总失真
cs.fracBits += singleTmpFracBits;//计算总码率
subTuCounter++;//TU数目+1
splitCbfLuma |= TU::getCbfAtDepth(*cs.getTU(partitioner.currArea().lumaPos(), partitioner.chType, subTuCounter - 1), COMPONENT_Y, partitioner.currTrDepth);
int nSubPartitions = m_ispTestedModes[cu.lfnstIdx].numTotalParts[cu.ispMode - 1];
if (subTuCounter < nSubPartitions) //当前的TU数目小于分区总数目
{
// exit condition if the accumulated cost is already larger than the best cost so far (no impact in RD performance)
// 如果累计成本已经大于目前为止的最佳成本(对研发绩效没有影响),则退出条件
if (cs.cost > bestCostSoFar)
{
earlySkipISP = true;
break;
}
else if (subTuCounter < nSubPartitions)
{
// more restrictive exit condition
// 更严格的退出条件
double threshold = nSubPartitions == 2 ? 0.95 : subTuCounter == 1 ? 0.83 : 0.91;
if (subTuCounter < nSubPartitions && cs.cost > bestCostSoFar * threshold)
{
earlySkipISP = true;
break;
}
}
}
} while (partitioner.nextPart(cs)); // subpartitions loop
partitioner.exitCurrSplit();
const UnitArea& currArea = partitioner.currArea();
const uint32_t currDepth = partitioner.currTrDepth;
if (earlySkipISP)
{
cs.cost = MAX_DOUBLE;//如果提前退出ISP,则cost设置为MAXDOUBLE
}
else
{
cs.cost = m_pcRdCost->calcRdCost(cs.fracBits, cs.dist);
// The cost check is necessary here again to avoid superfluous operations if the maximum number of coded subpartitions was reached and yet ISP did not win
// 如果达到了最大编码子分区数,但ISP没有获胜,则必须再次进行成本检查,以避免多余的操作
if (cs.cost < bestCostSoFar)
{
cs.setDecomp(cu.Y());
cs.picture->getRecoBuf(currArea.Y()).copyFrom(cs.getRecoBuf(currArea.Y()));
for (auto& ptu : cs.tus)
{
if (currArea.Y().contains(ptu->Y()))
{
TU::setCbfAtDepth(*ptu, COMPONENT_Y, currDepth, splitCbfLuma ? 1 : 0);
}
}
}
else
{
earlySkipISP = true;
}
}
return !earlySkipISP;
}六、进行预测、变换
在O次会议中,采纳了O0106提案,该提案主要是根据CU的尺寸针对ISP垂直划分后的预测区域和变换区域尺寸进行限制,主要内容如下:
| Coding block 尺寸 (WxH) |
VTM-5.0 |
CE3-1.6 |
||
| 用于预测的分区尺寸 |
变换尺寸 |
用于预测的分区尺寸 |
变换尺寸 |
|
| 4x8 |
2x8 |
2x8 |
4x8 |
2x8 |
| 4xN (N > 8) |
1xN |
1xN |
4xN |
1xN |
| 8xN (N > 4) |
2xN |
2xN |
4xN |
2xN |
即如果垂直划分后的分区的尺寸为1xN、2xN,则其进行预测时候的分区尺寸修改为4xN,而进行变换时尺寸不变。
以4xN(N>8)和8xN(N>4)的编码块为例:

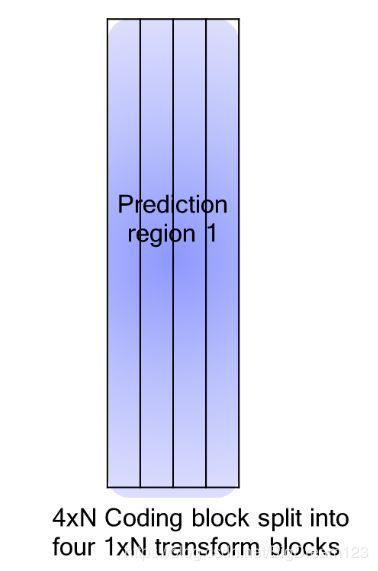
对于ISP编码的8xN(N>4)的编码块,进行垂直划分后,在4xN预测区域上进行预测,变换块(TB)大小为2xN;对于ISP编码的4xN编码块,进行垂直划分后,在4xN预测区进行预测,变换块大小为1xN。
这部分具体限制代码在xIntraCodingTUBlock函数中,ISP部分代码如下:
if (compID == COMPONENT_Y)
#else
if (compID == COMPONENT_Y || (isChroma(compID) && tu.cu->bdpcmModeChroma))
#endif
{
PelBuf sharedPredTS( m_pSharedPredTransformSkip[compID], area );
