RNN情感分类及Tensorflow2.0实现
最近被科研按在地上疯狂的摩擦,没有安排时间看文章,没有安排时间总结博客,天天就忙着鼓励自己别放弃了…感觉自己节奏有点乱了,趁着假期前希望把节奏尽快的调整过来吧。
下面介绍基于RNN的情感分类的例子并给出tensorflow2.0的具体实现,主要还是对于官方文档的理解,并在其中加入了自己的一些感悟。
- 数据集直接使用tensorflow的keras.dataset中集成的IMDB,通过
tf.keras.datasets.imdb.load_data(num_words)即可很方便的加载数据集。其中,数据集分为了四个部分,分别包含训练集和对应的标签、测试集和对应的标签,其中数据是索引序列的形式,标签取值0或1来表示积极和消极。
# 加载数据集
imdb = keras.datasets.imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words = vocab_size)
train_data[0]
- 在处理文本数据集时,接下来就应该建立词典表示词和索引之间的对应关系。由于我们使用的是集成的数据集,因此不必自己写代码来建立词典,而是使用
imdb.ger_word_index()方法来获取词典。
# 建立词典
word_index = imdb.get_word_index()
- 但是得到的词典并没有包含< start >、< end>等特殊的token及对应的索引,因此我们需要再做一点修改,将索引的0、1、2、3保留下来做为特殊token对应的索引,数据集中本身的词和索引依次后移即可。
# 建立词典
word_index = imdb.get_word_index()
word_index = {k:(v + 3) for k ,v in word_index.items()}
word_index["" ] = 0
word_index["" ] = 1
word_index["" ] = 2
word_index["" ] = 3
- 为了更直观的看到数据集中的内容,我们可以使用上面得到的词典和数据的索引序列将内容转换出来。
def decode_review(text):
return ' '.join([reversed_word_index.get(i,'?') for i in text])
decode_review(train_data[0])
output:
"
this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert is an amazing actor and now the same being director father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also to the two little boy’s that played the of norman and paul they were just brilliant children are often left out of the list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don’t you think the whole story was so lovely because it was true and was someone’s life after all that was shared with us all"
- 为了后续的训练,批次数据通常要求所有的序列是相同长度,因此这里还需要一个补齐的操作,使用
keras.preprocessing.sequence.pad_sequence()即可实现文本的自动补齐。
# 补齐数据
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value = word_index["" ],padding = 'post',maxlen = max_review_length )
test_data = keras.preprocessing.sequence.pad_sequences(test_data,value = word_index["" ],padding = 'post',maxlen = max_review_length )
- 到这一步我们就已经得到了文本的词典和补齐的数据,接下来就需要建立模型。模型的选择有很多,下面列出几种常见且简单的选择。
-
直接使用
tf.keras.Sequential()进行层的堆叠双向LSTM:
def get_model(): model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index), 64), tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) return model当然可以使用下面的方式进行建模
model = tf.keras.Sequential() model.add() ...GRU:
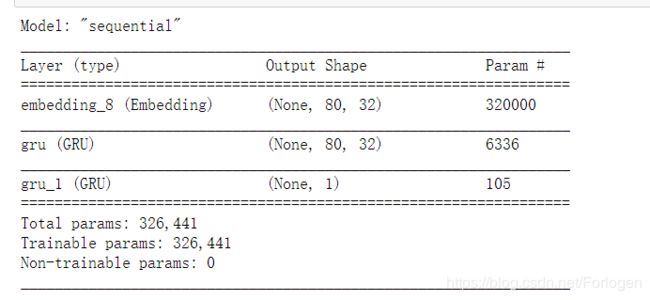
def GRU_Model(): model = keras.Sequential([ keras.layers.Embedding(input_dim = vocab_size,output_dim = 32,input_length = max_review_length), keras.layers.GRU(32,return_sequences = True), keras.layers.GRU(1,activation = 'sigmoid',return_sequences = False) ]) model.compile(optimizer = keras.optimizers.Adam(0.001), loss = keras.losses.BinaryCrossentropy(from_logits = True), metrics = ['accuracy']) return model通过
model.summary()可以查看模型的设置
-
另一种方式便是自定义模型,它可以赋予更多的灵活性,方便用户构建更复杂的模型。
class RNNModel(keras.Model): def __init__(self,units,num_classes,num_layers): super(RNNModel,self).__init__() self.units = units self.embedding = keras.layers.Embedding(vocab_size,embedding_dim,input_length = max_review_length) self.lstm = keras.layers.Bidirectional(keras.layers.LSTM(self.units)) self.dense = keras.layers.Dense(1) def call(self,x,training = None,mask = None): x = self.embedding(x) x = self.lstm(x) x = self.dense(x) return x
-
接下来就是模型的编译和训练过程,这里没什么好说的
