基于python-mysql的单词管理系统设计
python-mysql的单词管理系统设计
- 目的
- 结构
- 整体构架
- 数据库交互
- 单词记录
- 单词学习
- 单词测试
- 单词管理
- 项目总结与展望
目的
马上果壳英语分级考试,慌得不行。英语太渣,必须想方设法改变。单词本感觉太费事,而且背单词不方便,于是便有了设计一个程序来管理自己不会单词的想法。
具体想法是这样的,设计一个程序,如果我有不会的单词我就将这个单词输入进去,比如这个样子:

当然,这只是和普通笔记本一样的操作,我还得需要考虑一个机制去进行学习这些单词是吧,我就想着在学习阶段,他随机从词库中选取五个单词让咱们学,比如这样:

学习结束后呢就开始进行单词的测试,测试就是如果你觉这个单词你认识的话呢,单词就从词库中删除,这就是一个完整的逻辑了嘛,so,是这个样子的。
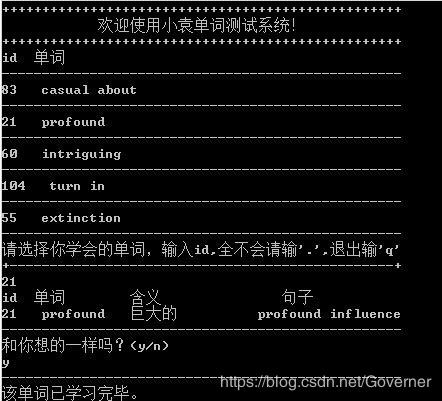
这只是完成了单词基本的记忆,如果我需要对词库进行导出或者更改查询词库的操作怎么办呢,这便是词库管理的应用了。

程序总体就是这么多,当然你也可以写一个总的接口当作所有的程序的入口。

这样的话所有的程序便结束了,我们可以开始讨论下怎样实现这个东西了。
结构
首先,是环境的问题 ,我电脑是python3。为了和mysql进行交互,你需要安装mysqldb的库,但现在mysqldb好像不太常用了,你可以用pymysql代替之。当然,如果嫌弃库少安装麻烦的话你可以直接使用Anaconda。
整体构架
环境之后便是整体结构的设计,
1.在顶层文件中我用XY.py命名是因为这款软件名字叫小袁单词嘛,就是缩写XY,这个文件负责对中间文件的调用,是总的程序出入接口。
2.在中间文件中,ER指的是English Recoder,同样,L T O 分别指的是Learn Test Operation 的意思,这四个文件分别实现了各自的功能。
3.在底层文件中EDB这个文件,是English Data Base 的意思,这个文件放在底层是因为它负责和mysql的交互,同时为中间文件提供了相应的接口。
这便是整体的构架。
| 顶层文件 | XY.py |
|---|---|
| 中间文件 | ER.py EL.py ET.py EO.py |
| 底层文件 | EDB.py |
在这放下XY.py的代码,这个代码对中间文件进行调用。代码就很简单了。
#coding:utf-8
#Author:Zhiqiang Yuan
import os
print("############################################")
print("## 欢迎使用小袁单词! ##")
while True:
print("## 请输入您需要执行的操作: ##")
print("## O:对单词进行管理 ##")
print("## R:对单词进行记录 ##")
print("## L:对单词进行学习 ##")
print("## T:对单词进行测试 ##")
print("## Q:退出 ##")
print("############################################")
op = input("你需要做点什么呢:")
op = op[0].lower()
if op == "o":
os.system("python EO.py")
elif op == "r":
os.system("python ER.py")
elif op == "l":
os.system("python EL.py")
elif op == "t":
os.system("python ET.py")
elif op == "q":
break
else:
print("输入错误!")
print("############################################")
print("## 欢迎再次使用小袁单词! ##")
数据库交互
使用了mysql的数据库,因此便需要使用python去和mysql进行交互,包括数据增加、删除、查询等等的操作。python本身就有一个mysqldb的库来简化python对mysql的操作。
#coding:utf-8
#Author:Zhiqiang Yuan
#这个文件为数据库管理模块,负责python与mysql的交互
#############################################################################################################
############################### 数据库操作 #################################################################
import MySQLdb
import os
import random
db = MySQLdb.connect(host="localhost",user="root",passwd="123",db="english",charset="utf8")
cursor = db.cursor() #创建一个游标对象
cursor.execute("use english;") #执行SQL语句,注意这里不返回结果,只是执行而已
def read_last():
cursor.execute("select * from NeedLearn order by id desc limit 1;")
data = cursor.fetchall()[0]
return data
def read_all():
cursor.execute("select * from NeedLearn;")
data = cursor.fetchall()
return data
def read_one(id):
cmd = "select * from NeedLearn where id="+str(id)+";"
cursor.execute(cmd)
data = cursor.fetchall()[0]
return data
def read_all_num():
cursor.execute("select count(*) from NeedLearn;")
num= cursor.fetchall()[0][0]
return num
def insert(word, mean, sentence):
