H.266/VVC代码学习:普通量化和率失真优化量化(RDOQ)
H.266/VVC中,使用了普通标量量化、率失真优化量化(RDOQ)和依赖性量化(DQ)。
1.普通标量量化
标量量化公式如下:
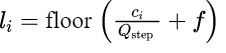
其中, 表示DCT系数,
表示DCT系数,![]() 表示量化步长,f 控制舍入关系,
表示量化步长,f 控制舍入关系,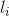 为量化后的值,floor()为向下取整函数。
为量化后的值,floor()为向下取整函数。
量化步长由量化参数QP决定:
![]()
从上式可以看出,QP每增加6,![]() 就增加一倍。在量化过程中还要完成整数DCT过程的比例缩放运算,为了使量化中除法变为移位运算,将
就增加一倍。在量化过程中还要完成整数DCT过程的比例缩放运算,为了使量化中除法变为移位运算,将![]() 扩大
扩大![]() 倍获得新的变量MF,其中,
倍获得新的变量MF,其中,![]()

其中%表示取余数,可以看出,MF仅有6个值,考虑到整数DCT的缩放因子 可以表示为2的整数次幂形式:
可以表示为2的整数次幂形式:![]() ,则量化公式可以写成:
,则量化公式可以写成:
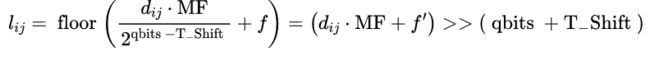
其中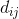 表示缩放前的DCT系数,
表示缩放前的DCT系数,![]() 表示舍入偏移量
表示舍入偏移量
考虑到量化结果的符号后,完整的量化公式为:
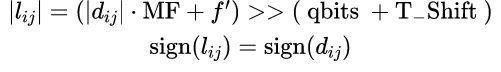
H.266/VVC中的普通量化函数代码如下:
//普通量化
void Quant::quant(TransformUnit &tu, const ComponentID &compID, const CCoeffBuf &pSrc, TCoeff &uiAbsSum, const QpParam &cQP, const Ctx& ctx)
{
const SPS &sps = *tu.cs->sps;
const CompArea &rect = tu.blocks[compID];
const uint32_t uiWidth = rect.width;
const uint32_t uiHeight = rect.height;
const int channelBitDepth = sps.getBitDepth(toChannelType(compID));
const CCoeffBuf &piCoef = pSrc;//变换系数
CoeffBuf piQCoef = tu.getCoeffs(compID);//量化后系数
const bool useTransformSkip = (tu.mtsIdx[compID] == MTS_SKIP);
const int maxLog2TrDynamicRange = sps.getMaxLog2TrDynamicRange(toChannelType(compID));
{
CoeffCodingContext cctx(tu, compID, tu.cs->picHeader->getSignDataHidingEnabledFlag());
const TCoeff entropyCodingMinimum = -(1 << maxLog2TrDynamicRange);//熵编码最小值
const TCoeff entropyCodingMaximum = (1 << maxLog2TrDynamicRange) - 1;//熵编码最大值
TCoeff deltaU[MAX_TB_SIZEY * MAX_TB_SIZEY];
int scalingListType = getScalingListType(tu.cu->predMode, compID);
CHECK(scalingListType >= SCALING_LIST_NUM, "Invalid scaling list");
const uint32_t uiLog2TrWidth = floorLog2(uiWidth);
const uint32_t uiLog2TrHeight = floorLog2(uiHeight);
//根据缩放类型获取量化系数矩阵
int *piQuantCoeff = getQuantCoeff(scalingListType, cQP.rem(useTransformSkip), uiLog2TrWidth, uiLog2TrHeight);
const bool disableSMForLFNST = tu.cs->picHeader->getScalingListPresentFlag() ? tu.cs->picHeader->getScalingListAPS()->getScalingList().getDisableScalingMatrixForLfnstBlks() : false;
#if JVET_Q0784_LFNST_COMBINATION
const bool isLfnstApplied = tu.cu->lfnstIdx > 0 && (tu.cu->isSepTree() ? true : isLuma(compID));
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, useTransformSkip, isLfnstApplied, disableSMForLFNST);
#else
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, useTransformSkip, tu.cu->lfnstIdx > 0, disableSMForLFNST);
#endif
// for blocks that where width*height != 4^N, the effective scaling applied during transformation cannot be
// compensated by a bit-shift (the quantised result will be sqrt(2) * larger than required).
// The quantScale table and shift is used to compensate for this.
