大数据开发面试题总结-超详细
1、文件上传:
| 总结: 客户端上传请求--->namenode检查,返回响应--->客户端真正的文件上传请求,包括文件名,文件大小--->namenode返回上传节点--->客户端准备上传,进行块的逻辑切分--->客户端构建pipline流--->开始上传,先上传到缓存中,再上传到磁盘--->上传完成,关闭pipline流--->上传其他数据块--->全部上传完成,namenode更新元数据。 |
2、文件下载
| 总结: 客户端下载请求--->namenode进行检查,文件是否存在,并在元数据库中搜索文件的块信息及副本存储位置--->客户端开始下载,就近原则--->数据块1下载完成,下载其他数据块--->所有数据块下载完成,客户端返回下载完成。 |
3、元数据合并
| 总结: Seconderynamenode向namenode定义发送检查的请求,检查是否需要进行元数据合并--->namenode返回需要合并--->seconderynamenode发送合并请求--->namenode将正在编辑的日志文件进行回滚,转化为历时日志文件,生成新的正在编辑日志--->Seconderynamenode将edits文件和fsimage(该文件只发生在第一次合并中)文件拷贝到Seconderynamenode上--->元数据合并,生成新的fsimage文件--->Seconderynamenode将fsimage文件刷到磁盘--->将fsimage文件发到namenode并覆盖旧的。 |
4、文件切片split和文件切块block的区别?
文件切块:是HDFS进行数据存储的单位,物理上的切片,不同的数据块有可能存储在不同的数据节点上。
文件切片:是一个逻辑概念,是MR任务过程中和maptask任务一一对应的,是maptask任务执行对应的数据单元,并没有进行物理切分。
经过上面的分析:一个文件切片的大小128M最合理的。
5、MAPReduce的详细流程:
| 1、 一个大文件需要处理,它在在 HDFS 上是以 block 块形式存放,每个 block 默认为 128M存 3 份,运行时每个 map 任务会处理一个 split,如果 block 大和 split 相同( 默认情况下确实相同),有多少个 block 就有多少个 map 任务,所以对整个文件处理时会有很多 map 任务进行并行计算 3、数据溢写入到磁盘之前,首先会根据 reducer 的数量划分成同数量的分区(partition),每个分区中的都数据会有后台线程根据 map 任务的输出结果 key2 进行内排序(字典顺序、自然数顺序或自定义顺序 comparator),如果有 combiner,它会在溢写到磁盘之前排好序的输出上运行(combiner 的作用是使 map 输出更紧凑,写到本地磁盘和传给 reducer 的数据更少),最后在本地生成分好区且排好序的小文件; 如果 map 向环形缓冲区写入数据的速度大于向本地写入数据的速度,环形缓冲区被写满,向环形缓冲区写入数据的线程会阻塞直至缓冲区中的内容全部溢写到磁盘后再次启动,到阀值后会向本地磁盘新建一个溢写文件; 8、“最终文件”输入到 reduce 进行计算,计算结果输入到 HDFS。 |
6、Yarn的资源调度的过程
1、客户端向resourcemanager发送提交任务的请求
2、在resourcemanager端进行一系列的检查,检查输入和输出目录、权限
3、所有的检查都通过,resourcemanager会为当前的应用程序分配一个nodemanager节点,并在这个节点上启动container。并在这个container中启动MRAppMaster
4、MRAppMaster向resourcemanager申请资源,运行maptask任务和reducetask任务。
5、resourcemanager向MRAppMaster返回资源,优先返回有数据的节点。
6、MRAppMaster到相应的节点上启动container,然后在启动maptask任务和reducetask任务。
7、maptask或reducet任务启动之后需要向MRAppMaster进行汇报自身的运行状态和进度。
8、当maptask或reducetask运行完成,这个时候会向MRAppMaster进行注销自己,释放资源。
9、当整个应用程序运行完后,MRAppMaster向reducemanage注销自己 释放资源
7、job的提交的过程:
共享资源路径:
/tmp/hadoop-yarn/staging/hadoop/.staging/job_1535279614938_0001/job.jar 就是我们应用程序的jar包 wc.jar(放在共享资源路径下就自动改了job名字)
job.split job运行的数据切片信息 FileInputFormat.addInputPath() getSplit():决定启动的maptask的任务数量、决定启动maptask的节点信息
job.splitmetainfo
job.xml job.setJarByClass(Driver.class) 封装的是job的所有信息 配置文件
job.getConfiguration.getClass()
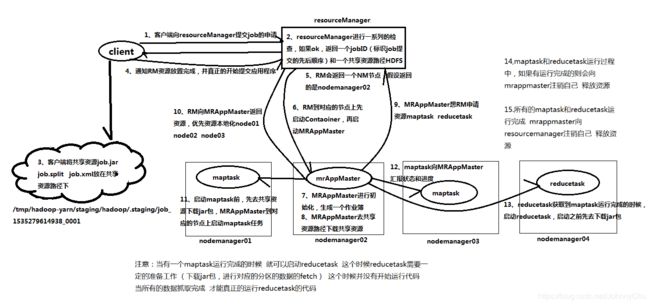
1、客户端向ResourceManager提交job的申请
2、ResourceManager进行一系列的检查,返回一个jobID(表示job提交的先后顺序)和一个共享资源路径HDFS
3、客户端将共享资源job.jar job.split job.xml放在共享资源路径下
4、客户端通知RM资源放置完成,并真正的开始提交应用程序。
5、RM会返回一个NM节点,假设返回的是nodemanager02
6、RM到对应的节点上限启动contaoiner,再启动MRAppMaster
7、MRAppMaster进行初始化,生成一个作业薄。
8、MRAppMaster去共享资源路径下载共享资源nodemanager02
9、MRAppMaster想RM申请资源maptask reducetask
10、RM向MRAppMaster返回资源,优先资源本地node01 node02 node03
11、启动maptask前,先去共享资源下载jar包,MRAppMaster到对应的节点上启动maptask任务
12、maptask向MRAppMaster汇报状态和进度
13、reducetask获取maptask运行完成的时候,启动reducetask,启动之前先去下载jar包。
14、Maptask和reducetask运行过程中,如有运行完成的则会向MRAppMaster注销自己,释放资源
15、所有的maptask和reducetask运行完成,MRAppMaster向ResourceManager注销自己,释放资源
8、Hive是什么?
Hive是一个hadoop的客户端,对外提供sql接口,数据存储在HDFS,计算使用MR
9、产生数据倾斜的原因:
A:key分布不均匀
B:业务数据本身的特性
C:建表考虑不周全
D:某些HQL语句本身就存在数据倾斜
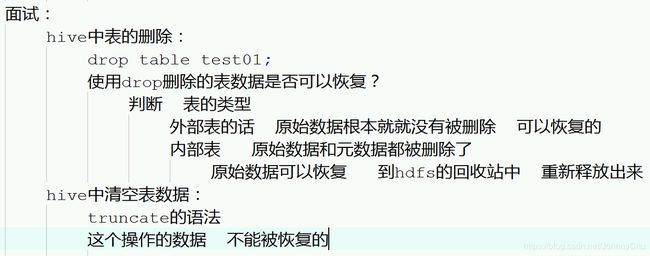
10、Hive中的表数据删除了可以恢复吗?