# new = (2, "I", "我", "I love you!")
id_last = read_all_num()
id = id_last+1
param = (id,word,mean,sentence)
sql = "insert into NeedLearn values(%s,%s,%s,%s)"
n = cursor.execute(sql, param)
# 提交
db.commit()
def sort_id():
cursor.execute("alter table NeedLearn drop id;")
db.commit()
cursor.execute("alter table NeedLearn add id int(11) primary key auto_increment first;")
db.commit()
def delete(id):
cmd = "delete from NeedLearn where id = '"+str(id)+"';"
cursor.execute(cmd)
db.commit()
sort_id()
def delete_last():
cursor.execute("delete from NeedLearn where 1 order by id desc limit 1;")
db.commit()
def into_file(route="E:\EL.txt"):
if os.path.exists(route):
os.remove(route)
cursor.execute("SELECT * FROM NeedLearn INTO OUTFILE 'E:\EL.txt'FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n' ;")
import pandas as pd
# read from EL.txt
file = open("E:\EL.txt",'r',encoding="UTF-8")
content=file.readlines()
file.close()
data = []
for c in content:
temp = c.replace("\,",",")
temp = temp.split(',')
data.append(temp)
data = pd.DataFrame(data,columns=["Index","Word","Means","Sentense"])
data.to_csv("E:\EL.csv",index=None)
os.remove(route)
def word_learn():
# 返回单词
data = read_last()
if data[0] <= 5:
return read_all()
else:
i = 1
id_table = []
while(i<=5):
id = int(random.random()*data[0])+1
if id not in id_table:
id_table.append(id)
i = i + 1
data_read = []
for id in id_table:
data_read.append(read_one(id))
return data_read
# print(word_learn())
# delete_last()
# sort_id()
#create table if not exists `NeedLearn`(`id` INT UNSIGNED AUTO_INCREMENT, `word` varchar(128),`mean` varchar(128),`sentence` varchar(1024) , PRIMARY KEY ( `id` ));
里面所定义的一些函数都是对mysqldb的在封装。在使用之前,一定要检查你所创建的mysql里边的表名和脚本中的一致,如果没有的话可以先创建一个数据库和一个表(这块初始化我应该没写,如果有需求可以添加一下)。
单词记录
单词记录脚本如下:
#coding:utf-8
#Author:Zhiqiang Yuan
#这个文件为英语记录程序,运行后首先输入记录的词,接着输入记录的含义,按Q退出,否则继续记录
import EDB
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎使用小袁单词记录系统!")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
while(True):
word = input("请输入需要记录的单词:\n")
mean = input("请输入该单词的含义:\n")
sentence = input("请使用该单词造个句:\n")
print("+------------------------------------------------+")
print("您所记录的单词如下:")
print("单词:",word)
print("含义:", mean)
print("造句:", sentence)
EDB.insert(word=word, mean=mean, sentence=sentence)
print("+------------------------------------------------+")
print("记录完成!q退出,d删除上一条记录,按其他任意键继续记录。")
print("+------------------------------------------------+")
Key=input()
if Key=="q":
break
elif Key=="d":
EDB.delete_last()
print("删除完成!q退出,按其他任意键继续记录。")
Key = input()
if Key == "q":
break
else:
print("+------------------------------------------------+")
else:
print("+------------------------------------------------+")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 小袁单词欢迎您的再次使用!")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
整体就是在完成界面的交互和对数据库的一个插入。
单词学习
在单词学习这块,就涉及到一个学习机制的问题,究竟要怎样才能使学习效果达到最优,这可能每个人都有自己的意见。我所设想的是在学习阶段每次计算机输出五个随机单词进行一个简单的学习,代码就很简单了,就是每次取五个词,这个过程在EDB文件中实现了,主要还是一个人机的交互过程。
#coding:utf-8
#Author:Zhiqiang Yuan
# 学习时每次显示5个单词及其含义
import EDB
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎使用小袁单词学习系统! ")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
while True:
if EDB.read_all_num() == 0:
print(" 当前词库中没有单词呢!添加后再来吧!")