// 对于widhth*height!=4^N的块,变换期间应用的有效缩放无法通过位偏移进行补偿(量化结果将为sqrt(2)*大于所需值)。
// quantScale表和shift用于对此进行补偿。
const bool needSqrtAdjustment= TU::needsBlockSizeTrafoScale( tu, compID );
//获取默认量化系数 MF值
//cQP.per表示floor(QP/6)的值
//cQP.rem表示QP%6的值
const int defaultQuantisationCoefficient = g_quantScales[needSqrtAdjustment?1:0][cQP.rem(useTransformSkip)];
//iTranformShift表示整数DCT变换的缩放因子,该因子和变换尺寸有关
int iTransformShift = getTransformShift(channelBitDepth, rect.size(), maxLog2TrDynamicRange) + ( needSqrtAdjustment?-1:0);
if (useTransformSkip && sps.getSpsRangeExtension().getExtendedPrecisionProcessingFlag())
{
iTransformShift = std::max(0, iTransformShift);
}
//计算qbit,QUANT_SHIFT =14,cQP.per=floor(QP/6),qbit=14+floor(QP/6)
//如果使用的不是变换跳过模式,则再加上DCT系数的缩放因子
const int iQBits = QUANT_SHIFT + cQP.per(useTransformSkip) + (useTransformSkip ? 0 : iTransformShift);
// QBits will be OK for any internal bit depth as the reduction in transform shift is balanced by an increase in Qp_per due to QpBDOffset
// 对于任何内部位深度,QBits都是可以的,因为变换移位的减少通过QpBDOffset引起的Qp_per的增加来平衡
// 计算f'=f<<(qbit+T)
const int64_t iAdd = int64_t(tu.cs->slice->isIRAP() ? 171 : 85) << int64_t(iQBits - 9);
const int qBits8 = iQBits - 8;
const uint32_t lfnstIdx = tu.cu->lfnstIdx;
//最大系数数目
const int maxNumberOfCoeffs = lfnstIdx > 0 ? ((( uiWidth == 4 && uiHeight == 4 ) || ( uiWidth == 8 && uiHeight == 8) ) ? 8 : 16) : piQCoef.area();
memset( piQCoef.buf, 0, sizeof(TCoeff) * piQCoef.area() );
//遍历块内的所有系数,分别对其进行量化
for (int uiBlockPos = 0; uiBlockPos < maxNumberOfCoeffs; uiBlockPos++ )
{
const TCoeff iLevel = piCoef.buf[uiBlockPos];//变换系数d
const TCoeff iSign = (iLevel < 0 ? -1: 1);//变换系数符号
//enableScalingLists 表示是否同时完成DCT变换中的伸缩因子的乘法运算
//表示缩放前的变换系数d * MF
const int64_t tmpLevel = (int64_t)abs(iLevel) * (enableScalingLists ? piQuantCoeff[uiBlockPos] : defaultQuantisationCoefficient);
//根据量化公式得到量化后系数的幅度值(即绝对值)
const TCoeff quantisedMagnitude = TCoeff((tmpLevel + iAdd ) >> iQBits);
deltaU[uiBlockPos] = (TCoeff)((tmpLevel - ((int64_t)quantisedMagnitude<> qBits8);
uiAbsSum += quantisedMagnitude;
const TCoeff quantisedCoefficient = quantisedMagnitude * iSign;//最终的量化系数
piQCoef.buf[uiBlockPos] = Clip3( entropyCodingMinimum, entropyCodingMaximum, quantisedCoefficient );
} // for n
if ((tu.cu->bdpcmMode && isLuma(compID)) || (tu.cu->bdpcmModeChroma && isChroma(compID)) )
{
fwdResDPCM( tu, compID );
}
if( cctx.signHiding() )
{
//这就防止了只有一个系数值为1的TUs被测试
if(uiAbsSum >= 2) //this prevents TUs with only one coefficient of value 1 from being tested
{
//只为了最小化失真,不考虑比特率。
xSignBitHidingHDQ(piQCoef.buf, piCoef.buf, deltaU, cctx, maxLog2TrDynamicRange);
}
}
} //if RDOQ
//return;
}
这里,对于当变换块不是4的幂次时,在处理变换系数的同时修改QP或QP levelScale table而不是乘以√2(181/256或181/128)以补偿变换过程中的隐式缩放。
| QP%6 | 0 | 1 | 2 | 3 | 4 | 5 | |
| Qscale | Normal blocks | 26214 | 23302 | 20560 | 18396 | 16384 | 14564 |
| invQscale | 40 | 45 | 51 | 57 | 64 | 72 | |
| Qscale | Compensating blocks | 18396 | 16384 | 14564 | 13107 | 11651 | 10280 |
| invQscale | 57 | 64 | 72 | 80 | 90 | 102 |
2.率失真优化量化(RDOQ)
传统的量化是以失真为最小目的进行设计的。在视频编码中, 编码比特率同样是一种影响编码性能的因素,因此视频编码中的量化器设计需要权衡失真与比特率。率失真优化量化RDOQ即这种量化器,该方法将量化过程与率失真优化准则相结合,对于一个变换系数 ,给定多个可选的量化值
,给定多个可选的量化值![]() 、
、![]() ···
···![]() ,并用RDO准则选出最优的量化值,计算如下:
,并用RDO准则选出最优的量化值,计算如下:
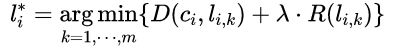
其中,![]() 为量化为
为量化为![]() 时的失真,
时的失真,![]() 表示量化为
表示量化为![]() 时所需的编码比特数,
时所需的编码比特数, 为拉格朗日因子,
为拉格朗日因子,![]() 为最优的量化值
为最优的量化值
H.266/VVC在使用RDOQ量化之前,需要对其进行判断是否需要进行RDOQ:遍历编码块内系数,并对其进行普通量化,如果量化后的系数不为零则表示需要使用RDOQ量化,退出循环;否则,继续遍历。
bool Quant::xNeedRDOQ(TransformUnit &tu, const ComponentID &compID, const CCoeffBuf &pSrc, const QpParam &cQP)
{
const SPS &sps = *tu.cs->sps;
const CompArea &rect = tu.blocks[compID];
const uint32_t uiWidth = rect.width;
const uint32_t uiHeight = rect.height;
const int channelBitDepth = sps.getBitDepth(toChannelType(compID));
const CCoeffBuf piCoef = pSrc;
const bool useTransformSkip = (tu.mtsIdx[compID] == MTS_SKIP);