可以,内部表:原始数据删除了。通过垃圾回收机制可以恢复。但元数据不能恢复。
外部表:原始数据没有被删除,只是删除了表与数据的对应关系。
11、面试题:创建实例对象的五种方式:
- 调用构造器(公开)
- 静态工厂方法(构造器私有) 可以实现单例
- 反射(Class,Constructor,Method,Field)
- 克隆(Object.clone())
- 反序列化(ObjectOutputStream oos / ObjectInputStream ois)
![]()
12、DAGScheduler的工作流程:
| 1、spark-submit提交任务 2、初始化DAGScheduler 和 TaskScheduler 3、接收到applicatoin之后,DAGScheduler 会首先把applicatoin抽象成一个DAG 有向无环图 4、DAGScheduler对这个DAG(DAG中的一个Job)进行stage的切分 5、把每一个stage提交给TaskScheduler |
13、yarn-client、 yarn-cluster两种模式的差别
spark-submit提交给yarn的两种方式总结与区分:
spark-submit提交给yarn有两种方式:1为yarn-cluster, 2为yarn-client
两种方式的区别:
yarn-client主要是用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生大量的网络通信,会导致网卡流量激增!!好处在于直接执行时,本地可以看到所有的log,方便调试
yarn-cluster用户生产环境,以为driver运行在nodemanager,没有网卡流量激增的问题。缺点在于调试不方便,本地用spark-submit提交后,看不到log,只能通过yarn application -logs application_id这种命令来查看,比较麻烦 或者 yarn logs -applicationId application_id
14、Yarn作业执行流程
1、用户向 YARN 中提交应用程序,其中包括 MRAppMaster 程序,启动 MRAppMaster 的命令,用户程序等。
2、ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求它在这个 Container 中启动应用程序 MRAppMaster。
3、MRAppMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4 到 7 的步骤。
4、MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。
5、一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。
6、NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7、各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以让 MRAppMaster 随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。
15、Yarn资源调度器
Fifo schedular : 默认的单一队列调度器,先进先出的原则
Capacity schedular : 计算能力调度器,选择占用最小、优先级高的先执行,依此类推。
Fair schedular: 公平调度,所有的 job 具有相同的资源
16、Hive内部表与外部表的区别,如何选用
区别:
删除内部表,删除元数据表和真实数据;
删除外部表,只删除元数据表,不删除真实数据
元数据存在哪里?Derby MySQL
如何选用:
如果一份数据仅仅只是使用 Hive 做统计分析,那么可以使用内部表;
如果一份数据,既需要使用 Hive 去进行分析,还需要用其他计算引擎计算分析,那么就选外部表
17、Hive 支持的文件存储格式
1.行式存储:
textfile、sequencefile
2.(行分块)列式存储:
rcfile、orcfile、parquet
列式存储的优势:
1、更高的压缩比,由于相同类型的数据更容易使用高效的编码和压缩方式。
2、更小的I/O操作,可以减少一大部分不必要的数据扫描,尤其是表结构比较庞大的时候更加明显,由此也能够带来更好的查询性能。
18、Hive 分区表与分桶表
分区在HDFS上的表现形式是一个目录, 分桶是一个单独的文件
分区: 细化数据管理,直接读对应目录,缩小mapreduce程序要扫描的数据量
分桶 1、提高join查询的效率(用分桶字段做连接字段)
2、提高抽样的效率
19、Outer Join、Inner Join的区别
外连: left join/right join返回结果除了连接上的记录外,还有没连接上的记录(未连接的记录字段为null)
內连:join返回结果只有连接上的记录
20:zookeeper的文件系统:
类似于Linux文件系统的树状结构,每个节点叫znode,znode既能是目录也能是文件。
znode的存储数据量的关系:不能超过1M,最好小于1K
21:znode的分类:
按照生命周期分: 临时 和 持久,临时节点下不能创建子节点
按功能分: 带顺序编号 和 不带顺序编号,顺序编号是由当前这个顺序编号节点的父节点进行维护
22:zookeeper事件监听流程
1)client添加监听(哪个znode节点的什么事件)
NodeDataChanged
NodeChildrenChanged
NodeCreated
NodeDeleted
zookeeper系统会存储一些必要的信息:
session1, znode1, NodeDeleted
session2, znode2, NodeChildrenChanged
2)当前这个监听要被注册到zookeeper
3) zookeeper当识别到有对应的客户端对这个数据有对应事件类型的操作时,会封装当前这次事件的各种必要信息为WatchedEvent对象
4) 返回当前这次事件的通知对象WatchedEvent到对应的客户端
5) 去当前客户端的一个守护线程中寻找当时添加的那个监听器对象,这个监听器对象是存储在WatchManager中
6) 最后回调这个监听器对象中的process(WatchedEvent)方法b监听器只生效一次,在回调方法 process 中进行监听的添加能保证循环监听
23:zookeeper的应用场景
1、命名服务/名称服务/namespace管理/名字空间
模拟实现: znode系统中的任何一节点的寻路路径,有一个唯一的绝对路径
你把对应的那个名字在zookeeper的znode中创建一个节点,如果能创建成功,证明取名成功
所有同种类型的名称节点都必须统一的存储在统一目录
2、配置管理:把一个集群的所有配置都放置在zookeeper进行管理
原因:由于zookeeper提供了一个非常好的监听机制,能够让监听程序立即感知到数据的变化
zookeeper的两大核心功能区实现配置管理
模拟实现:
1、创建一个节点存储一个值(删除/修改/增加)
2、添加监听器去监听这个值的对应的事件
3、监听程序就一直等待着zookeeper发送回来的通知(响应的事件)
4、监听程序就按照事件对象WatchEvent对象中包含的信息来进行判断,来做不同的业务处理
5、业务逻辑(当数据发生变化之后重新再查询一次就OK)是独立于zookeeper
3、锁:分为两大类;
1)读写锁
读锁:共享锁
写锁:独占锁 排它锁
2)时序锁
利用创建带顺序编号的节点 就能对应的模拟完成
4、队列:分为两种:
1)同步队列:一个队列中的所有成员都聚齐时,才能进行某个业务操作
2)FIFO : 时序锁几乎是一样的实现逻辑
5、集群管理:分为两种:
1)主节点的管理:主备之间的竞争问题
可以创建一个节点代表一个namenode(最好是临时节点)
只要某个namenode一宕机,那么zookeeper系统中代表这个namenode的对应znode节点就会自动被删除
zookeeper就能发送通知到监听程序
如果说其中一个namenode的监听程序监听到当前这个namenode宕机
那么这个监听程序就会发送通知到另外一个监听程序
这个监听程序就可以发起一次选举来选举新的active 状态的anemnode
当前这个监听程序还会负责;
1、确定之前的那个namenode一定要死亡
2、确保当前要切成成active状态的namenode一定能切换过来
防止脑裂
2)从节点的管理:从节点的 上线管理(创建znode) 和 下线管理(删除一个znode)
利用zookeeper让namenode能够瞬时感知datanode的上线和下线
怎么实现?
在zookeeper系统中创建一个代表该datanode的znode节点(最好是临时的)
当前某个datanode如果宕机,那么对应的znode节点被zookeeper集群自动删除
如果zookeeper识别到代表某个datanode的znode被自动删除,就会发送事件通知到对应的监听程序
监听程序:就是监听/servers节点下的子节点的个数变化事件
当监听程序收到通知时,就能知道整个集群中的子节点(datanode)的个数发生了变化
再从zookeeper的znode系统中再重新查询一次就能知道现在还存活的datanode的列表有那些。
24、 zookeeper 选主过程
选举算法:基于 Fast Paxos :FastLeaderElection 算法
ZooKeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步。
实现这个机制的协 议叫做 ZAB 协议(Zookeeper Atomic BrodCast)。
5.1 全新集群:----------------------
以五台服务器的选主为例子:启动顺序分别是1,2,3,4,5
1、启动1,1去联系leader,跟leader做状态数据, 因为是第一个启动的。 所以没有寻找到leader那么就发起投票来进行选举leader, 首先选举自己来成为leader,但是发起投票的请求给其他的服务器,这些服务器全部都没有响应。所以最终不能选举成功,当前这个节点1就进入looking状态
2、启动2,2要去联系leader,跟1一样也没有寻找到leader,2节点也要发起投票来选举leader,最终投票结束之后,2节点只能收集到2个赞成票,还不至于能决定当前的2节点成为新的leader,原因是赞成票并没有超过集群的总节点(只有能参与投票的总节点数)的半数, 2节点也进入looking状态
3、启动服务器3,3也没有联系到leader,所以也会发起投票,最终投票结果是3节点获取到3票。所以3票超过了总节点的半数,所以服务器节点3就能成为leader。所以,所有上线了的其他服务器就自动成为规定好的角色:follower
4、启动服务器4,去联系leader,能寻找到该zookeeepr集群有leader,当前服务器4就自动成为follower
5、启动服务器5 和 4结果的过程一样
5.2 非全新集群:------------------------
那么,初始化的时候,是按照上述的说明进行选举的,但是当 zookeeper 运行了一段时间之 后,有机器 down 掉,重新选举时,选举过程就相对复杂了。
需要加入数据 version、serverid 和逻辑时钟。
数据 version:数据新的 version 就大,数据每次更新都会更新
version server id:就是我们配置的 myid 中的值,每个机器一个
逻辑时钟:这个值从 0 开始递增,每次选举对应一个值,也就是说:如果在同一次选举中, 那么这个值应该是一致的;逻辑时钟值越大,说明这一次选举 leader 的进程更新,也就是 每次选举拥有一个 zxid,投票结果只取 zxid 最新的选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据 version 大的胜出
3、数据 version 相同的情况下,server id 大的胜出根据这个规则选出 leader。
25、spark应用执行命令是什么
26、 spark分区的概念:
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。
27、spark实现wordCount

28、什么是数据混洗,数据混洗会对性能产生什么样的影响?
定义:shuffle中文一般称为 数据混洗。
shuffle的官方定义是,它是spark的一种让数据重新分布以使得某些数据被放在同一分区里的一种机制。
性能影响:
shuffle操作涉及到网络传输数据,可能还有序列化的问题。它通过map来组织数据,通过reduce来聚集,(这里的mapreduce只是作为Hadoop的mapreduce意义的一种引申)
shuffle操作会占用堆内存,当内存不够用时,就会把数据放到磁盘上。
shuffle操作会在磁盘上产生大量的中间文件,这些文件只有在相关的RDD不再使用并被回收后,才会被删除。这样做的目的是多次shuffle的时候,不用重复进行计算。所以,长时间运行Spark的任务必定消耗巨大的磁盘空间。临时文件的目录可以通过spark.local.dir进行设置。
29、spark应用执行有哪几种模式,其中哪几种是集群模式?

30、常用算子
1、常用的transformation:返回值还是一个RDD,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的
map、filter、flatMap、mapPartition
union、intersection、distinct
groupByKey、reduceByKey、aggregateByKey、sortByKey、sortBy
2、常用action算子:Action返回值不是一个RDD。它要么是一个Scala 的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
Reduce、reduceByKeyLocally、collect、count、countByKey、foreach、aggregate
31、RDD定义广播大变量
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、广播变量只能在Driver端定义,不能在Executor端定义。
3、在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有
多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中都只有一份
Driver
(面试)Hash表算法十道海量数据处理面试题
要点导航
- Hash表算法处理海量数据处理面试题
- 经典问题分析
- 为什么要根据hash后值映射到不同的机器上?
