新手总结XML基础学习的路线
新手总结基础XML学习的路线(亲身体会)
一 、笔者心语
- 笔者本人非双非本一的大二学生,专业为软件工程。在学校的学习环境下学习了将近两年的编程,近日在微信和QQ的大佬交流群里见识许多技术,浏览了一些博主的佳文,十分有感触,于是突发奇想决定边学习边总结,总结出自己的学习上的笔记以及困扰和解决方法,一来帮助他人,二来请求其他浏览我的文章的大佬帮忙改错,也算是交流了吧。
- 很多跟我一样的新手学习完html前端知识后进入xml的学习时,总会带着学习html 的轻松感去面对xml这一类似的标记语言,但是学习xml的时候,总会出一些纰漏,语法的严谨和标记语言貌似不能同时共存于自己的大脑,这里我总结一下自己的学习路线吧 。
- xml入门学习包括以下几点:
1 XML的诞生
2. XMLl与HTML的区别和联系
3. XML的基础语法和入门
4. 约束的自定义以及引入
5. XML的解析
二 、笔记
1、xml的诞生
概念:
可扩展标记语言(Extensible Markup Language)
诞生:
随着html(超文本标志语言)的问世,文本置标语言HTML(HyperText Markup Language)免费、简单,在世界范围内得到了广泛的应用。它侧重于主页表现形式的描述,大大丰富了主页的视觉、听觉效果,为推动web互联网的蓬勃发展、推动信息和知识的网上交流发挥了不可取代的作用。这里顺便提一下,除了HTML外,还有一种超文本标记语言SGML当时也风靡一时,它为语法置标提供了异常强大的工具,同时具有极好的扩展性,因此在分类和索引数据中非常有用。但是,SGML非常复杂,并且价格昂贵,大大提升了网页开发的成本,因此几个主要的浏览器厂商都明确拒绝支持SGML,使SGML在网上传播遇到了很大障碍。(回归HTML的问题上来)由于HTML的免费,强大展示能力各大公司的角逐也拉开序幕,各个浏览器也诞生。众所周知html语言是标记性语言,语法较为松散
例如:
1 红的的文本内容
2 红的的文本内容
学过HTML的我们都知道,第一句代码是正确的的,但是第二句也是可以展示出红色的内容,语法是松散的,为了表示自己的浏览器功能强大,有点浏览器就表示自己能够解析错误的代码,导致各个浏览器开发时引擎解析规则也不一样,同一样一份网页源码在两中浏览器上展示出来样式可能不一样,大家学习时可能都碰到过这种问题;于是每一个浏览器的厂商都不愿意退让更改自己本身的网页解析引擎,从而导致浏览器之间的恶性竞争,进一步导致HTML语法的松散,因此W3C为此很不爽,一度想找代替品来放弃HTML。1996年人们开始致力于描述一个置标语言,它既具有SGML的强大功能和可扩展性,同时又具有HTML的简单性。w3c组织就发明了XML,用来代替HTML。由于XML高强度的严格性,开发的程序员更喜欢使用HTML来开发网页,也就是没干过他兄弟HTML。这很让W3C头疼。于是w3c就想,既然开发了这款标记语言,就得好好利用利用,找到他的用途充分展示它的独特优点。在Properties配置文件上,XML找到了他的独特性----可扩展性,早期的程序员的配置文件中以Properties文件保存配置信息,但是需要更新软件时比如QQ的更换皮肤这一功能需要更新了,程序员就要在写满信息的配置文件中每一个模块中处理配置信息。而XML的可扩展性则很好的改善了这一处境,XML中信息的显示方式已经从信息本身中抽取出来,放在了"样式单"中。这样做便于信息表现方式的修改,便于数据的搜索,也使得XML具有良好的自描述性,能够描述信息本身的含义甚至它们之间的关系,也就是更方便自定义规则,更方便对信息进行增删改查。不管怎么说,虽然没能取代HTML在网页开发中的地位,但是也找到自己的价值所在,就像两兄弟争夺家产,XML输了出门自寻谋生之路,后来大有所为。
2. xml与html的区别和联系
区别
- 标签体上
html的标签都是W3C组织规定好的,我们俗称预定义
而xml的标签都是在约束文件中设置好模块,简称自定义标签 - 语法上
XML文档
1 xml的文件的后缀名xml
2 xml的文件首行必须为文档声明(不可以有空格和空行)
3 xml文档中有且仅有一个根标签
4 属性值必须使用引号引起来(单双都可以)
6 xml文件的标签严格区分大小写
HTML文档
1,html文档的后缀:html,htm(都可以)
2,标签:
* 围堵标签:有开始和结束,如
* 自闭合标签:开始标签和结束标签在一起如
* 标签是可以嵌套的:需要正确嵌套,不可你中有我,我中有你
3,在开始标签中可以定义属性。属性是由键值对的形式存,值需要引号(单双都行)如color=“red”
注:单就单,双就双,不可都有
4,html不区分大小写,但是建议用小写 - 用途上
XML
XML是存储数据的,做保存配置文件信息的文件;也可以展示网页数据
HTML
HTML是展示数据的,主要用来做网页设计
联系
1 html和xml 都是标记语言(都是标签体标记性语言),都是基于文本编辑和修改的。
2 都可以通过DOM 变成方式来访问。
3 都可以通过CSS来改变外观。
4 都是通用标识语言标准(SGML)的一个子集,它是描述网络上的数据内容和结构的标准。
5 HTML使用和XML一样的来做注释。
XML可以看成严格的HTML,由于不适合程序员网页开发习惯,将其严格性体现在配置文件上了
3. XML的基础语法和入门
- 基本语法
1 xml的文件的后缀名xml