const int maxLog2TrDynamicRange = sps.getMaxLog2TrDynamicRange(toChannelType(compID));
int scalingListType = getScalingListType(tu.cu->predMode, compID);
CHECK(scalingListType >= SCALING_LIST_NUM, "Invalid scaling list");
const uint32_t uiLog2TrWidth = floorLog2(uiWidth);
const uint32_t uiLog2TrHeight = floorLog2(uiHeight);
int *piQuantCoeff = getQuantCoeff(scalingListType, cQP.rem(useTransformSkip), uiLog2TrWidth, uiLog2TrHeight);
const bool disableSMForLFNST = tu.cs->picHeader->getScalingListPresentFlag() ? tu.cs->picHeader->getScalingListAPS()->getScalingList().getDisableScalingMatrixForLfnstBlks() : false;
#if JVET_Q0784_LFNST_COMBINATION
const bool isLfnstApplied = tu.cu->lfnstIdx > 0 && (tu.cu->isSepTree() ? true : isLuma(compID));
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, (useTransformSkip != 0), isLfnstApplied, disableSMForLFNST);
#else
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, (useTransformSkip != 0), tu.cu->lfnstIdx > 0, disableSMForLFNST);
#endif
/* for 422 chroma blocks, the effective scaling applied during transformation is not a power of 2, hence it cannot be
* implemented as a bit-shift (the quantised result will be sqrt(2) * larger than required). Alternatively, adjust the
* uiLog2TrSize applied in iTransformShift, such that the result is 1/sqrt(2) the required result (i.e. smaller)
* Then a QP+3 (sqrt(2)) or QP-3 (1/sqrt(2)) method could be used to get the required result
*/
const bool needSqrtAdjustment= TU::needsBlockSizeTrafoScale( tu, compID );
const int defaultQuantisationCoefficient = g_quantScales[needSqrtAdjustment?1:0][cQP.rem(useTransformSkip)];
int iTransformShift = getTransformShift(channelBitDepth, rect.size(), maxLog2TrDynamicRange) + (needSqrtAdjustment?-1:0);
if (useTransformSkip && sps.getSpsRangeExtension().getExtendedPrecisionProcessingFlag())
{
iTransformShift = std::max(0, iTransformShift);
}
const int iQBits = QUANT_SHIFT + cQP.per(useTransformSkip) + iTransformShift;
assert(iQBits>=0);
// QBits will be OK for any internal bit depth as the reduction in transform shift is balanced by an increase in Qp_per due to QpBDOffset
// iAdd is different from the iAdd used in normal quantization
const int64_t iAdd = int64_t(compID == COMPONENT_Y ? 171 : 256) << (iQBits - 9);
for (int uiBlockPos = 0; uiBlockPos < rect.area(); uiBlockPos++)
{
const TCoeff iLevel = piCoef.buf[uiBlockPos];
const int64_t tmpLevel = (int64_t)abs(iLevel) * (enableScalingLists ? piQuantCoeff[uiBlockPos] : defaultQuantisationCoefficient);
const TCoeff quantisedMagnitude = TCoeff((tmpLevel + iAdd ) >> iQBits);
if (quantisedMagnitude != 0)
{
return true;
}
} // for n
return false;
} H.266/VVC使用RDOQ量化时,分为两种情况,一种是TransformSkip时,调用xRateDistOptQuantTS函数进行RDOQ量化;另一种是其余情况,调用xRateDistOptQuant函数进行RDOQ量化。
H.266/VVC的RDOQ过程和H.265/HEVC的RDOQ过程基本相同,这里以H.265/HEVC为例介绍RDOQ过程:
(1)确定当前TU每个系数的可选量化值,用下式对当前TU所有系数进行预量化:
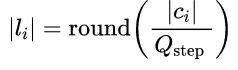
其中 round(·)表示四舍五入。利用![]() 的大小确定可选量化值,可选量化值的选择如下:(
的大小确定可选量化值,可选量化值的选择如下:(![]() > 1 ?
> 1 ? ![]() - 1: 1 );
- 1: 1 );
(2)利用RDO准则确定当前TU的所有系数的最优量化值。对于每一个系数,遍历其可选量化值,利用RDO准则确定每个系数的最优量化值(xGetCodedLevel函数)。
(3)利用RDO准则确定当前TU的每一个系数块组(CG)是否量化为全零组。该步骤按照CG扫描顺序遍历当前TU内的所有CG,分别计算其量化为全零CG的率失真代价,并与原率失真代价比较,从而决定是否将其量化为全零CG。这么做的原因:H.265/HEVC在对一个TU进行熵编码时,会将其分成若干4x4系数块组(H.266/VVC也会将TU分成若干系数块组,但系数块组的尺寸由TU尺寸决定),每个CG都含有一个比特位用于标识其是否全零CG。若当前CG为全零CG,只需要编码全零标识即可;反之,则需编码非零标识以及当前CG内的所有系数。因此,若当前CG仅含有极少个数且幅值较小的非零系数时,将其量化为全零CG可能会获得更好的编码性能。
(4)利用RDO准则确定当前TU的“最后一个非零系数”的位置(这部分代码没有看懂在干嘛,就不按照H.265/HEVC的过程写了...)。
xRateDistOptQuant函数具体代码和注释如下(xRateDistOptQuantTS函数过程基本相似,且更简单,就不放代码了):
void QuantRDOQ::xRateDistOptQuant(TransformUnit &tu, const ComponentID &compID, const CCoeffBuf &pSrc, TCoeff &uiAbsSum, const QpParam &cQP, const Ctx &ctx)
{
const FracBitsAccess& fracBits = ctx.getFracBitsAcess();
const SPS &sps = *tu.cs->sps;
const CompArea &rect = tu.blocks[compID];
const uint32_t uiWidth = rect.width;
const uint32_t uiHeight = rect.height;
