小白的第一次爬虫(链家)-基于rvest包
前几天刚考完试,闲来无聊,想学学爬虫,于是从网上搜集了点资料试试(网上很多资料可能当时可行,但是随着网页的改版,复制进行抓取时经常报错,需要修改下代码)。都说第一次爬虫从链家开始最容易,因为链家网站构造简单,所以我也从链家开始试试。
想学爬虫是因为实际上现在计量里面的变量,想要写出新意,越来越依赖新奇的数据,比如最近看到了文章里面爬了法院公布的老赖名单,通过老赖数量除以当地人口数量,作为变量trust衡量当地的诚信程度。早几年法院的网站好像设计的较简单,很多人去爬,导致网站受不了,后来网站结构变了,问了下身边学计算机的同学现在老赖名单好像不是很好爬了(不确定,以后看能不能用其他方法试试)。
由于这学期选修了一门大数据金融及其在R语言中的应用,所以初步学习了R语言的相关知识,课上主要学了quantmod相关的包和一些基本操作,当然课时有限很多东西没有学到,但是相比完全没有用过的Python还算稍微有点基础的。
爬虫中比较重要的点在于对于网站的解析,一般而言需要的东西都藏在网站的代码里面。如果我们需要的数据或信息是房价及其基本信息(如下)。

我们需要在网页的代码里面找到下面信息相对应的代码,此时只需要在浏览器中点击右键→审查元素(谷歌浏览器里面是检查),你会发现下面这样的界面。这时我们只需要先点击①这个箭头标识,然后将鼠标移动到你想获取的信息的位置如②并单击,你就能在右边③这个代码的地方找他在代码中的位置并点击右键。
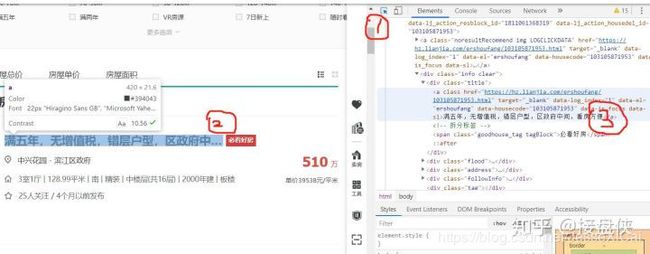
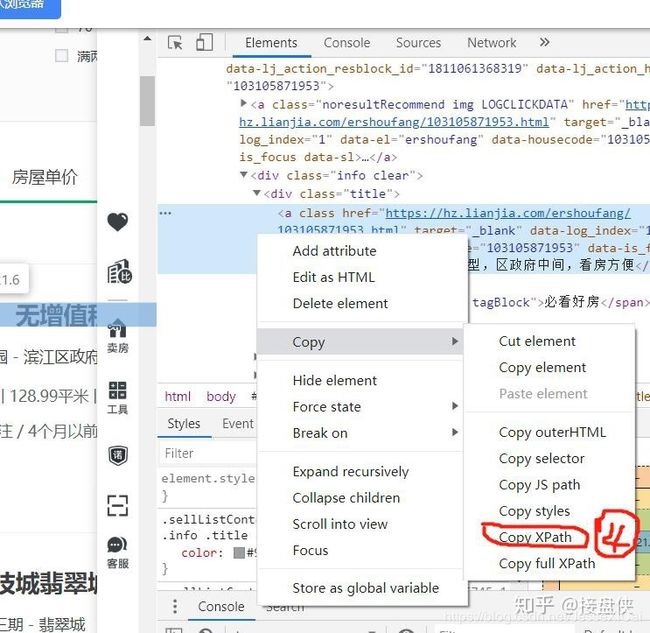
然后在④这个位置上点击copy XPath,这个XPath我暂时也没明白是什么,但是大概的意思是相当于内容信息在网页中的定位,找到了这个定位就能找到你想要的网页里面的信息。
然后我们看一下,这是第一页第一个房子的XPath信息:
标题://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[1]/a
地址://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[2]/div/a[1]
小区名称://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[2]/div/a[2]
介绍://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[3]/div/text()
总价://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[6]/div[1]/span
单价://*[@id="content"]/div[1]/ul/li[1]/div[1]/div[6]/div[2]/span
这是第一页第二个房子的XPath信息(冒号前的内容我就省略了):
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[1]/a
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[2]/div/a[1]
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[2]/div/a[2]
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[3]/div/text()
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[6]/div[1]/span
//*[@id="content"]/div[1]/ul/li[2]/div[1]/div[6]/div[2]/span
我们可以看到规律在于上面这个li[ ]括号中的数字,第一间房子中括号间的数字为1,第二件中括号中的数字为2,所以我们如果想爬取第一页的30套房子的信息只需要用一个1-30的循环分别读取相应的节点就行。