- 一、Bloom filter:判断元素是否可能在集合中
- 二、Hashing方法处理文件
- 三、bit-map 数据查找判重和删除(元素是否在集合中)
- 四、堆 TopN-大顶堆和小顶堆
- 五、双层桶划分----其实本质上就是【分而治之】的思想,重在“分”的技巧上!
- 六、数据库索引
- 七、倒排索引(Inverted index)
- 八、外排序
- 九、trie树
- 十、分布式处理 mapreduce
回到导航
Hash表算法处理海量数据处理面试题
主要针对遇到的海量数据处理问题进行分析,参考互联网上的面试题及相关处理方法,归纳为三种问题
(1)数据量大,内存小情况处理方式(分而治之+Hash映射)
(2)判断元素是否在集合中(布隆过滤器+BitMap)
(3)各种TOPN(存储和各种排序)
回到导航
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以放入内存,我们可以为数据建立字典,比如通过 map,hashmap,trie,然后直接进行统计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多的前N个数据,当然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程,首先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最好可以让数据划分后可以一次读入内存,这样不同的机子负责处理各种的数值范围,实际上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是reduce过程。
外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归并过程。
回到导航
为什么要根据hash后值映射到不同的机器上?
实际上可能想直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。因为一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我们将1000万的数据分布到10台机器上,找到每台出现次数最多的前 100个,归并之后这样不能保证找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了10台机子,这样在每台上只有1千个,假设这些机子排名在1000个之前的那些都是单独分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们让每台机子选出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash 后的值将它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
面试题具体分析:分而治之+Hash
(面试中当给定了大数据量和内存限制解决方案:1.分而治之 2.利用Hash处理文件,大文件拆分为小文件3,对结果合并汇总)
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
算法思想:分而治之+Hash
1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
典型的Top K算法
给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计;
第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。
如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
还是典型的TOP K算法,解决方案如下:
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
5、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bloom filter。
6、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1问题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
7、腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:oo,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
附:这里,再简单介绍下,位图方法:
使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。
8、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
9、上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
10、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
附、100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
补充几种方法:
回到导航
一、Bloom filter:判断元素是否可能在集合中
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
回到导航
二、Hashing方法处理文件
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
回到导航
三、bit-map 数据查找判重和删除(元素是否在集合中)
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
回到导航
四、堆 TopN-大顶堆和小顶堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
回到导航
五、双层桶划分----其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
回到导航
六、数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
回到导航
七、倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what","is"和"it"将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
回到导航
八、外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
回到导航
九、trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
回到导航
十、分布式处理 mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1).The canonical example application of MapReduce is a process to count the appearances of
each different word in a set of documents:
2).海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3).一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
javaEE
- String 、StringBuffer、StringBuilder 区别及底层实现
| 1、String是字符串常量, StringBuffer、StringBuilder是字符串变量 2、StringBuffer线程安全(方法用了synchronized修饰)、StringBuilder线程不安全 3、底层都是char[],String用了final 修饰,后二者初始容量是16+字符串的长度,追加前都会检查是否应该扩容,扩容原则 newCapacity-(oldCapacity*2+2)>0 ? newCapacity : oldCapacity*2+2 |
- Set 、List 区别?HashMap和Hashtable区别?ArrayList、LinkedList和Vector区别、底层实现?
| 1、Set 无序去重 ,List 有序可重复 2、HashMap线程不安全,允许有null的键和值 Hashtable线程安全(方法用了synchronized修饰),不允许有null的键和值 3、Vector 线程安全(方法用了synchronized修饰) ArrayList、LinkedList线程不安全 ArrayList:底层数据结构是数组,查询快,增删慢 LinkedList:底层数据结构是链表,查询慢,增删快 |
- 列出几个常用IO流
| 字节流: InputStream、FileInputStream、BufferedInputStream OutputStream、FileOutputStream、BufferedOutputStream 字符流: FileReader、BufferedReader、InputStreamReader FileWriter、PrintWriter、OutputStreamWriter |
- 谈谈你对反射机制的理解及其用途?
| JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制; |
- jvm垃圾回收机制
| gc即垃圾收集机制是指jvm用于释放那些不再使用的对象所占用的内存。java语言并不要求jvm有gc,也没有规定gc如何工作。不过常用的jvm都有gc,而且大多数gc都使用类似的算法管理内存和执行收集操作。 垃圾收集的目的在于清除不再使用的对象。gc通过确定对象是否被活动对象引用来确定是否收集该对象。gc首先要判断该对象是否是时候可以收集。两种常用的方法是引用计数和对象引用遍历。 1.引用计数 引用计数存储对特定对象的所有引用数,也就是说,当应用程序创建引用以及引用超出范围时,jvm必须适当增减引用数。当某对象的引用数为0时,便可以进行垃圾收集。 2.对象引用遍历 早期的jvm使用引用计数,现在大多数jvm采用对象引用遍历。对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。在对象遍历阶段,gc必须记住哪些对象可以到达,以便删除不可到达的对象,这称为标记(marking)对象。 下一步,gc要删除不可到达的对象。删除时,有些gc只是简单的扫描堆栈,删除未标记的未标记的对象,并释放它们的内存以生成新的对象,这叫做清除(sweeping)。这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多gc可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。 为此,gc需要停止其他的活动活动。这种方法意味着所有与应用程序相关的工作停止,只有gc运行。结果,在响应期间增减了许多混杂请求。另外,更复杂的gc不断增加或同时运行以减少或者清除应用程序的中断。有的gc使用单线程完成这项工作,有的则采用多线程以增加效率 常见垃圾回收算法:标记-清除、复制、标记-整理、分代收集 |
- jvm类加载机制
| 加载、验证、准备、解析、初始化。 一、类加载机制中的第一步加载。 在这个阶段,JVM主要完成三件事: 1、通过一个类的全限定名(包名与类名)来获取定义此类的二进制字节流(Class文件)。 2、将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。 3、在内存中生成一个代表这个类的java.lang.Class对象, 二、类的连接 类的加载过程后生成了类的java.lang.Class对象, 接着会进入连接阶段,连接阶段负责将类的二进制数据合并入JRE(Java运行时环境)中。 类的连接大致分三个阶段。 1、验证:验证被加载后的类是否有正确的结构, 2、准备:为类的静态变量(static filed)在方法区分配内存,并赋默认初值。 3、解析:将类的二进制数据中的符号引用换为直接引用。 三、类的初始化。 类的初始化的主要工作是为静态变量赋程序设定的初值。 |
- 多线程进行过哪些应用?
| 自动作业处理:比如定期备份日志、数据库什么的。 页面异步处理:比如大批量数据的核对工作。(有10W个手机号码,核对那些是已有用户) 数据库的数据分析(待分析的数据太多)、迁移等。 多步骤任务的处理,可根据步骤特征选用不同个数和特征的线程来协作处理。 这些大多用在后台服务程序里面。Swing编程有时也能用到。 并发控制,一般采用线程池技术。 线程同步,则越简单越好。 |
- 如何实现线程间的数据安全?
| 线程安全在三个方面体现1.原子性 2.可见性 3.有序性 1.原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作 Java中提供了很多atomic类,AtomicInteger,AtomicLong,AtomicBoolean等 。 JDK 提供了两种锁:Synchronized是一种同步锁,通过锁实现原子操作,修饰的对象有四种:(1)修饰代码块(2)修饰方法(3)修饰静态方法(4)修饰类。另一种是LOCK,是JDK提供的代码层面的锁。 2.可见性:一个线程对主内存的修改可以及时的被其他线程看到 对于可见性,JVM提供了synchronized和volatile. volatile的可见性是通过内存屏障和禁止重排实现的,volatile会在写操作时,在写操作后加一条store屏障指令,将本地内存中给共享变量值刷新到主内存。 Volatile在进行读操作时,会在读操作前加一条load指令,从内存中读取共享变量。 但是volatile不是原子性操作,对++操作不是安全的,不适合计数。Volatile适用于状态标记量。 3.有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,改观察结果一般杂乱无序。可以通过volatile、synchronized、lock保证有序性。 Happens-before原则: (1)程序次序规则:在一个单独的线程中,按照程序代码书写的顺序执行 (2)锁定规则:一个unlock操作happen-before后面对同一个锁的lock操作 (3)Volatile变量规则:对一个volatile变量的血操作happen-befor后面对该变量的读操作 (4)线程启动规则:Tread对象的start()方法happen-before此线程的每一个动作 (5)线程终止规则:线程的所有操作都happen—before对此线程的终止检测,可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测到线程已经终止执行。 (6)线程中断规则:对线程interrupt()方法的调用happen—before发生于被中断线程的代码检测到中断时事件的发生。 (7)对象终结规则:一个对象的初始化完成(构造函数执行结束)happen—before它的finalize()方法的开始。 (8)传递性:如果操作A happen—before操作B,操作B happen—before操作C,那么可以得出A happen—before操作C。 |
- 如何实现两个jvm间的数据安全?或者说如何保证每次读取的数据都是最新的?