const ChannelType chType = toChannelType(compID);
const int channelBitDepth = sps.getBitDepth( chType );
const bool extendedPrecision = sps.getSpsRangeExtension().getExtendedPrecisionProcessingFlag();
const int maxLog2TrDynamicRange = sps.getMaxLog2TrDynamicRange(chType);
const bool useIntraSubPartitions = tu.cu->ispMode && isLuma(compID); //ISP使用标志
/* for 422 chroma blocks, the effective scaling applied during transformation is not a power of 2, hence it cannot be
* implemented as a bit-shift (the quantised result will be sqrt(2) * larger than required). Alternatively, adjust the
* uiLog2TrSize applied in iTransformShift, such that the result is 1/sqrt(2) the required result (i.e. smaller)
* Then a QP+3 (sqrt(2)) or QP-3 (1/sqrt(2)) method could be used to get the required result
*/
/* 对于4:2:2类型的色度块,在变换期间应用的有效缩放不是2的幂,因此它不能被实现为比特移位(量化结果将是sqrt(2)*大于所需值)
* 或者,调整iTransformShift中应用的uiLog2TrSize,使结果为所需结果(即更小)的1/sqrt(2)
* 然后用QP+3(sqrt(2))或QP-3(1/sqrt(2))方法得到所需的结果。
*/
// Represents scaling through forward transform
int iTransformShift = getTransformShift(channelBitDepth, rect.size(), maxLog2TrDynamicRange);
if (tu.mtsIdx[compID] == MTS_SKIP && extendedPrecision)
{
iTransformShift = std::max(0, iTransformShift);
}
double d64BlockUncodedCost = 0;
const uint32_t uiLog2BlockWidth = floorLog2(uiWidth);
const uint32_t uiLog2BlockHeight = floorLog2(uiHeight);
const uint32_t uiMaxNumCoeff = rect.area();//TU的系数数目
CHECK(compID >= MAX_NUM_TBLOCKS, "Invalid component ID");
int scalingListType = getScalingListType(tu.cu->predMode, compID);
CHECK(scalingListType >= SCALING_LIST_NUM, "Invalid scaling list");
const TCoeff *plSrcCoeff = pSrc.buf;//量化前系数
TCoeff *piDstCoeff = tu.getCoeffs(compID).buf;//TU的系数
double *pdCostCoeff = m_pdCostCoeff;//编码量化系数的RD Cost
double *pdCostSig = m_pdCostSig;//编码符号的RD Cost
double *pdCostCoeff0 = m_pdCostCoeff0;//编码量化系数为0的RD Cost
int *rateIncUp = m_rateIncUp;
int *rateIncDown = m_rateIncDown;
int *sigRateDelta = m_sigRateDelta;
TCoeff *deltaU = m_deltaU;
memset(piDstCoeff, 0, sizeof(*piDstCoeff) * uiMaxNumCoeff);
memset( m_pdCostCoeff, 0, sizeof( double ) * uiMaxNumCoeff );
memset( m_pdCostSig, 0, sizeof( double ) * uiMaxNumCoeff );
memset( m_rateIncUp, 0, sizeof( int ) * uiMaxNumCoeff );
memset( m_rateIncDown, 0, sizeof( int ) * uiMaxNumCoeff );
memset( m_sigRateDelta, 0, sizeof( int ) * uiMaxNumCoeff );
memset( m_deltaU, 0, sizeof( TCoeff ) * uiMaxNumCoeff );
const bool needSqrtAdjustment= TU::needsBlockSizeTrafoScale( tu, compID );
const bool isTransformSkip = (tu.mtsIdx[compID] == MTS_SKIP);
// 得到误差标度系数
const double *const pdErrScale = xGetErrScaleCoeffSL(scalingListType, uiLog2BlockWidth, uiLog2BlockHeight, cQP.rem(isTransformSkip));
// 获取量化系数矩阵
const int *const piQCoef = getQuantCoeff(scalingListType, cQP.rem(isTransformSkip), uiLog2BlockWidth, uiLog2BlockHeight);
const bool disableSMForLFNST = tu.cs->picHeader->getScalingListPresentFlag() ? tu.cs->picHeader->getScalingListAPS()->getScalingList().getDisableScalingMatrixForLfnstBlks() : false;
#if JVET_Q0784_LFNST_COMBINATION
const bool isLfnstApplied = tu.cu->lfnstIdx > 0 && (tu.cu->isSepTree() ? true : isLuma(compID));
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, isTransformSkip, isLfnstApplied, disableSMForLFNST);
#else
const bool enableScalingLists = getUseScalingList(uiWidth, uiHeight, isTransformSkip, tu.cu->lfnstIdx > 0, disableSMForLFNST);
#endif
// 默认量化系数 MF
const int defaultQuantisationCoefficient = g_quantScales[ needSqrtAdjustment ?1:0][cQP.rem(isTransformSkip)];
// 默认误差标度系数
const double defaultErrorScale = xGetErrScaleCoeffNoScalingList(scalingListType, uiLog2BlockWidth, uiLog2BlockHeight, cQP.rem(isTransformSkip));
// 非RDOQ量化器的右移 qbit = 14 + floor(Qp/6) + T_shift
const int iQBits = QUANT_SHIFT + cQP.per(isTransformSkip) + iTransformShift + (needSqrtAdjustment?-1:0); // Right shift of non-RDOQ quantizer; level = (coeff*uiQ + offset)>>q_bits