model = RNNModel(units,num_classes,num_layers=2) model.compile(optimizer = keras.optimizers.Adam(0.001), loss = keras.losses.BinaryCrossentropy(from_logits = True), metrics = ['accuracy']) model.fit(train_data,train_labels, epochs = epochs,batch_size = batch_size, validation_data = (test_data,test_labels)) -
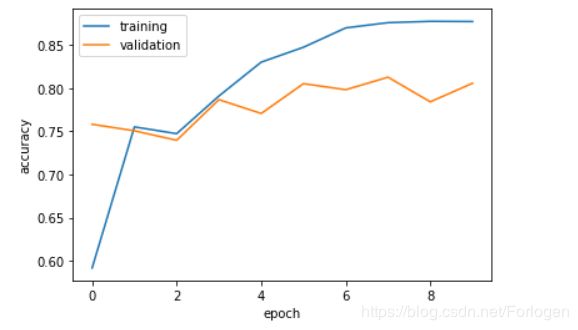
最后可以通过history来获取训练过程中的loss和accuracy来直观的观察模型的训练。
完整的代码
# coding: utf-8
# #### 通过RNN使用imdb数据集完成情感分类任务
from __future__ import absolute_import,print_function,division,unicode_literals
import tensorflow as tf
import tensorflow.keras as keras
import numpy as np
import os
import matplotlib.pyplot as plt
tf.__version__
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_LOG_LEVEL'] = '2'
# 超参数
vocab_size = 10000
max_review_length = 80
embedding_dim = 100
units = 64
num_classes = 2
batch_size = 32
epochs = 10
# 加载数据集
imdb = keras.datasets.imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words = vocab_size)
train_data[0]
# 建立词典
word_index = imdb.get_word_index()
word_index = {k:(v + 3) for k ,v in word_index.items()}
word_index["" ] = 0
word_index["" ] = 1
word_index["" ] = 2
word_index["" ] = 3
reversed_word_index = dict([(value,key) for (key,value) in word_index.items()])
def decode_review(text):
return ' '.join([reversed_word_index.get(i,'?') for i in text])
decode_review(train_data[0])
train_data = train_data[:20000]
val_data = train_data[20000:25000]
train_labels = train_labels[:20000]
val_labels = train_labels[20000:25000]
# 补齐数据
train_data = keras.preprocessing.sequence.pad_sequences(train_data,value = word_index["" ],padding = 'post',maxlen = max_review_length )
test_data = keras.preprocessing.sequence.pad_sequences(test_data,value = word_index["" ],padding = 'post',maxlen = max_review_length )
# 构建模型
class RNNModel(keras.Model):
def __init__(self,units,num_classes,num_layers):
super(RNNModel,self).__init__()
self.units = units
self.embedding = keras.layers.Embedding(vocab_size,embedding_dim,input_length = max_review_length)
"""
self.lstm = keras.layers.LSTM(units,return_sequences = True)
self.lstm_2 = keras.layers.LSTM(units)
"""
self.lstm = keras.layers.Bidirectional(keras.layers.LSTM(self.units))
self.dense = keras.layers.Dense(1)
def call(self,x,training = None,mask = None):
x = self.embedding(x)
x = self.lstm(x)
x = self.dense(x)
return x
model = RNNModel(units,num_classes,num_layers=2)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = keras.losses.BinaryCrossentropy(from_logits = True),
metrics = ['accuracy'])
model.fit(train_data,train_labels,
epochs = epochs,batch_size = batch_size,
validation_data = (test_data,test_labels))
model.summary()
result = model.evaluate(test_data,test_labels)
# output:loss: 0.6751 - accuracy: 0.8002
def GRU_Model():
model = keras.Sequential([
keras.layers.Embedding(input_dim = vocab_size,output_dim = 32,input_length = max_review_length),
keras.layers.GRU(32,return_sequences = True),
keras.layers.GRU(1,activation = 'sigmoid',return_sequences = False)
])
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = keras.losses.BinaryCrossentropy(from_logits = True),
metrics = ['accuracy'])
return model
model = GRU_Model()
model.summary()
get_ipython().run_cell_magic('time', '', 'history = model.fit(train_data,train_labels,batch_size = batch_size,epochs = epochs,validation_split = 0.1)')
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training','validation'], loc = 'upper left')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()