| 所谓的保证每次读取的数据都是最新的,即需要保证多线程之间的数据一致性。JVM通过程序正确同步来保证数据一致性 当程序未正确同步时,就会存在数据竞争。java内存模型规范对数据竞争的定义如下: •在一个线程中写一个变量 •在另一个线程读同一个变量 •而且写和读没有通过同步来排序 当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果(Java指令重排序 这篇文章里的代码正是如此)。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。 JVM对正确同步的多线程程序的内存一致性做了如下保证: •如果程序是正确同步的,程序的执行将具有顺序一致性(sequentially consistent)—-即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同。 这里的同步是指广义上的同步,包括对常用同步原语(lock,volatile和final)的正确使用。 对于未同步或未正确同步的多线程程序,JVM只提供最小安全性:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false),JVM保证线程读操作读取到的值不会无中生有(out of thin air)的冒出来。 为了实现最小安全性,JVM在堆上分配对象时,首先会清零内存空间,然后才会在上面分配对象(JVM内部会同步这两个操作)。因此,在以清零的内存空间(pre-zeroed memory)分配对象时,域的默认初始化已经完成了。 JVM不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为未同步程序在顺序一致性模型中执行时,整体上是无序的,其执行结果无法预知。保证未同步程序在两个模型中的执行结果一致毫无意义。 和顺序一致性模型一样,未同步程序在JVM中的执行时,整体上也是无序的,其执行结果也无法预知。 |
- Java多线程死锁如何解决?
| 产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生.通常破坏循环等待是最有效的方法。
互斥条件:线程要求对所分配的资源进行排他性控制,即在一段时间内某 资源仅为一个进程所占有.此时若有其他进程请求该资源.则请求进程只能等待. 不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的线程自己来释放(只能是主动释放). 请求和保持条件:线程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他线程占有,此时请求线程被阻塞,但对自己已获得的资源保持不放. 循环等待条件:存在一种线程资源的循环等待链,链中每一个线程已获得的资源同时被链中下一个线程所请求。 |
- 了解哪些设计模式?说明动态代理的作用和实现
| 设计模式一共有23种,这些设计模式又分为三类:创建型模式、结构型模式、行为性模式 创建型模式:工厂模式、抽象工厂模式、单列模式、建造者模式。原型模式 结构型模式:适配器模式、桥接模式、过滤器模式、组合模式、装饰器模式、外观模式、享元模式、代理模式 行为性模式:责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、空对象模式、策略模式、模板模式、访问者模式 常用的设计模式:单例模式、工厂模式、策略模式、观察者模式、装饰者模式等
动态代理的作用:主要用来做方法的增强,在不改变源码的情况下,对方法的功能进行增强。 动态代理的实现:1、JDK实现动态代理(基于接口) 2、cglib动态代理(基于基础) |
- 手写各种排序(二分、冒泡、快速)
| 二分查找: public static int biSearch(int []array,int a){ int lo=0; int hi=array.length-1; int mid; while(lo<=hi){ mid=(lo+hi)/2; if(array[mid]==a){ return mid+1; }else if(array[mid] lo=mid+1; }else{ hi=mid-1; } } return -1; } 冒泡: public static int[] bubble(int[] array) { for (int i = 0; i < array.length - 1; i++) { for (int j = 0; j < array.length - 1 - i; j++) { if (array[j] > array[j + 1]) { int temp = array[j]; array[j] = array[j + 1]; array[j + 1] = temp; } } } return array; } 快排: public static int getIndex(int[] arr,int left,int right){ //找一个基准点 nlog(n) 冒泡排序:n^2 int key= arr[left]; //int left=0; //初始的左循环的下标 //int right=arr.length-1; //初始的右循环的下标 while(left //从右向左循环 循环条件 大 不变 小 交换 while(arr[right]>=key&&left right--; } //出了循环 证明arr[right] arr[left]=arr[right];//arr[right]=key //从左向右循环 小 大 交换 while(arr[left]<=key&& left left++; } //出了这个循环arr[left]>key arr[right]=arr[left]; } //出了外层循环 left=right //给分界点位置赋值 arr[left]=key; return left; } //排序过程 public static void QuickSort(int[] arr,int left,int right){ //出口 if(left>=right){ return; } //找分界点的 下标 int index=getIndex(arr, left, right); //以下标为分界进行左侧 右侧分别排序 递归调用的过程 //先对左侧进行排序 QuickSort(arr, left, index-1); //对右侧进行排序 QuickSort(arr, index+1, right); } |
- 手写单例模式
| public class Singleton{ private static Singleton instance; private Singleton(){} public static synchronized Singleton getInstance(){ if(instance==null){ instance=new Singleton(); } return instance; } } |
- 快速排序的原理和实现
| 快速排序也是分治法思想的一种实现,他的思路是使数组中的每个元素与基准值(Pivot,通常是数组的首个值,A[0])比较,数组中比基准值小的放在基准值的左边,形成左部;大的放在右边,形成右部;接下来将左部和右部分别递归地执行上面的过程:选基准值,小的放在左边,大的放在右边。。。直到排序结束。
步骤: 1.找基准值,设Pivot = a[0] 2.分区(Partition):比基准值小的放左边,大的放右边,基准值(Pivot)放左部与右部的之间。 3.进行左部(a[0] - a[pivot-1])的递归,以及右部(a[pivot+1] - a[n-1])的递归,重复上述步骤。 |
- 硬币组合方式(有1元、5角、2角、1角、5分、2分、1分)组合成1元,有多少种组合方式。用个java实现
| public class OneMoney2 { public static void main(String[] args) { int a, b, c, d, e, f, j; int n = 0; for (a = 0; a < 2; a++) { for (b = 0; b <= (100 - 100 * a) / 50; b++) { for (c = 0; c <= (100 - 50 * b) / 20; c++) { for (d = 0; d <= (100 - 50 * b - 20 * c) / 10; d++) { for (e = 0; e <= (100 - 50 * b - 20 * c - 10 * d) / 5; e++) { for (f = 0; f <= (100 - 50 * b - 20 * c - 10 * d - 5 * e) / 2; f++) { for (j = 0; j <= (100 - 50 * b - 20 * c - 10 * d - 5 * e - 2 * f); j++) { if (100 == 100 * a + 50 * b + 20 * c + 10 * d + 5 * e + 2 * f + j) { n++; System.out.println("一元硬币个数" + a + " 五角硬币个数" + b + " 贰角硬币个数" + c + " 一角硬币个数" + d + " 五分硬币个数" + e + " 二分硬币个数" + f + " 一分硬币个数" + j); } } } } } } } } System.out.println(n); } } |
- 一个表存7位数id,其中只有两个是重复,用最快的最节省内存方法找出来
| 重写hashcode方法()(如:hash(id) % 100),重复的值一定会在同一个hash散列中,这样就把范围缩小了100倍,再调用equal()方法判断是否相等。 |
- 1000亿个url 选出出现次数最多的100个,要求最节省内存的方法
| 按照url的hash(url)%1000值,将1000亿个url存储到1000个小文件中。对于每个小文件,可以构建一个url作为key,出现次数作为value的hash_map,并记录当前出现次数最多的100个url地址。 然后找出上一步求出的数据中重复次数最多的100个就是所求。 |
- 一个矩阵从左上角开始移动,只能向下移动或者向右移动,选出走过所有的节点上数字的和的最大值,并求出有最大值路径是什么
| public class Bonus { public static void main(String[] args) { int[][] arr1 = {{1,2,4,500},{8,3,3,2},{4,5,6,8},{1,3,4,6}}; System.out.println(getMost(arr1)); } public static int getMost(int[][] board) { int[][] arr = new int[board.length][board[0].length]; for(int i = 0;i for(int j = 0;j int b = board[i][j]; if(i==0&&j==0) arr[i][j] = b; else if(i==0){ arr[i][j] = arr[i][j-1]+b; }else if (j==0) { arr[i][j] = arr[i-1][j]+b; }else{ arr[i][j] = Math.max(arr[i][j-1], arr[i-1][j])+b; } System.out.println(arr[i][j] +"\t"+b + "\t"+ i +"\t" + j); } } return arr[board.length-1][board[0].length-1]; } } |
- 100G的一个数据文件、4G内存,如何用java程序全局排序?
| 首先我们的思路就是利用哈希进行文件的切分,我们把100G大小的logfile分为1000份,那么下来差不多没一个文件就是100M左右,然后再利用哈希函数除留余数的方法分配到对应的编号文件中,然后再进行全局排序 |
- 两个线程,线程A打印1,线程B打印2.编码完成这两个线程,在main方法中启动这两个线程后输出效果如下:121212....
| class Demo { boolean tag = false; public synchronized void showA() { if (tag == true) { try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("1"); tag = true; notify(); } public synchronized void showB() { if(tag == false) { try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("2"); tag = false; notify(); } }
class ThreadDemo1 implements Runnable { Demo demo; ThreadDemo1(Demo demo) { this.demo = demo; } int i = 1; public void run() { for(; i <= 10; i++) { demo.showA(); } } } class ThreadDemo2 implements Runnable { Demo demo; ThreadDemo2(Demo demo) { this.demo = demo; } int i = 1; public void run() { for(; i <= 10; i++) { demo.showB(); } } } public class TestThread { public static void main(String[] args) { Demo demo = new Demo(); ThreadDemo1 d1 = new ThreadDemo1(demo); ThreadDemo2 d2 = new ThreadDemo2(demo); Thread t1 = new Thread(d1); Thread t2 = new Thread(d2); t1.start(); t2.start(); } } |
Linux
- 列举Linux中查看系统性能的工具(区分CPU、内存、磁盘、网络等)
| iostat监测IO状态 top查看进程 free 查看内存 vmstat 可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况 fping查看即时网络 df 查看硬盘 |
- Linux默认栈空间有多大?