const TCoeff entropyCodingMinimum = -(1 << maxLog2TrDynamicRange);//熵编码最小值
const TCoeff entropyCodingMaximum = (1 << maxLog2TrDynamicRange) - 1;//熵编码最大值
CoeffCodingContext cctx(tu, compID, tu.cs->picHeader->getSignDataHidingEnabledFlag());//变换系数编码的上下文模型
const int iCGSizeM1 = (1 << cctx.log2CGSize()) - 1;//系数块组最大位置
int iCGLastScanPos = -1;//系数块组最后系数位置
double d64BaseCost = 0;
int iLastScanPos = -1;
int ctxBinSampleRatio = (compID == COMPONENT_Y) ? MAX_TU_LEVEL_CTX_CODED_BIN_CONSTRAINT_LUMA : MAX_TU_LEVEL_CTX_CODED_BIN_CONSTRAINT_CHROMA;
int remRegBins = (uiWidth * uiHeight * ctxBinSampleRatio) >> 4;
uint32_t goRiceParam = 0;
double *pdCostCoeffGroupSig = m_pdCostCoeffGroupSig;
memset( pdCostCoeffGroupSig, 0, ( uiMaxNumCoeff >> cctx.log2CGSize() ) * sizeof( double ) );
int iScanPos;//当前系数扫描位置
coeffGroupRDStats rdStats;
#if ENABLE_TRACING
DTRACE( g_trace_ctx, D_RDOQ, "%d: %3d, %3d, %dx%d, comp=%d\n", DTRACE_GET_COUNTER( g_trace_ctx, D_RDOQ ), rect.x, rect.y, rect.width, rect.height, compID );
#endif
const uint32_t lfnstIdx = tu.cu->lfnstIdx;
//系数块组数目
//如果使用了LFNST则仅左上角一个4x4系数块组存在非零系数
const int iCGNum = lfnstIdx > 0 ? 1 : std::min(JVET_C0024_ZERO_OUT_TH, uiWidth) * std::min(JVET_C0024_ZERO_OUT_TH, uiHeight) >> cctx.log2CGSize();
//从后向前遍历当前所有系数块组CG
for (int subSetId = iCGNum - 1; subSetId >= 0; subSetId--)
{
cctx.initSubblock( subSetId );
uint32_t maxNonZeroPosInCG = iCGSizeM1;//CG组中最后非零系数位置
if( lfnstIdx > 0 && ( ( uiWidth == 4 && uiHeight == 4 ) || ( uiWidth == 8 && uiHeight == 8 && cctx.cgPosX() == 0 && cctx.cgPosY() == 0 ) ) )
{//使用LFNST且当前块为4x4或8x8时,最多仅存在8个非零系数
maxNonZeroPosInCG = 7;
}
memset( &rdStats, 0, sizeof (coeffGroupRDStats));
//从后向前当前系数块组CG内所有零系数的位置,并将相应位置的系数填充0
for( int iScanPosinCG = iCGSizeM1; iScanPosinCG > maxNonZeroPosInCG; iScanPosinCG-- )
{
iScanPos = cctx.minSubPos() + iScanPosinCG;
uint32_t blkPos = cctx.blockPos( iScanPos );
piDstCoeff[ blkPos ] = 0;
}
//从后向前遍历当前系数块组CG中的所有非零系数
for( int iScanPosinCG = maxNonZeroPosInCG; iScanPosinCG >= 0; iScanPosinCG-- )
{
iScanPos = cctx.minSubPos() + iScanPosinCG;
//===== quantization =====
//===== 量化 =====
uint32_t uiBlkPos = cctx.blockPos(iScanPos);
// set coeff 设置量化系数
const int quantisationCoefficient = (enableScalingLists) ? piQCoef [uiBlkPos] : defaultQuantisationCoefficient;
const double errorScale = (enableScalingLists) ? pdErrScale[uiBlkPos] : defaultErrorScale;
const int64_t tmpLevel = int64_t(abs(plSrcCoeff[ uiBlkPos ])) * quantisationCoefficient;
const Intermediate_Int lLevelDouble = (Intermediate_Int)std::min(tmpLevel, std::numeric_limits::max() - (Intermediate_Int(1) << (iQBits - 1)));
//获得预量化后的结果
uint32_t uiMaxAbsLevel = std::min(uint32_t(entropyCodingMaximum), uint32_t((lLevelDouble + (Intermediate_Int(1) << (iQBits - 1))) >> iQBits));
const double dErr = double( lLevelDouble );
pdCostCoeff0[ iScanPos ] = dErr * dErr * errorScale;//系数为零时的RD Cost
d64BlockUncodedCost += pdCostCoeff0[ iScanPos ];
piDstCoeff[ uiBlkPos ] = uiMaxAbsLevel;//设置TU当前位置的量化后的系数
if ( uiMaxAbsLevel > 0 && iLastScanPos < 0 )
{
iLastScanPos = iScanPos;
iCGLastScanPos = cctx.subSetId();
}
if ( iLastScanPos >= 0 )
{
#if ENABLE_TRACING
uint32_t uiCGPosY = cctx.cgPosX();
uint32_t uiCGPosX = cctx.cgPosY();
uint32_t uiPosY = cctx.posY( iScanPos );
uint32_t uiPosX = cctx.posX( iScanPos );
DTRACE( g_trace_ctx, D_RDOQ, "%d [%d][%d][%2d:%2d][%2d:%2d]", DTRACE_GET_COUNTER( g_trace_ctx, D_RDOQ ), iScanPos, uiBlkPos, uiCGPosX, uiCGPosY, uiPosX, uiPosY );
#endif
//===== coefficient level estimation =====
//===== 系数级估算(利用RDO准则计算率失真代价) =======
unsigned ctxIdSig = 0;
if( iScanPos != iLastScanPos )
{
ctxIdSig = cctx.sigCtxIdAbs( iScanPos, piDstCoeff, 0 );
}
uint32_t uiLevel;
uint8_t ctxOffset = cctx.ctxOffsetAbs ();
uint32_t uiParCtx = cctx.parityCtxIdAbs ( ctxOffset );
uint32_t uiGt1Ctx = cctx.greater1CtxIdAbs ( ctxOffset );
uint32_t uiGt2Ctx = cctx.greater2CtxIdAbs ( ctxOffset );
uint32_t goRiceZero = 0;
if( remRegBins < 4 )
{