print("--------------------------------------------------")
break
else:
data = EDB.word_learn()
print("id 单词 含义 句子")
# print("id 单词 ")
print("--------------------------------------------------")
for l in data:
print("{:<2d} {:<8s} {:<10s} {:<10s}".format(l[0],l[1],l[2],l[3]))
# print("{:<2d} {:<8s}".format(l[0], l[1]))
print("--------------------------------------------------")
print("学会了吗?任意键学习下一波,退出输'q'")
print("+------------------------------------------------+")
state = input()
if state == 'q':
break
else:
pass
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎您再次使用小袁单词学习系统!")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
单词测试
当然,也需要对记忆进行检测,如果记得是对的,便可以将这个单词从词库中进行删除。在一开始阶段先显示单词,如果你记得的话就选择这个单词,这时候输出这个单词所对应的含义,若这个含义和你所设想的一致的话就删除,这就是基本思想。
#coding:utf-8
#Author:Zhiqiang Yuan
# 学习时每次显示5个单词及其含义,选择一个你认为最简单的,
# 若这个单词含义和你设想一致的话,这个词将从数据库中删除
# 如果都不熟悉则按N进行下一个五个单词
import EDB
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎使用小袁单词测试系统! ")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
while True:
if EDB.read_all_num() == 0:
print(" 当前词库中没有单词呢!添加后再来吧!")
print("--------------------------------------------------")
break
else:
data = EDB.word_learn()
# print("id 单词 含义 句子")
print("id 单词 ")
print("--------------------------------------------------")
for l in data:
# print("{:<2d} {:<8s} {:<10s} {:<10s}".format(l[0],l[1],l[2],l[3]))
print("{:<2d} {:<8s}".format(l[0], l[1]))
print("--------------------------------------------------")
print("请选择你学会的单词,输入id,全不会请输'.',退出输'q'")
print("+------------------------------------------------+")
state = input()
if state == 'q':
break
elif state == '.':
pass
else:
while True:
if state.isnumeric():
temp = False
for l in data:
if int(state)==l[0]:
temp = True
if temp:
# EDB.delete(int(state))
print("id 单词 含义 句子")
temp_data = EDB.read_one(int(state))
print("{:<2d} {:<8s} {:<10s} {:<10s}".format(temp_data[0],temp_data[1],temp_data[2],temp_data[3]))
print("--------------------------------------------------")
key_same = input("和你想的一样吗?(y/n)\n")
if key_same =="y":
EDB.delete(int(state))
print("--------------------------------------------------")
print("该单词已学习完毕。")
print("--------------------------------------------------")
else:
print("没事,要更加努力哦!")
print("--------------------------------------------------")
break
else:
print("--------------------------------------------------")
print("请输入正确ID!")
state = input()
else:
print("--------------------------------------------------")
print("请输入正确数字!")
state = input()
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎您再次使用小袁单词测试系统!")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
单词管理
同样也需要一个脚本对这些词库进行管理,比如词库导出,或者删除某个单词等的操作。代码如下:
#coding:utf-8
#Author:Zhiqiang Yuan
import EDB
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 欢迎使用小袁单词操作系统! ")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
while True:
print("==================================================")
print(" 请输入数字选择需要执行的操作 ")
print(" 1.查询词库个数。")
print(" 2.显示词库。")
print(" 3.导出词库至E:\EL.csv。")
print(" 4.删除固定ID。")
print(" q.退出。")
print("==================================================")
op = input()
if op == "1":
num = EDB.read_all_num()
print("+================================================+")
print("当前词库中一共有{}个单词,加油学习吧!".format(num))
print("+================================================+")
print("还需要做点别的吗?")
print("+================================================+")
elif op == "2":
num = EDB.read_all_num()
if num == 0:
print("--------------------------------------------------")
print("当前词库中没有单词呢!加油记录吧!")
print("--------------------------------------------------")
else:
data = EDB.read_all()
print("--------------------------------------------------")
print("id 单词 含义 句子")
print("--------------------------------------------------")
for l in data:
print("{:<2d} {:<8s} {:<10s} {:<10s}".format(l[0], l[1], l[2], l[3]))
print("--------------------------------------------------")
print("还需要做点别的吗?")
print("+================================================+")
elif op == "3":
EDB.into_file()
print("+================================================+")
print("导入成功,请在E:\EL.csv查看。")
print("+================================================+")
print("还需要做点别的吗?")
print("+================================================+")
elif op == "4":
key_ID = input("请输入需要删除的ID号:\n")
try:
print(EDB.read_one(int(key_ID)))
key_identify = input("确认删除?(y/n)\n")
if key_identify == "y":
EDB.delete(int(key_ID))
print("该词条已删除。")
else:
print("好的,我知道了。")
continue
except:
print("输入错误!")
continue
elif op == "q":
break
else:
print("请输入正确的数字!")
print("+================================================+")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
print(" 小袁单词操作系统欢迎您的再次使用! ")
print("++++++++++++++++++++++++++++++++++++++++++++++++++")
项目总结与展望
代码放在了github上,就在这里,期待您的fork,也希望您能为其做一些事情,比如可以使用qt为其做一个界面,对其进行优化,或增加一些额外的有趣的功能。若您对该程序存有疑问或某部分您在运行时出错无法解决,欢迎邮电[email protected],我将尽力为您解答。
最后放一张漂亮妹子的照片,哈哈。