| 10M |
- grep、sed、awk分别指什么?简述一下grep、sed、awk的区别
| grep 查找 , sed 编辑, awk 根据内容分析并处理 awk:AWK一次处理是一行, 而一次中处理的最小单位是一个区域 sed: (关键字: 编辑) 以行为单位的文本编辑工具 grep: (关键字: 截取) 文本搜集工具, 结合正则表达式非常强大 |
- 在shell中$*、$@、$#、$0、$?有什么区别?
| $*和$@都表示传递给函数或脚本的所有参数,但是$*会将所有的参数作为一个整体,$@会将参数分开;$#代表参数个数;$0代表当前脚本名称;$?表示上一命令退出的状态码。 |
- 查找某个目录下大于1G的文件?
| find 路径 –size +1G #-size表示按大小 +表示大于 –表示小于 |
mysql
- 数据表设计三大范式是什么?
| 1.原子性,列不可再拆分 2.满足1的前提下,非主键列完全依赖于主键列,不存在部分依赖 3.满足2的前提下,非主键列直接依赖于主键列,不存在依赖传递 |
02、数据库用过哪些函数,作用
| 数学函数 select PI()* 2 *2; #pi select CEIL(-12.3); #向上取整 select FLOOR(12.3); #向下取整 select ROUND(8.45,-1); #四舍五入 select MOD(5,2); #取模 select RAND(); #随机数 [0,1) select POW(2,3); #幂运算 #随机从emp中获取两条记录。 select * from emp order by RAND() limit 2; #字符函数 select LENGTH('this is a dog'); #获取长度 select length(ename) from emp; select LOWER('THIS'); select UPPER('this'); select SUBSTR('this is zs',1,6); #下标从1开始 #select REPLACE(str,from_str,to_str); select trim(' this is '); #去两端空格 select LPAD('aa',10,'*'); #左填充 select RPAD('aa',10,'*'); #右填充 #日期函数 select NOW(); #当前时间 select SYSDATE(); #获取系统时间 select CURRENT_DATE(); select CURDATE(); select CURRENT_TIME(); select CURTIME(); select YEAR('1998-09-09'); select YEAR(NOW()); select MONTH(date); select DAY(date); #获取当前月最后一天 select LAST_DAY('2018-02-02'); #日期计算 select DATE_ADD(NOW(),interval 2 MONTH); 聚合函数 min() #求最大值 max() #求最小值 avg()#求平均值 count()#记录数 sum() #求和 加密函数 MD5() 计算字符串str的MD5校验和 PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。 SHA() 计算字符串str的安全散列算法(SHA)校验和 |
- sql优化
| 1、尽量避免全表扫描,首先应考虑在where及order by设计的列上简历索引。 2、尽量避免在where字句中对字段进行null判断,否则将导致引擎放弃使用索引而进行全表扫描。 3、应尽量避免在where字句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 4、应尽量避免在where字句中使用or来链接条件。 5、使用in和not in也要慎用。 6、尽量不要使用select *来查询。 7、避免频繁的创建和删除临时表,以减少系统表的资源消耗 |
- 批量导入mysql如何实现效率最高?
| 0. 最快的当然是直接 copy 数据库表的数据文件(版本和平台最好要相同或相似); 1. 设置 innodb_flush_log_at_trx_commit = 0 ,相对于 innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度; 2. 使用 load data local infile "文件" into table 表名; 提速明显; 3. 修改参数 bulk_insert_buffer_size, 调大批量插入的缓存; 4. 合并多条 insert 为一条: insert into t values(a,b,c), (d,e,f) ,,, 5. 手动使用事物; |
- 什么是事务
| 事务(Transaction),指访问并可能更新数据库中各种数据项的一个程序执行单元(unit),具有ACID四大特性 1.原子性(atomic): 都成功或者都失败; 2.一致性(consistency):事务操作之后,数据库所处的状态和业务规则是一致的;比如a,b账户相互转账之后,总金额不变; 3.隔离性(isolation):操作中的事务不相互影响; 四种隔离级别: ① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。 ② Repeatable read (可重复读):可避免脏读、不可重复读的发生。 ③ Read committed (读已提交):可避免脏读的发生。 ④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。 脏读dirty read:事务1更新了记录,但没有提交,事务2读取了更新后的行,然后事务T1回滚,现在T2读取无效。 幻读phantom read:事务1读取记录时事务2增加了记录并提交,事务1再次读取时可以看到事务2新增的记录; 不可重复读unrepeatable read:事务1读取记录时,事务2更新了记录并提交,事务1再次读取时可以看到事务2修改后的记录; 4.持久性(durability):事务提交后被持久化到数据库. |
- 请说明数据库主键,外键的作用,以及建立索引的好处及坏处。
| 主键: 能够唯一标识一条记录的字段为主键(亦或主码),不能重复的,不允许为空。 作用:用来保证数据完整性 外键: 表(db_role)中主键roleId和表(db_user)中的roleId对应的数值一致,称作表(db_user)的字段roleId为外键(外码);外键表示主表(db_role)和子表(db_user)两张表之间有关系 那么使用SQL语句在数据库中创建表,表的外键是另一表的主键,外键可以是重复的,可以是空值。
该字段没有重复值,但可以有一个空值
4. 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
索引有一些先天不足: 2. 更新数据的时候,系统必须要有额外的时间来同时对索引进行更新,以维持数据和索引的一致性。 |
- MySQL 怎样建立二级索引? 建立二级索引的原则是什么
| 二级索引又称辅助索引、非聚集索引(no-clustered index)。b+tree树结构。然而二级索引的叶子节点不保存记录中的所有列,其叶子节点保存的是<健值,(记录)地址>。好似聚集索引中非叶子节点保存的信息,不同的是二级索引保存的是记录地址,而聚集索引保存的是下一层节点地址。记录的地址一般可以保存两种形式。
二级索引的非叶子节点存放的记录格式为<键值,主键值,地址>,二级索引的非叶子节点依然存在主键信息。二级索引节点的记录不保存隐藏列xid和roll ptr。聚集索引的非叶子节点保存的是下一层节点地址。 |
- 某电商服务端使用mysql作为数据存储,发现在业务高峰期时,后台报表页面无法从mysql中查询出数据。请写出排查问题的流程和解决方案
| 出现这种问题很可能是某些业务字段有空值导致索引失效从而进行了全表扫描造成的,所以可以考虑以下的方案:
|
hdfs
Q1、Hdfs的写数据流程?
| 1、使用HDFS提供的客户端Client,向远程的Namenode发起RPC请求 2、Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常; 3、当客户端开始写入文件的时候,客户端会将文件切分成多个packets,并在内部以数据队列“data queue(数据队列)”的形式管理这些packets,并向Namenode申请blocks,获取用来存储replicas的合适的datanode列表,列表的大小根据Namenode中replication的设定而定; 4、开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。 5、最后一个datanode成功存储之后会返回一个ack packet(确认队列),在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。 6、如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。 7、客户端完成数据的写入后,会对数据流调用close()方法,关闭数据流; |
- 什么是大数据?
| 可以从数据的“5V”特性来进行阐述: 一、Volume:数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。 二、Variety:种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。 三、Value:数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。 四、Velocity:数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。 五、Veracity:数据的准确性和可信赖度,即数据的质量。 |
- hadoop的集群安装过程?
| 1、基础集群环境准备包括修改主机名、设置系统默认启动级别、配置普通用户 sudoer 权限、配置IP、关闭防火墙/关闭 Selinux、添加内网域名映射、安装JDK、同步服务器时间、配置免密登录 2、上传安装包,并解压到相关目录 3、配置文件的配置 4、分发安装包到各个节点,Hadoop 集群的每个节点都需要安装Hadoop 安装包 5、在HDFS 主节点上执行命令进行初始化namenode 6、在HDFS 上的主节点启动HDFS 7、在YARN 主节点启动YARN,要求在YARN 主节点进行启动 8、测试集群是否安装成功 |
- 有一个很大的文件,内存装不下,如何实现去重?
| 对文件的每一行计算hash值,按照hash值把该行内容放到某个小文件中,假设需要分成100个小文件,则可以按照(hash % 100)来分发文件内容,然后在小文件中实现去重就可以了。 |
- hdfs 的数据压缩算法?