unsigned sumAbs = cctx.templateAbsSum( iScanPos, piDstCoeff, 0 );
goRiceParam = g_auiGoRiceParsCoeff [ sumAbs ];
goRiceZero = g_auiGoRicePosCoeff0(0, goRiceParam);
}
const BinFracBits fracBitsPar = fracBits.getFracBitsArray( uiParCtx );
const BinFracBits fracBitsGt1 = fracBits.getFracBitsArray( uiGt1Ctx );
const BinFracBits fracBitsGt2 = fracBits.getFracBitsArray( uiGt2Ctx );
if( iScanPos == iLastScanPos )
{
//通过RDO确定最佳量化值
uiLevel = xGetCodedLevel( pdCostCoeff[ iScanPos ], pdCostCoeff0[ iScanPos ], pdCostSig[ iScanPos ],
lLevelDouble, uiMaxAbsLevel, nullptr, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, iQBits, errorScale, 1, extendedPrecision, maxLog2TrDynamicRange );
}
else
{
DTRACE_COND( ( uiMaxAbsLevel != 0 ), g_trace_ctx, D_RDOQ_MORE, " uiCtxSig=%d", ctxIdSig );
const BinFracBits fracBitsSig = fracBits.getFracBitsArray( ctxIdSig );
//通过RDO确定最佳量化值
uiLevel = xGetCodedLevel( pdCostCoeff[ iScanPos ], pdCostCoeff0[ iScanPos ], pdCostSig[ iScanPos ],
lLevelDouble, uiMaxAbsLevel, &fracBitsSig, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, iQBits, errorScale, 0, extendedPrecision, maxLog2TrDynamicRange );
sigRateDelta[ uiBlkPos ] = ( remRegBins < 4 ? 0 : fracBitsSig.intBits[1] - fracBitsSig.intBits[0] );
}
DTRACE( g_trace_ctx, D_RDOQ, " Lev=%d \n", uiLevel );
DTRACE_COND( ( uiMaxAbsLevel != 0 ), g_trace_ctx, D_RDOQ, " CostC0=%d\n", (int64_t)( pdCostCoeff0[iScanPos] ) );
DTRACE_COND( ( uiMaxAbsLevel != 0 ), g_trace_ctx, D_RDOQ, " CostC =%d\n", (int64_t)( pdCostCoeff[iScanPos] ) );
deltaU[ uiBlkPos ] = TCoeff((lLevelDouble - (Intermediate_Int(uiLevel) << iQBits)) >> (iQBits-8));
if( uiLevel > 0 )
{
int rateNow = xGetICRate( uiLevel, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, extendedPrecision, maxLog2TrDynamicRange );
rateIncUp [ uiBlkPos ] = xGetICRate( uiLevel+1, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, extendedPrecision, maxLog2TrDynamicRange ) - rateNow;
rateIncDown [ uiBlkPos ] = xGetICRate( uiLevel-1, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, extendedPrecision, maxLog2TrDynamicRange ) - rateNow;
}
else // uiLevel == 0
{
if( remRegBins < 4 )
{
int rateNow = xGetICRate( uiLevel, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, extendedPrecision, maxLog2TrDynamicRange );
rateIncUp [ uiBlkPos ] = xGetICRate( uiLevel+1, fracBitsPar, fracBitsGt1, fracBitsGt2, remRegBins, goRiceZero, goRiceParam, extendedPrecision, maxLog2TrDynamicRange ) - rateNow;
}
else
{
rateIncUp [ uiBlkPos ] = fracBitsGt1.intBits[ 0 ];
}
}
piDstCoeff[ uiBlkPos ] = uiLevel;//将当前位置的TU系数设置为最佳量化系数
d64BaseCost += pdCostCoeff [ iScanPos ];
if( ( (iScanPos & iCGSizeM1) == 0 ) && ( iScanPos > 0 ) )
{
goRiceParam = 0;
}
else if( remRegBins >= 4 )
{
int sumAll = cctx.templateAbsSum(iScanPos, piDstCoeff, 4);
goRiceParam = g_auiGoRiceParsCoeff[sumAll];
remRegBins -= (uiLevel < 2 ? uiLevel : 3) + (iScanPos != iLastScanPos);
}
}//if( iLastScanPos >= 0 )
else
{
d64BaseCost += pdCostCoeff0[ iScanPos ];
}
rdStats.d64SigCost += pdCostSig[ iScanPos ];
if (iScanPosinCG == 0 )
{//扫描到CG的第一个系数
rdStats.d64SigCost_0 = pdCostSig[ iScanPos ];
}
if (piDstCoeff[ uiBlkPos ] )
{
cctx.setSigGroup();
rdStats.d64CodedLevelandDist += pdCostCoeff[ iScanPos ] - pdCostSig[ iScanPos ];
rdStats.d64UncodedDist += pdCostCoeff0[ iScanPos ];
if ( iScanPosinCG != 0 )
{
rdStats.iNNZbeforePos0++;
}
}
} //end for (iScanPosinCG) 遍历当前CG内所有非零系数
/*---检查当前系数块组是否为全零组,计算将其量化为全零CG的率失真代价,并与原率失真代价比较---*/
if (iCGLastScanPos >= 0)
{
if( cctx.subSetId() )
{
if( !cctx.isSigGroup() )
{
const BinFracBits fracBitsSigGroup = fracBits.getFracBitsArray( cctx.sigGroupCtxId() );
d64BaseCost += xGetRateSigCoeffGroup(fracBitsSigGroup, 0) - rdStats.d64SigCost;
pdCostCoeffGroupSig[ cctx.subSetId() ] = xGetRateSigCoeffGroup(fracBitsSigGroup, 0);
}
else
{
//跳过最后一个系数组,它将与下面最后一个位置一起处理。
if (cctx.subSetId() < iCGLastScanPos) //skip the last coefficient group, which will be handled together with last position below.