2 xml的文件首行必须为文档声明(不可以有空格和空行)
3 xml文档中有且仅有一个根标签
4 属性值必须使用引号引起来(单双都可以)
5 标签必须有结束,可以自定义一个自闭合标签
6 xml文件的标签区分大小写 - 快速入门
功能:存储数据
1 配置文件
2 在网络中传输
组成部分
1 文档声明
① 格式:
② 属性列表:
* version:版本号(必须写)
* encoding:编码方式,告知解析引擎当前文档使用的字符集或者编码方式,(错了会报错)默认值:ISO-8859-1(若使用记事本等较为低级的文本编辑器编写XML时,注意软件自身的编码方式)
* standalone:是否独立yes/no
* 取值
* yes:不依赖其他文件
* no:依赖其他文件
2 指令(了解):结合css的
*
注意:
文档部分:两头的尖括号和问号之间还有问号和xml之间不能有空格
3 标签:标签名称自定义
* 规则:
* 名称可以包含数字,字母以及其他的字符
* 名称不能以数字和标点符号开头
* 名称不能以字母xml(或者XML,Xml等等)
* 名称不能包含空格
4 属性
* id属性值唯一
* 受约束的文件约束属性的值收到约束,以来保证数据的严谨和正确
5 文本
* 特殊字符组含义,与html一样如 小于号<:< 大于号>:> 与&:&
* CDATA区:该区域内的字符原样展示,格式:
* 文本信息需要被约束文件所约束
4. 约束的自定义以及引入
-
约束的定义:规定xml文档的书写规则
-
用途:
作为框架的使用者(程序员):(我们初学者能够在xml中引入约束文档,能够简单的读懂约束文档:)
一个软件的使用过程中
用户层谁编写xml?----用户 谁解析xml?----软件本身 用户=====(需求)=======>功能 用户=====(编写)=======>xml<==========(解析)======软件 软件=====(按照xml完善)==>功能开发者层次
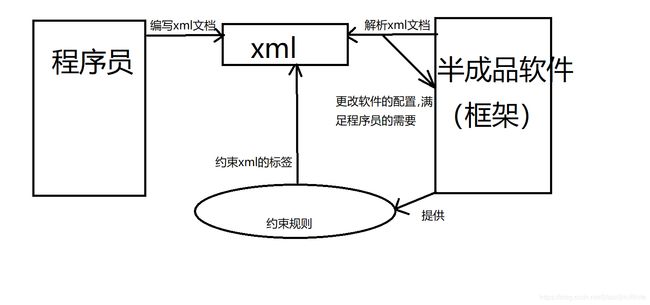
如图,一般来说,框架都是提供好的(牛的人也可以自己去写框架),程序员可以根据用户需要而添加功能属性,比如软件背景色什么的,来写xml文件,半成品的软件(框架)解析xml文件来更改软件。这时碰到一个问题就是,半合品软件怎么知道程序员写的xml文件是正确的还是错误的,此时半成品软件给了程序员一本“小册子”—约束,约束上有xml的语法,程序员根据这些语法来更改软件的配置的。 -
分类:
1,DTD:一种简答的约束技术
2,Schema:复杂的约束技术
DTD:
- 引入dtd文档到xml文档中
* 内部dtd:将约束规则定义在xml中
* 外部dtd:在文档外部的dtd文件中 - 定义dtd约束规则
* 本地约束文件:<!DOCTPE 根标签名 SYSTEM “dtd文件的位置”>
* 网络约束文件:<!DOCTPE 根标签名 PUBLIC “dtd文件名” “dtd文件的位置URL的”>
* 例子
* ELEMENT表示可以定义的标签元素
* studens:头标签
* *表示0或者多个,+表示至少一个
* name,age,sex必须按照顺序来
* #PCDATA:字符串类型
* ATTLIST 表示属性规则
* student标签的属性 number 必须有值且不唯一
- 缺陷:不够严谨,属性的取值不够丰富,达到xml的严谨性
shchema
- 引入:
1 填写xml文档的根元素
2 引入xsi前缀:xmlns=“http://www.w3.org/2001/XMLSchema-instance”
3 引入xsd文件命名空间:xsi:SchemaLocation=“虚拟路径 真实路径/文件名.xsd”
4 为每一个xsd约束声明一个前缀,最为标识 xmlns(:标识)=“虚拟路径” - 理解:
1,每一个xsd文件都是一个xml文件,也就是每一个xsd文件都是引入了http://www.w3.org/2001/XMLSchema-instance这个虚拟路径下的xsd文件,应该是xml约束的最根本法则,类似宪法和法律,一级一级的延伸,也体现了shchema的可扩展性
2,当多个约束文件同时被一个xml文件所引用时,需要变成xmlns 唯一表示 ="虚拟路径”;
3,其实http://www.w3.org/2001/XMLSchema-instance这个鼻祖xsd文件是dtd约束
5 xml文件的解析
- 解析:操作xml文档,将文档中的数据读取到内存中
* 操作xml文档:
1 解析(读取):将文档中的数据读取到内存中
2 写入:将内存中的数据保存到xml文档中,持久化的存储 - 解析xml的方式:
1 DOM:将标记语言文档一次性加载进内存,在内存中形成一棵DOM树
* 优点:操作方便,可以对文档进行增删改查
* 缺点:占内存(解析的代码不是很好的话,解析成DOM树时(编辑语言的一万倍等等),占内存)
2 SAX:逐行读取,基于事件驱动(读一行释放上一行)
* 优点:基本不占内存
* 缺点:只能读取,不能增删改 - 服务器端:DOM 客户端:SAX
- xml常见的解析器:
1 JAXP:sum公司提供的解析器,支持dom和sax两种思想
2 DOM4J:一款非常优秀的解析器
3 Jsoup:
4 PULL:安卓系统内置的解析器,SAX方式的
Jsoup:快速入门:
- 步骤:
1 导入jar包
IDEA版本如下:
jar包下载地址:链接:https://pan.baidu.com/s/1_JJwoOJCIYBpumah28zZrA 提取码:hj1z
2 获取Document对象
3 获取对应标签的Element对象
4 获取文本内容
* 外卖:
// 获取当前路径下的某个文件的URL路径
URL resource = URLTest.class.getResource("user.properties");
// 获取当前文件根目录下的某个文件的URL路径
URL resource1 = URLTest.class.getClassLoader().getResource("user.properties");
- 对象使用
1 Jsoup:工具类,可以解析html和xml,返回Document
* parse:解析html和xml,返回Document
① parse(File in, String CharsetName)
② parse(String html):解析xml或者html的字符串的
③ parse(URL url,int timeoutMillis):通过网络路径来获取指定的html或者xml文档对象
2 Document:文档对象,代表内存中的DOM树
* 主要获取Element对象,继承于Element对象
* getElemntById(String id):根据id的属性值来获取具体的元素对象
* getELementsByTag(String tagName);根据标签获取元素对象集合
* getElementsByAttribute(String key):根据属性名称来获取元素对象集合
* getElementsByAttributeValue(String key,String value):根据属性名称和对应的属性值来获取元素对象集合
3 Elements:元素Element对象的集合,可以当做ArrayList来使用
*熟记JavaSE泛型部分知识!!!!
4 Element:元素对象
① 获取子元素对象:
* getElemntById(String id):根据id的属性值来获取具体的元素对象
* getELementsByTag(String tagName);根据标签获取元素对象集合
* getElementsByAttribute(String key):根据属性名称来获取元素对象集合
* getElementsByAttributeValue(String key,String value):根据属性名称和对应的属性值来获取元素对象集合
② 获取元素属性值:
* String attr(String key):根据属性名称获取属性值
③ 获取文本内容
* String text()获取标签体内容的
* String html():获取子标签的内容,并返回字标签的字符串
5 Node:节点对象
* 是Docunment和Element的父类
快捷查询方式:
1 selector:选择器
① 使用的方法:Elements select(Stringh cssQuery)
* 语法:参考selector类中定义的语法
2 XPath:XPath即为XML的一种路径文件,他是用来确定xml(标准普通标记语言的子集)文档中的某部分位置的语言
* 使用Jsoup的XPath需要额外引入jar包(上文网盘地址中有)
* 根据document对象,创建JXDocument对象,JXDocument object=new JXDocument(document obj);
* 参考w3school手册,使用xpath的语法完成查询
例子:
* 代码:
//1.获取student.xml的path
String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.根据document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4.结合xpath语法查询
//4.1查询所有student标签
List jxNodes = jxDocument.selN("//student");
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.2查询所有student标签下的name标签
List jxNodes2 = jxDocument.selN("//student/name");
for (JXNode jxNode : jxNodes2) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.3查询student标签下带有id属性的name标签
List jxNodes3 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.4查询student标签下带有id属性的name标签 并且id属性值为itcast
List jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}
小结
学习xml知识半个月后才想起来回头写博客,忘了很多知识点或者可能有记错的知识点,实属惭愧~
对于xml的基础知识我的理解全部在这里了,如果大佬们有需要指示的麻烦在留言中知识指示,谢谢点赞~