| (1) Gzip 压缩 优点:压缩率比较高,而且压缩/解压速度也比较快; hadoop 本身支持,在应用中处理gzip 格式的文件就和直接处理文本一样;大部分 linux 系统都自带 gzip 命令,使用方便. 缺点:不支持 split。 应用场景: 当每个文件压缩之后在 130M 以内的(1 个块大小内),都可以考虑用 gzip压缩格式。 例如说一天或者一个小时的日志压缩成一个 gzip 文件,运行 mapreduce 程序的时候通过多个 gzip 文件达到并发。 hive 程序, streaming 程序,和 java 写的 mapreduce 程序完全和文本处理一样,压缩之后原来的程序不需要做任何修改。
(2) Bzip2 压缩 优点:支持 split;具有很高的压缩率,比 gzip 压缩率都高; hadoop 本身支持,但不支持 native;在 linux 系统下自带 bzip2 命令,使用方便。 缺点:压缩/解压速度慢;不支持 native。 应用场景: 适合对速度要求不高,但需要较高的压缩率的时候,可以作为 mapreduce 作业的输出格式; 或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持 split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
(3) Lzo 压缩 优点:压缩/解压速度也比较快,合理的压缩率;支持 split,是 hadoop 中最流行的压缩格式;可以在 linux 系统下安装 lzop 命令,使用方便。 缺点:压缩率比 gzip 要低一些; hadoop 本身不支持,需要安装;在应用中对 lzo 格式的文件需要做一些特殊处理(为了支持 split 需要建索引,还需要指定 inputformat 为 lzo 格式)。 应用场景: 一个很大的文本文件,压缩之后还大于 200M 以上的可以考虑,而且单个文件越大, lzo 优点越越明显。
(4) Snappy 压缩 优点:高速压缩速度和合理的压缩率。 缺点:不支持 split;压缩率比 gzip 要低; hadoop 本身不支持,需要安装; 应用场景: 当 Mapreduce 作业的 Map 输出的数据比较大的时候,作为 Map 到 Reduce的中间数据的压缩格式;或者作为一个 Mapreduce 作业的输出和另外一个 Mapreduce 作业的输入。 |
- datanode 在什么情况下不会备份?
| 如果设置备份数为1,就不会再去备份 |
- 三个 datanode 当有一个 datanode 出现错误会怎样?
| 出现错误的时候无法和namenode进行通信,namenode要去确认namenode是不是宕掉了,这段时间称作超时时长,hdfs默认时间是10分钟30秒,确认该datanode宕机后,hdfs的副本数会减1,然后namenode会将宕机的datanode的数据复制到其他机器上 |
- 描述一下 hadoop 中,有哪些地方使用了缓存机制,作用分别是什么?
| 缓存jar包到执行任务的节点的classpath中, 缓存普通文件到task运行节点的classpath中 环形缓存区,map阶段后会往本地溢写文件,他们之间会有一个环形缓存区,可以提高效率 |
- 有200M的文件 写入HDFS是先写128M 复制完之后再写72M 还是全部写完再复制?
| HDFS上在写入数据的时候,首先会对数据切块,然后从客户端到datanode形成一个管道,在至少将一个文件写入hdfs上后,表示文件写入成功,然后进行复制备份操作,所以是全部写完再复制 |
- hdfs里的 edits和 fsimage作用?
| 1)、fsimage文件其实是Hadoop文件系统元数据的一个永久性的检查点,其中包含Hadoop文件系统中的所有目录和文件idnode的序列化信息; 2)、edits文件存放的是Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所以写操作首先会被记录到edits文件中。
fsimage和edits文件都是经过序列化的,在NameNode启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
NameNode起来之后,HDFS中的更新操作会重新写到edits文件中,因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行的十分缓慢,但是如果往edits文件里面写就不会这样,每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。如果一个文件比较大,使得写操作需要向多台机器进行操作,只有当所有的写操作都执行完成之后,写操作才会返回成功,这样的好处是任何的操作都不会因为机器的故障而导致元数据的不同步 |
- 当小文件数量过多时,如何合并小文件?
| 当每个小文件数据量比较小的时候,可以通过命令的方式进行小文件的合并如:hadoop fs -cat hdfs://cdh5/tmp/lxw1234/*.txt | hadoop fs -appendToFile - hdfs://cdh5/tmp/hdfs_largefile.txt,当数据量比较大的时候建议使用MR进行小文件的合并 |
- 介绍Hadoop中RPC协议,以及底层用什么框架封装的?
| 用于将用户请求中的参数或者应答转换成字节流以便跨机传输。 函数调用层:函数调用层主要功能是:定位要调用的函数,并执行该函数,Hadoop采用了java的反射机制和动态代理实现了函数的调用。 网络传输层:网络传输层描述了Client和Server之间消息的传输方式,Hadoop采用了基于TCP/IP的socket机制。 服务端处理框架:服务端处理框架可被抽象为网络I/O处理模型,她描述了客户端和服务器端信息交互的方式,她的设计直接决定了服务器端的并发处理能力。常见的网络I/O模型有阻塞式I/O,非阻塞式I/O、事件驱动式I/O等,而Hadoop采用了基于reactor设计模式的事件驱动I/O模型 |
- hadoop出现文件块丢失怎么处理?
| 首先需要定位到哪的数据块丢失,可以通过查看日志进行检查和排除,找到文件块丢失的位置后,如果文件不是很重要可以直接删除,然后重新复制到集群上一份即可,如果删除不了,每一个集群都会有备份,需要恢复备份 |
- hadoop的守护线程?Namenode的职责?
| 五个守护进程: SecondaryNameNode ResourceManager NodeManager NameNode DataNode Namenode:主节点,存储文件的元数据(文件名,文件目录结构,文件属性——生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。周期性的接受心跳和块的状态报告信息(包含该DataNode上所有数据块的列表) 若接受到心跳信息,NN认为DN工作正常,如果在10分钟后还接受到不到DN的心跳,那么NN认为DN已经宕机 这时候NN准备要把DN上的数据块进行重新的复制。 块的状态报告包含了一个DN上所有数据块的列表,blocks report 每个1小时发送一次 |
- hadoop1.x和2.x架构上的区别?
| (1)Hadoop 1.0 Hadoop 1.0即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Apache Hadoop 0.20.x、1.x、0.21.X、0.22.x和CDH3。 (2)Hadoop 2.0 Hadoop 2.0即第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展,同时它彻底解决了NameNode 单点故障问题;针对Hadoop 1.0中的MapReduce在扩展性和多框架支持等方面的不足,它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序,进而诞生了全新的通用资源管理框架YARN。基于YARN,用户可以运行各种类型的应用程序(不再像1.0那样仅局限于MapReduce一类应用),从离线计算的MapReduce到在线计算(流式处理)的Storm等。Hadoop 2.0对应Hadoop版本为Apache Hadoop 0.23.x、2.x和CDH4。 (3)MapReduce 1.0或MRv1 MapReduce 1.0计算框架主要由三部分组成,分别是编程模型、数据处理引擎和运行时环境。它的基本编程模型是将问题抽象成Map和Reduce两个阶段,其中Map阶段将输入数据解析成key/value,迭代调用map()函数处理后,再以key/value的形式输出到本地目录,而Reduce阶段则将key相同的value进行规约处理,并将最终结果写到HDFS上;它的数据处理引擎由MapTask和ReduceTask组成,分别负责Map阶段逻辑和Reduce阶段逻辑的处理;它的运行时环境由(一个)JobTracker和(若干个)TaskTracker两类服务组成,其中,JobTracker负责资源管理和所有作业的控制,而TaskTracker负责接收来自JobTracker的命令并执行它。该框架在扩展性、容错性和多框架支持等方面存在不足,这也促使了MRv2的产生。 (4)MRv2 MRv2具有与MRv1相同的编程模型和数据处理引擎,唯一不同的是运行时环境。MRv2是在MRv1基础上经加工之后,运行于资源管理框架YARN之上的计算框架MapReduce。它的运行时环境不再由JobTracker和TaskTracker等服务组成,而是变为通用资源管理系统YARN和作业控制进程ApplicationMaster,其中,YARN负责资源管理和调度,而ApplicationMaster仅负责一个作业的管理。简言之,MRv1仅是一个独立的离线计算框架,而MRv2则是运行于YARN之上的MapReduce。 (5)YARN YARN是Hadoop 2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度。YARN不仅限于MapReduce一种框架使用,也可以供其他框架使用,比如Tez(将在第9章介绍)、Spark、Storm(将在第10章介绍)等。YARN类似于几年前的资源管理系统Mesos(将在12章介绍)和更早的Torque(将在6章介绍)。由于YARN的通用性,下一代MapReduce的核心已经从简单的支持单一应用的计算框架MapReduce转移到通用的资源管理系统YARN。 (6)HDFS Federation Hadoop 2.0中对HDFS进行了改进,使NameNode可以横向扩展成多个,每个NameNode分管一部分目录,进而产生了HDFS Federation,该机制的引入不仅增强了HDFS的扩展性,也使HDFS具备了隔离性。 |
- 写出你在工作中用过的hdfs的命令
| hadoop fs -put localpath hdfspath hadoop fs -get hdfspath localpath hadoop fs -getmerge hdfspath localpath hadoop fs -rm -r hdfspath hadoop fs -mv(-cp) hadfspath1 hafspath2 hadoop fs -cat(-text) hdfspath hadoop fs -ls hdfspath |
- 用命令显示所有的datanode的健康状况
| hadoop dfsadmin -report |
- 如何离开安全模式
| hadoop dfsadmin -safemode leave |
- 如何快速杀死一个job
| 1、执行 hadoop job -list 拿到 job-id 2、hadoop job -kill job-id |
- Hdfs回收站(防误删)
| 默认是关闭的,需要手动打开,修改配置 core-site.xml 添加:
如果打开了回收站,hdfs会为每个用户都建一个回收站,用户删除文件时,文件并不是彻底地消失了, 而是mv到了/user/用户名/.Trash/这个文件夹下,在一段时间内,用户可以恢复这些已经删除的文件。 如果用户没有主动删除,那么系统会根据用户设置的时间把文件删除掉,用户也可以手动清空回收站, 这样删除的文件就再也找不回来了 JavaAPI: Trash trash = new Trash(fs, conf); trash.moveToTrash(new Path("/xxxx")); Shell: 如果你想直接删除某个文件,而不把其放在回收站,就要用到-skipTrash命令 例如:hadoop fs -rm -r -skipTrash /test
查看回收站:hadoop fs -ls /user/hadoop/.Trash/Current |
hive
Q1、udf,udaf,udtf的区别?