{
if ( rdStats.iNNZbeforePos0 == 0 )
{
d64BaseCost -= rdStats.d64SigCost_0;
rdStats.d64SigCost -= rdStats.d64SigCost_0;
}
// rd-cost if SigCoeffGroupFlag = 0, initialization
// 如果SigCoeffGroupFlag=0,则初始化RD成本
double d64CostZeroCG = d64BaseCost;
const BinFracBits fracBitsSigGroup = fracBits.getFracBitsArray( cctx.sigGroupCtxId() );
if (cctx.subSetId() < iCGLastScanPos)
{
d64BaseCost += xGetRateSigCoeffGroup(fracBitsSigGroup,1);
d64CostZeroCG += xGetRateSigCoeffGroup(fracBitsSigGroup,0);
pdCostCoeffGroupSig[ cctx.subSetId() ] = xGetRateSigCoeffGroup(fracBitsSigGroup,1);
}
// try to convert the current coeff group from non-zero to all-zero
// 尝试将当前coeff组从非零转换为全零
// 将非零系数重置为零系数的失真
d64CostZeroCG += rdStats.d64UncodedDist; // distortion for resetting non-zero levels to zero levels
// 保持所有非零系数的失真和系数成本
d64CostZeroCG -= rdStats.d64CodedLevelandDist; // distortion and level cost for keeping all non-zero levels
// 所有系数的sig成本,包括零级和非零级
d64CostZeroCG -= rdStats.d64SigCost; // sig cost for all coeffs, including zero levels and non-zerl levels
// if we can save cost, change this block to all-zero block
//如果我们能节省成本,把这个CG改成全零CG
if ( d64CostZeroCG < d64BaseCost )
{
cctx.resetSigGroup();
d64BaseCost = d64CostZeroCG;
if (cctx.subSetId() < iCGLastScanPos)
{
pdCostCoeffGroupSig[ cctx.subSetId() ] = xGetRateSigCoeffGroup(fracBitsSigGroup,0);
}
// reset coeffs to 0 in this block
// 在此块中将系数重置为0
for( int iScanPosinCG = maxNonZeroPosInCG; iScanPosinCG >= 0; iScanPosinCG-- )
{
iScanPos = cctx.minSubPos() + iScanPosinCG;
uint32_t uiBlkPos = cctx.blockPos( iScanPos );
if (piDstCoeff[ uiBlkPos ])
{
piDstCoeff [ uiBlkPos ] = 0;
pdCostCoeff[ iScanPos ] = pdCostCoeff0[ iScanPos ];
pdCostSig [ iScanPos ] = 0;
}
}
} // end if ( d64CostAllZeros < d64BaseCost )
}
} // end if if (uiSigCoeffGroupFlag[ uiCGBlkPos ] == 0)
}
else
{
cctx.setSigGroup();
}
}// end if(iCGLastScanPos >= 0)
} //end for (cctx.subSetId) All 遍历所有系数块组CG
//===== estimate last position =====
//===== 估计最后非零系数的位置 =====
if ( iLastScanPos < 0 )
{
return;
}
double d64BestCost = 0;
int iBestLastIdxP1 = 0;
if( !CU::isIntra( *tu.cu ) && isLuma( compID ) && tu.depth == 0 )
{
const BinFracBits fracBitsQtRootCbf = fracBits.getFracBitsArray( Ctx::QtRootCbf() );
d64BestCost = d64BlockUncodedCost + xGetICost( fracBitsQtRootCbf.intBits[ 0 ] );
d64BaseCost += xGetICost( fracBitsQtRootCbf.intBits[ 1 ] );
}
else
{
bool previousCbf = tu.cbf[COMPONENT_Cb];
bool lastCbfIsInferred = false;
if( useIntraSubPartitions )
{
bool rootCbfSoFar = false;
bool isLastSubPartition = CU::isISPLast(*tu.cu, tu.Y(), compID);
uint32_t nTus = tu.cu->ispMode == HOR_INTRA_SUBPARTITIONS ? tu.cu->lheight() >> floorLog2(tu.lheight()) : tu.cu->lwidth() >> floorLog2(tu.lwidth());
if( isLastSubPartition )
{
TransformUnit* tuPointer = tu.cu->firstTU;
for( int tuIdx = 0; tuIdx < nTus - 1; tuIdx++ )
{
rootCbfSoFar |= TU::getCbfAtDepth(*tuPointer, COMPONENT_Y, tu.depth);
tuPointer = tuPointer->next;
}
if( !rootCbfSoFar )
{
lastCbfIsInferred = true;
}
}
if( !lastCbfIsInferred )
{
previousCbf = TU::getPrevTuCbfAtDepth(tu, compID, tu.depth);
}
}
BinFracBits fracBitsQtCbf = fracBits.getFracBitsArray( Ctx::QtCbf[compID]( DeriveCtx::CtxQtCbf( rect.compID, previousCbf, useIntraSubPartitions ) ) );
if( !lastCbfIsInferred )
{
d64BestCost = d64BlockUncodedCost + xGetICost(fracBitsQtCbf.intBits[0]);
d64BaseCost += xGetICost(fracBitsQtCbf.intBits[1]);
}
else
{
d64BestCost = d64BlockUncodedCost;
}
}
int lastBitsX[LAST_SIGNIFICANT_GROUPS] = { 0 };
int lastBitsY[LAST_SIGNIFICANT_GROUPS] = { 0 };
{
int dim1 = std::min(JVET_C0024_ZERO_OUT_TH, uiWidth);
int dim2 = std::min(JVET_C0024_ZERO_OUT_TH, uiHeight);
int bitsX = 0;
int bitsY = 0;
int ctxId;
//X-coordinate
//横坐标
for ( ctxId = 0; ctxId < g_uiGroupIdx[dim1-1]; ctxId++)
{
const BinFracBits fB = fracBits.getFracBitsArray( cctx.lastXCtxId(ctxId) );
lastBitsX[ ctxId ] = bitsX + fB.intBits[ 0 ];
bitsX += fB.intBits[ 1 ];
}
lastBitsX[ctxId] = bitsX;
//Y-coordinate
//纵坐标
for ( ctxId = 0; ctxId < g_uiGroupIdx[dim2-1]; ctxId++)
{
const BinFracBits fB = fracBits.getFracBitsArray( cctx.lastYCtxId(ctxId) );
lastBitsY[ ctxId ] = bitsY + fB.intBits[ 0 ];
bitsY += fB.intBits[ 1 ];
}
lastBitsY[ctxId] = bitsY;
}
bool bFoundLast = false;//找到最后系数的标志
//从后向前遍历CG
for (int iCGScanPos = iCGLastScanPos; iCGScanPos >= 0; iCGScanPos--)
{