另外我们需要爬取1-100页的相关房价信息,可以在杭州链家的网站上看到,这是第100页的网站链接https://hz.lianjia.com/ershoufang/pg100/,这是第2页杭州链家的网站:https://hz.lianjia.com/ershoufang/pg2/,可以看到其区别仅在于pg后面的数字,我们可以猜到数字后面表示的是页码。
了解了网站的构造我们可以开始爬了,我们只需要通过XPath的规律在每页网页上重复30次抓取房价信息,然后将上面的循环封进另外一个有100页页码信息的链接里面就行,重复在1-100页内执行命令就行。
本次的爬虫主要基于rvest包里面的html_nodes()函数,当然在运行R包的时候你首先得通过install.packages安装相关的包才能进行加载,rvest包的使用相当简洁,只用了大概30行代码就能导出想要的数据。
#加载所需的包:
library("xml2")
library("rvest")
library("dplyr")
library("stringr")
#对爬取页数进行设定并创建数据框:
house_inf <- data.frame()
for (m in 1:100){
#发现url规律,利用字符串函数进行url拼接并规定编码:sz表示的是深圳链家
web <- read_html(str_c("http://sz.lianjia.com/ershoufang/pg", m), encoding = "UTF-8")
#利用for循环封装爬虫代码,进行批量抓取:
for (i in 1:30){
#提取房名信息:
house_title <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[1]/a'))%>%html_text()
#提取地址基本信息
house_address <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[2]/div/a[2]'))%>%html_text()
#提取二手房小区信息
house_xiaoquname <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[2]/div/a[1]'))%>%html_text()
#提取二手房总价信息
house_totalprice <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[6]/div[1]/span'))%>%html_text()
#提取二手房单价信息
house_unitprice <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[6]/div[2]/span'))%>%html_text()
house_detail <- web%>%html_nodes(xpath = paste0('//*[@id="content"]/div[1]/ul/li[',i,']/div[1]/div[3]/div/text()'))%>%html_text()
#创建数据框存储以上信息并循环并入空的数据框中
house<-data.frame(house_title,house_address,house_xiaoquname,house_totalprice,house_unitprice,house_detail)
house_inf <- rbind(house_inf,house)
}
}
#将数据写入csv文档
write.csv(house_inf, file="../house_infsz.csv")上面web部分表示的是深圳链家的网站,如果你想爬取别的城市的链家,你只需要将sz换成武汉(wh)、东莞(dg)或其他你想要的城市就行了。最后爬取的结果如下,只以深圳链家为例如下。
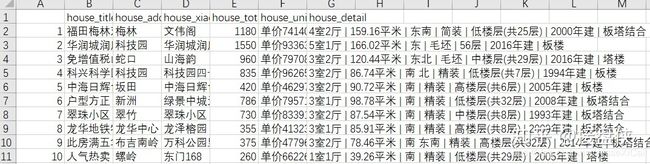
至于后面怎么整理和转换数据就是另一个问题了,很简单,用Stata或者R、Python或者其他你熟悉的软件就行。
注:此资料只用于分析房价自娱自乐(不用于商业目的),当然也借鉴了一些网友的经验,如有雷同,纯属巧合,本文同步发表于本人的知乎专栏。