| Hive中有三种UDF: 1、用户定义函数(user-defined function)UDF; 2、用户定义聚集函数(user-defined aggregate function,UDAF); 3、用户定义表生成函数(user-defined table-generating function,UDTF)。 UDF操作作用于单个数据行,并且产生一个数据行作为输出。大多数函数都属于这一类(比如数学函数和字符串函数)。 UDAF 接受多个输入数据行,并产生一个输出数据行。像COUNT和MAX这样的函数就是聚集函数。 UDTF 操作作用于单个数据行,并且产生多个数据行-------一个表作为输出。 简单来说: UDF:返回对应值,一对一 | UDAF:返回聚类值,多对一 | UDTF:返回拆分值,一对多 |
Q2、请写出你在工作中自定义过的udf函数,简述定义步骤
| 步骤: 1.extends UDF,实现evaluate() 2.add JAR /home/hadoop/hivejar/udf.jar; 3.create temporary function tolowercase as 'com.ghgj.hive.udf.ToLowerCase'; 4.使用 5.drop temporary function tolowercase; |
Q3、Hive 内部表和外部表的区别?
| 创建外部表多了external关键字说明以及location path. Hive中表与外部表的区别: 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! |
Q4、Hive 分区表与分桶表区别
| 分区在HDFS上的表现形式是一个目录, 分桶是一个单独的文件 分区: 细化数据管理,直接读对应目录,缩小mapreduce程序要扫描的数据量 分桶: 1、提高join查询的效率(用分桶字段做连接字段) 2、提高采样的效率 |
Q5、cluster by,order by,sort by distribute by的使用场景
| order by:会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。 sort by:不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只会保证每个reducer的输出有序,并不保证全局有序。sort by不同于order by,它不受hive.mapred.mode属性的影响,sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。 distribute by:是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。 cluster by:除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。 |
Q6、hql的执行流程
| 第一步:输入一条HQL查询语句(eg. select * from tab) 第二步:解析器对这条Hql语句进行语法分析。 第三步:编译器对这条Hql语句生成HQL的执行计划。 第四步:优化器生成最佳的Hql的执行计划。 第五步:执行这条最佳Hql语句。 |
Q7、multi group by的好处,举例说明
| multi group by 可以将查询中的多个group by操作组装到一个MapReduce任务中,起到优化作用 例子: select Provice,city,county,count(rainfall) from area where data="2018-09-02" group by provice,city,count select Provice,count(rainfall) from area where data="2018-09-02" group by provice
#使用multi group by from area insert overwrite table temp1 select Provice,city,county,count(rainfall) from area where data="2018-09-02" group by provice,city,count insert overwrite table temp2 select Provice,count(rainfall) from area where data="2018-09-02" group by provice
使用multi group by 之前必须配置参数: |
Q8、hive调优的思路
| 1 好的模型设计 2 解决数据倾斜 3 减少job数 4 设置合理的map reduce的task数 5 对小文件进行合并 6 单个作业最优不如整体最优 |
Q9、hive中大表和小表join要注意什么?
| 开启map join, 然后设置合适的split的大小,来增加到合适的mapper数量 |
Q10、hive有哪些udf函数,作用
| UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字 符串函数) UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产生一个输出数据行。(count,max) UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行(explode) 1. 个数统计函数: count 2. 总和统计函数: sum 3. 平均值统计函数: avg 4. 最小值统计函数: min 5. 最大值统计函数: max 6. 非空集合总体变量函数: var_pop 7. 非空集合样本变量函数: var_samp 8. 总体标准偏离函数: stddev_pop 9. 样本标准偏离函数: stddev_samp 10.中位数函数: percentile 11. 中位数函数: percentile 12. 近似中位数函数: percentile_approx 13. 近似中位数函数: percentile_approx 14. 直方图: histogram_numeric 15. 集合去重数:collect_set 16. 集合不去重函数:collect_list 表格生成函数 Table-Generating Functions (UDTF) 1. 数组拆分成多行:explode(array) 2. Map 拆分成多行:explode(map) |
Q11、hive中使用drop table数据能恢复吗?
| 可以恢复 如果是外部表的话这个语句不会删除表中的数据只需要重新建表关联hdfs的数据目录就可以了 如果是内部表的话,则需要提前配置hdfs的回收站,当删除hive中表的时候会将表的数据放置到hdfs的回收站中,只需要从回收站还原即可 hdfs dfs –mv …….. |
Q12、Hive如何实现in和not in
| In的实现: Hive中的in的实现方式很多,简单说几种:
Not in的实现: Left outer join+is null
举例说明: 有两个表如下: skim表 userId itemId time 001 342 2015-05-08 002 382 2015-05-09 003 458 2015-05-09 004 468 2015-05-09 buy表 userId itemId time 001 342 2015-05-07 002 382 2015-05-08 003 458 2015-05-09 005 325 2015-05-09 IN实现: 如果要查询在skim表中并且也在buy表中的信息,需要用in查询,hive sql如下:
select skim.userId , skim.itemId from skim left outer join buy on skim.userId = buy .userId and skim.itemId = buy .itemId where buy .userId is not null; 或 select skim.userId , skim.itemId from skim left semi join buy on skim.userId = buy .userId and skim.itemId = buy .itemId; 或 select skim.userId , skim.itemId from skim join buy on skim.userId = buy .userId and skim.itemId = buy .itemId;
结果如下:
userId itemId 001 342 002 382 003 458 NOT IN实现: 如果要查询在skim表中并且不在buy表中的信息,需要用not in查询,hive sql如下:
select skim.userId, skim.itemId from skim left outer join buy on skim.userId=buy .userId and skim.itemId=buy .itemId where buy .userId is null;
结果如下: userId itemId 004 468
|
Q13、简要描述数据库中的 null,说出null在hive底层如何存储,并解释selecta.* from t1 a left outer join t2 b on a.id=b.id where b.id is null; 语句的含义
| null与任何值运算的结果都是null, 可以使用is null、is not null函数指定在其值为null情况下的取值。 null在hive底层默认是用'\N'来存储的,可以通过alter table test SET SERDEPROPERTIES('serialization.null.format' = 'a');来修改。 |
Q14、现场写各种sql
| 必须会!!! |
hbase
- HBase中Rowkey的设计原则?
| 建议使用String如果不是特殊要求,RowKey最好都是String。 方便线上使用Shell查数据、排查错误 更容易让数据均匀分布 不必考虑存储成本 RowKey的长度尽量短。如果RowKey太长话,第一是,存储开销会增加,影响存储效率;第二是,内存中Rowkey字段过长,内存的利用率会降低,这会降低索引命中率。 一般的做法是: 时间使用Long来表示 尽量使用编码压缩 RowKey尽量散列RowKey的设计,最重要的是要保证散列,这样就会保证所有的数据都不都是在一个region上,避免做读写的时候负载将会集中在个别region上面。 |
- HBase导入数据的几种方式?
| 1. 使用HBase的API中的Put方法。 2. 使用bulk load工具从TSV文件中导入数据。 3. 自己编写MapReduce Job导入数据。 |
- 现在有50亿条数据,150个字段,怎么快速的传到hbase上面,hbase的rowkey是怎么设计的,这150个字段怎么设计才合理?
| 使用hbase自带的工具ImportTsv ImportTsv是Hbase提供的一个命令行工具,可以将存储在HDFS上的自定义分隔符(默认\t)的数据文件,通过一条命令方便的导入到HBase表中,对于大数据量导入非常实用,其中包含两种方式将数据导入到HBase表中: 第一种是使用TableOutputformat在reduce中插入数据; 第二种是先生成HFile格式的文件,再执行一个叫做CompleteBulkLoad的命令,将文件move到HBase表空间目录下,同时提供给client查询。 依据rowkey长度原则 rowkey散列原则 rowkey唯一原则设计rowkey,根据字段关系生成列簇,生成一个列簇最好,视情况增加列簇的个数,最好1-2个 |
- 为什么会有列簇这个概念?
| 一行有若干列组成,若干列又构成一个列族(column family),这不仅有助于构建数据的语义边界或者局部边界,还有助于给他们设置某些特性(如压缩),或者指示他们存贮在内存中,一个列族的所有列存贮在同一个底层的存储文件中,这个存储文件叫做HFile |
- 解释下布隆过滤器?
| 实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。 如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。 |
- hbase 过滤器实现原则?