if( default0Save1Load2 != 2 )
{
bool predRegDiffFromTB = CU::isPredRegDiffFromTB(*tu.cu, compID);//预测尺寸和变换尺寸不一样
bool firstTBInPredReg = CU::isFirstTBInPredReg(*tu.cu, compID, area);//第一个进行预测的块
CompArea areaPredReg(COMPONENT_Y, tu.chromaFormat, area);//预测重建块
if (tu.cu->ispMode && isLuma(compID))
{
if (predRegDiffFromTB)
{ // 如果预测尺寸和TB不一样
if (firstTBInPredReg)
{ // 如果TB是第一次进行预测
CU::adjustPredArea(areaPredReg);//调整预测区域,将CU尺寸为4xN and 8xN (N > 4)的块的ISP预测区域改为4xN
initIntraPatternChTypeISP(*tu.cu, areaPredReg, piReco);
}
}
else
initIntraPatternChTypeISP(*tu.cu, area, piReco);
}
else
{
initIntraPatternChType(*tu.cu, area);
}
//===== get prediction signal =====
if(compID != COMPONENT_Y && !tu.cu->bdpcmModeChroma && PU::isLMCMode(uiChFinalMode))
{
{
xGetLumaRecPixels( pu, area );
}
predIntraChromaLM( compID, piPred, pu, area, uiChFinalMode );
}
else
{
if( PU::isMIP( pu, chType ) )
{
initIntraMip( pu, area );
predIntraMip( compID, piPred, pu );
}
else
{
if (predRegDiffFromTB)
{ //如果预测尺寸和TB不一样
if (firstTBInPredReg)
{ //如果TB是第一次进行预测
PelBuf piPredReg = cs.getPredBuf(areaPredReg);
predIntraAng(compID, piPredReg, pu);
}
}
else
predIntraAng(compID, piPred, pu);
}
}
// save prediction
if( default0Save1Load2 == 1 )
{
sharedPredTS.copyFrom( piPred );
}
}
else
{
// load prediction
piPred.copyFrom( sharedPredTS );
}
}initIntraPatternChTypeISP函数主要是获取ISP预测时候的参考像素以及对参考像素进行滤波。具体代码如下:
//初始化ISP的预测参数
void IntraPrediction::initIntraPatternChTypeISP(const CodingUnit& cu, const CompArea& area, PelBuf& recBuf, const bool forceRefFilterFlag)
{
const CodingStructure& cs = *cu.cs;
if (!forceRefFilterFlag)
{
initPredIntraParams(*cu.firstPU, area, *cs.sps);
}
const Position posLT = area;
bool isLeftAvail = (cs.getCURestricted(posLT.offset(-1, 0), cu, CHANNEL_TYPE_LUMA) != NULL) && cs.isDecomp(posLT.offset(-1, 0), CHANNEL_TYPE_LUMA);
bool isAboveAvail = (cs.getCURestricted(posLT.offset(0, -1), cu, CHANNEL_TYPE_LUMA) != NULL) && cs.isDecomp(posLT.offset(0, -1), CHANNEL_TYPE_LUMA);
// ----- Step 1: unfiltered reference samples -----
// ----- Step 1: 获取参考像素 -----
if (cu.blocks[area.compID].x == area.x && cu.blocks[area.compID].y == area.y) //第一个进行预测的TB
{
Pel *refBufUnfiltered = m_refBuffer[area.compID][PRED_BUF_UNFILTERED];
// With the first subpartition all the CU reference samples are fetched at once in a single call to xFillReferenceSamples
//在第一个子分区中,整个CU的所有参考像素在一次调用xFillReferenceSamples时被同时获取
if (cu.ispMode == HOR_INTRA_SUBPARTITIONS)
{