d64BaseCost -= pdCostCoeffGroupSig [ iCGScanPos ];
if (cctx.isSigGroup( iCGScanPos ) )
{
uint32_t maxNonZeroPosInCG = iCGSizeM1;
if( lfnstIdx > 0 && ( ( uiWidth == 4 && uiHeight == 4 ) || ( uiWidth == 8 && uiHeight == 8 && cctx.cgPosX() == 0 && cctx.cgPosY() == 0 ) ) )
{
maxNonZeroPosInCG = 7;
}
//从后向前遍历CG内的系数
for( int iScanPosinCG = maxNonZeroPosInCG; iScanPosinCG >= 0; iScanPosinCG-- )
{
iScanPos = iCGScanPos * (iCGSizeM1 + 1) + iScanPosinCG;
if (iScanPos > iLastScanPos)
{
continue;
}
uint32_t uiBlkPos = cctx.blockPos( iScanPos );
if( piDstCoeff[ uiBlkPos ] )
{
uint32_t uiPosY = uiBlkPos >> uiLog2BlockWidth;
uint32_t uiPosX = uiBlkPos - ( uiPosY << uiLog2BlockWidth );
double d64CostLast = xGetRateLast( lastBitsX, lastBitsY, uiPosX, uiPosY );
double totalCost = d64BaseCost + d64CostLast - pdCostSig[ iScanPos ];
if( totalCost < d64BestCost )
{
iBestLastIdxP1 = iScanPos + 1;//最佳的最后非零系数位置
d64BestCost = totalCost;
}
if( piDstCoeff[ uiBlkPos ] > 1 )
{ //找到最后一个非零系数
bFoundLast = true;
break;
}
d64BaseCost -= pdCostCoeff[ iScanPos ];
d64BaseCost += pdCostCoeff0[ iScanPos ];
}
else
{
d64BaseCost -= pdCostSig[ iScanPos ];
}
} //end for
if (bFoundLast)
{
break;
}
} // end if (uiSigCoeffGroupFlag[ uiCGBlkPos ])
DTRACE( g_trace_ctx, D_RDOQ_COST, "%d: %3d, %3d, %dx%d, comp=%d\n", DTRACE_GET_COUNTER( g_trace_ctx, D_RDOQ_COST ), rect.x, rect.y, rect.width, rect.height, compID );
DTRACE( g_trace_ctx, D_RDOQ_COST, "Uncoded=%d\n", (int64_t)( d64BlockUncodedCost ) );
DTRACE( g_trace_ctx, D_RDOQ_COST, "Coded =%d\n", (int64_t)( d64BaseCost ) );
} // end for CG
//设置量化后的系数
for ( int scanPos = 0; scanPos < iBestLastIdxP1; scanPos++ )
{
int blkPos = cctx.blockPos( scanPos );
TCoeff level = piDstCoeff[ blkPos ];
uiAbsSum += level;
piDstCoeff[ blkPos ] = ( plSrcCoeff[ blkPos ] < 0 ) ? -level : level;
}
//===== clean uncoded coefficients =====
//===== 清除不编码的系数(将其归零)====
for ( int scanPos = iBestLastIdxP1; scanPos <= iLastScanPos; scanPos++ )
{
piDstCoeff[ cctx.blockPos( scanPos ) ] = 0;
}
if( cctx.signHiding() && uiAbsSum>=2)
{
const double inverseQuantScale = double(g_invQuantScales[0][cQP.rem(isTransformSkip)]);
int64_t rdFactor = (int64_t)(inverseQuantScale * inverseQuantScale * (1 << (2 * cQP.per(isTransformSkip))) / m_dLambda / 16
/ (1 << (2 * DISTORTION_PRECISION_ADJUSTMENT(channelBitDepth)))
+ 0.5);
int lastCG = -1;//最后一个CG
int absSum = 0 ;
int n ;
//遍历 CG
for (int subSet = iCGNum - 1; subSet >= 0; subSet--)
{
int subPos = subSet << cctx.log2CGSize();
//CG第一个非零系数和CG的最后一个非零系数
int firstNZPosInCG = iCGSizeM1 + 1, lastNZPosInCG = -1;
absSum = 0 ;
//寻找CG内的最后一个非零系数
for( n = iCGSizeM1; n >= 0; --n )
{
if( piDstCoeff[ cctx.blockPos( n + subPos )] )
{
lastNZPosInCG = n;
break;
}
}
//寻找CG内第一个非零系数
for( n = 0; n <= iCGSizeM1; n++ )
{
if( piDstCoeff[ cctx.blockPos( n + subPos )] )
{
firstNZPosInCG = n;
break;
}
}
//计算所有非零系数的和
for( n = firstNZPosInCG; n <= lastNZPosInCG; n++ )
{
absSum += int(piDstCoeff[ cctx.blockPos( n + subPos )]);
}
if(lastNZPosInCG>=0 && lastCG==-1)
{
lastCG = 1;
}
if( lastNZPosInCG-firstNZPosInCG>=SBH_THRESHOLD )
{
uint32_t signbit = (piDstCoeff[cctx.blockPos(subPos+firstNZPosInCG)]>0?0:1);
if( signbit!=(absSum&0x1) ) // hide but need tune 隐藏但需要调整
{
// calculate the cost
// 计算Cost
int64_t minCostInc = std::numeric_limits::max(), curCost = std::numeric_limits::max();
int minPos = -1, finalChange = 0, curChange = 0;
//从CG的最后一个非零系数向前遍历,寻找代价最小的系数位置
for( n = (lastCG == 1 ? lastNZPosInCG : iCGSizeM1); n >= 0; --n )
{
uint32_t uiBlkPos = cctx.blockPos( n + subPos );
if(piDstCoeff[ uiBlkPos ] != 0 ) //如果该位置系数不为0
{
int64_t costUp = rdFactor * ( - deltaU[uiBlkPos] ) + rateIncUp[uiBlkPos];
int64_t costDown = rdFactor * ( deltaU[uiBlkPos] ) + rateIncDown[uiBlkPos]
- ((abs(piDstCoeff[uiBlkPos]) == 1) ? sigRateDelta[uiBlkPos] : 0);
if(lastCG==1 && lastNZPosInCG==n && abs(piDstCoeff[uiBlkPos])==1)
{
costDown -= (4<::max();
}
else
{
curCost = costDown;
}
}
}
else //如果该位置系数为0
{
curCost = rdFactor * ( - (abs(deltaU[uiBlkPos])) ) + (1<=0?0:1);
if(thissignbit != signbit )
{
curCost = std::numeric_limits::max();
}
}
}
if( curCost=0)
{
piDstCoeff[minPos] += finalChange ;
}
else
{
piDstCoeff[minPos] -= finalChange ;
}
}
} // end if( lastNZPosInCG-firstNZPosInCG>=SBH_THRESHOLD )
if(lastCG==1)
{
lastCG=0 ;
}
}
}
} 最后关于估计最后系数位置部分的代码没有看明白到底在干什么...量化这部分代码真是又多又杂又难,每一种量化对应一个CPP文件。。。真是崇拜写出量化部分代码的大佬。