m_leftRefLength = cu.Y().height << 1;
m_topRefLength = cu.Y().width + area.width;
}
else //if (cu.ispMode == VER_INTRA_SUBPARTITIONS)
{
m_leftRefLength = cu.Y().height + area.height;
m_topRefLength = cu.Y().width << 1;
}
//获取参考像素
xFillReferenceSamples(cs.picture->getRecoBuf(cu.Y()), refBufUnfiltered, cu.Y(), cu);
// After having retrieved all the CU reference samples, the number of reference samples is now adjusted for the current subpartition
// 检索完所有CU的参考像素后,参考像素的数量现在根据当前的子分区进行调整
m_topRefLength = cu.blocks[area.compID].width + area.width;//上边的参考像素长度
m_leftRefLength = cu.blocks[area.compID].height + area.height;//左侧的参考像素长度
}
else
{
m_topRefLength = cu.blocks[area.compID].width + area.width;
m_leftRefLength = cu.blocks[area.compID].height + area.height;
const int predSizeHor = m_topRefLength;
const int predSizeVer = m_leftRefLength;
if (cu.ispMode == HOR_INTRA_SUBPARTITIONS) //水平划分
{
Pel* src = recBuf.bufAt(0, -1);
Pel *ref = m_refBuffer[area.compID][PRED_BUF_UNFILTERED] + m_refBufferStride[area.compID];
if (isLeftAvail)
{
for (int i = 0; i <= 2 * cu.blocks[area.compID].height - area.height; i++)
{
ref[i] = ref[i + area.height];
}
}
else
{
for (int i = 0; i <= predSizeVer; i++)
{
ref[i] = src[0];
}
}
Pel *dst = m_refBuffer[area.compID][PRED_BUF_UNFILTERED] + 1;
dst[-1] = ref[0];
for (int i = 0; i < area.width; i++)
{
dst[i] = src[i];
}
Pel sample = src[area.width - 1];
dst += area.width;
for (int i = 0; i < predSizeHor - area.width; i++)
{
dst[i] = sample;
}
}
else
{
Pel* src = recBuf.bufAt(-1, 0);
Pel *ref = m_refBuffer[area.compID][PRED_BUF_UNFILTERED];
if (isAboveAvail)
{
for (int i = 0; i <= 2 * cu.blocks[area.compID].width - area.width; i++)
{
ref[i] = ref[i + area.width];
}
}
else
{
for (int i = 0; i <= predSizeHor; i++)
{
ref[i] = src[0];
}
}
Pel *dst = m_refBuffer[area.compID][PRED_BUF_UNFILTERED] + m_refBufferStride[area.compID] + 1;
dst[-1] = ref[0];
for (int i = 0; i < area.height; i++)
{
*dst = *src;
src += recBuf.stride;
dst++;
}
Pel sample = src[-recBuf.stride];
for (int i = 0; i < predSizeVer - area.height; i++)
{
*dst = sample;
dst++;
}
}
}
// ----- Step 2: filtered reference samples -----
// ----- Step 2: 对参考像素进行滤波 -----
if (m_ipaParam.refFilterFlag || forceRefFilterFlag)
{
Pel *refBufUnfiltered = m_refBuffer[area.compID][PRED_BUF_UNFILTERED];
Pel *refBufFiltered = m_refBuffer[area.compID][PRED_BUF_FILTERED];
xFilterReferenceSamples(refBufUnfiltered, refBufFiltered, area, *cs.sps, cu.firstPU->multiRefIdx);
}
}