| Hbase过滤器实现了一些更细粒度的进行筛选,过滤器最基本的接口是Filter,还有一些其他可以直接使用的类,所有的过滤器都在服务端生效,叫做谓语下推(predicate push down),这样可以保证过滤掉的数据不会被传送回客户端。提高系统性能,Hbase中常见的过滤器有比较过滤器,专用过滤器,附加过滤器,FilterList(过滤器列表),当然我们可以通过实现Filter接口或者直接继承FilterBase类来按照自己的需求自定义过滤器 |
- 在每天增量数据较大(每天大约5T左右)时,在设计表和Hbase整体的参数配置方面有何建议?
| Rowkey的设计,遵从几个原则,在长度方面在满足需求的情况下越短越好,因为数据在持久化文件Hfile中是按照keyvalue存储的,如果rowkey过长,数据量大的是后光rowkey就要占据很大空间,影响存储效率,第二个是满足散列原则,避免数据热点堆积现象的发生,还有必须保证rowkey的唯一性,并且覆盖尽可能多的业务场景 参数:hbase.regionserver.handler.count:rpc请求的线程数量,默认值是10,生产环境建议使用100,也不是越大越好,特别是当请求内容很大的时候,比如scan/put几M的数据,会占用过多的内存,有可能导致频繁的GC,甚至出现内存溢出。 hbase.hregion.max.filesize:默认是10G, 如果任何一个column familiy里的StoreFile超过这个值, 那么这个Region会一分为二,因为region分裂会有短暂的region下线时间(通常在5s以内),为减少对业务端的影响,建议手动定时分裂,可以设置为60G。 hbase.hstore.compaction.max:默认值为10,一次最多合并多少个storefile,避免OOM |
- Hbase有哪4要素,hbase中region是谁分配的,又由谁来维护?
| client,zookeeper,master,RegionServer, hbase中的region是由master进行分配的,regionServer用来管理region |
- 描述hbase存储架构?
| HBase中的存储包括HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等 HMaster:为Region server分配region;负责Region server的负载均衡;发现失效的Region server并重新分配其上的region;HDFS上的垃圾文件回收;处理schema更新请求 HRegionServer:维护master分配给他的region,处理对这些region的io请求;负责切分正在运行过程中变的过大的region HRegion:table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。 Region按大小分隔,每个表一行是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。 Store:每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。 HBase以store的大小来判断是否需要切分region。 MemStore:memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。 StoreFile:memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。 HFile:HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。 HLog:其实HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,equence number的起始值为0,或者是最近一次存入文件系统中的equence number。 |
- HBase存储一个大量的小文件,设计Hbase存储设计方案
| 对于小文件,我这里假设不足10M,这样我们就不需要对文件split。每个小文件保存到不同的cell中,在HBase中,每一个行与列的交汇处,称为一个cell,其默认上限是10M,当然这个是可以通过配置文件调整的,调整的配置项是 “hbase.client.keyvalue.maxsize”,其默认值是10485760。对于文件源,可以是本地的文件,本测试用例中使用的是本地的email文件,大小才15k左右,我们将创建一个本地Java工程,读取本地文件后,再通过API保存到HBase中。另外一个可能的场景是,将本地程序变换为一个RESTful API,外部系统远程调用这个RESTful API,将数据存到HBase中,通过这个API,可以串起2个独立的系统。 |
- hbase 和hive 中 增、删、改、查、 库、表的概念哪些有哪些没有?
| Apache Hive是一个构建在Hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询--因为它只能够在Haoop上批量的执行Hadoop,Hive中有增、查、库、表的概念。
Apache HBase是一种Key/Value系统,它运行在HDFS之上。和Hive不一样,Hbase的能够在它的数据库上实时运行,Hbase被分区为表格,表格又被进一步分割为列簇。列簇必须使用schema定义,列簇将某一类型列集合起来(列不要求schema定义)。例如,“message”列簇可能包含:“to”, ”from” “date”, “subject”, 和”body”. 每一个 key/value对在Hbase中被定义为一个cell,每一个key由row-key,列簇、列和时间戳。在Hbase中,行是key/value映射的集合,这个映射通过row-key来唯一标识。Hbase利用Hadoop的基础设施,可以利用通用的设备进行水平的扩展。Hbase中有增删、改、查、表的概念 |
- hive和hbase整合实现
| (1) 进入 hive 安装包的 lib 目录下, 里面有一个 hive-hbase-handler 的 jar 包, 复制此 jar 包到 hbase 的 lib 目录下 scp $HIVE_HOME/lib/hive-hbase-handler-1.1.0-cdh5.4.0.jar $HBASE_HOME/lib/ (2) 将 HBASE 下的 lib 下的所有包都复制到 hive 的 lib 目录下 scp $HBASE_HOME/lib/*.jar $HIVVE_HOME/lib/ |
- HBase不用scan和get还可以使用什么方式查询?
各自也有缺点:自行百度补全
|
MapReduce
- mapreduce流程?
| Map阶段: 1:读取输入文件的内容,并解析成键值对( 2:用户写map()函数,对输入的 3:对Step 2中得到的 4:不同分区的数据,按照key值进行排序和分组,具有相同key值的value则放到同一个集合中。 5(可选):分组后的数据进行规约。 Reduce阶段: 1:对于多个map任务的输出,按照不同的分区,通过网络传输到不同的Reduce节点。 2:对多个map任务的输出结果进行合并、排序,用户书写reduce函数,对输入的key、value进行处理,得到新的key、value输出结果。 3:将reduce的输出结果保存在文件中。 |
- 如何决定一个job中需要多少个maptask和reducetask?
| 一、影响map个数,即split个数的因素主要有: 1)HDFS块的大小,即HDFS中dfs.block.size的值。如果有一个输入文件为1024m,当块为 256m时,会被划分为4个split;当块为128m时,会被划分为8个split。 2)文件的大小。当块为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。 3)文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为64m,而输入的目录中文件有100个,则划分后的split个数至少为100个。 4)splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节。 map个数的计算公式如下: splitsize=max(minimumsize,min(maximumsize,blocksize))。 如果没有设置minimumsize和maximumsize,splitsize的大小默认等于blocksize 二、reduce端的个数取决于用户的需求,默认是有一个reduce,可以在代码中声明 reduce的输出个数 |
- mapreduce如何实现数据的去重?
| 在map阶段,map方法的输出key也应该是数据,value 任意值都可以。而map的输入key和value 是已知的,key为每行文本首地址相对于整个文本首地址的偏移量,value 是每行文本,因此在map方法从输入到输出的过程中,只需要将输入的value 赋给输出的key即可。 在mapreduce整个框架下,在map输出和reduce输入之间还有一个shuffule过程,这个是系统自动完成的。 |
- 我们在开发分布式计算 job 时,是否可以去掉 reduce()阶段?为什么?
| 可以,例如我们的集群就是为了存储文件而设计的,不涉及到数据的计算,就可以将mapReduce都省掉。去掉之后就不排序了,不进行shuffle操作了。 比如,流量运营项目中的行为轨迹增强功能部分。 |
- MapReduce中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
4、紧接着使用job.setGroupingComparatorClass设置的分组函数类,进行分组,同一个Key的value放在一个迭代器里面。如果未指定GroupingComparatorClass则则使用Key的实现的compareTo方法来对其分组。 Hadoop1.0中不可避免 hadoop2.0中可以关闭,将reducetask设置为0 |
- MapReduce join
| 1.map join 缺点:只适合大小表join 优点:不会出现数据倾斜 实现:将小表数据加入缓存分发到各个计算节点,按连接关键字建立索引 job.addCacheFile(new URI("xxxxxxx")); job.setNumReduceTasks(0); 2.reduce join 缺点:会出现数据倾斜 |
- MapReduce数据倾斜
| 1. 利用combiner提前进行reduce,把一个mapper中的相同key进行了聚合,减少shuffle过程中数据量,以及reduce端的计算量。这种方法可以有效的缓解数据倾斜问题,但是如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。 2. 局部聚合加全局聚合。即进行两次mapreduce,第一次在map阶段对那些导致了数据倾斜的key 加上1-n的随机前缀,这样之前相同的key 也会被分到不同的reduce中,进行聚合,这样的话就有那些倾斜的key进行局部聚合,数量就会大大降低。然后再进行第二次mapreduce这样的话就去掉随机前缀,进行全局聚合。不过进行两次mapreduce,性能稍微比一次的差些。 |
- Yarn支持的调度器和硬件资源种类?
| YARN自带了三种常用的调度器,分别是FIFO,Capacity Scheduler和Fair Scheduler,其中,第一个是默认的调度器,它属于批处理调度器,而后两个属于多租户调度器,它采用树形多队列的形式组织资源,更适合公司应用场景 YARN支持内存和CPU两种资源类型的管理和分配:YARN对内存资源和CPU资源采用了不同的资源隔离方案。对于内存资源,为了能够更灵活的控制内存使用量,YARN采用了进程监控的方案控制内存使用,即每个NodeManager会启动一个额外监控线程监控每个container内存资源使用量,一旦发现它超过约定的资源量,则会将其杀死;对于CPU资源,则采用了Cgroups进行资源隔离 |
- Yarn作业执行流程
| 1、用户向 YARN 中提交应用程序,其中包括 MRAppMaster 程序,启动 MRAppMaster 的命令,用户程序等。 2、ResourceManager 为该程序分配第一个 Container,并与对应的 NodeManager 通讯,要求它在这个 Container 中启动应用程序 MRAppMaster。 3、MRAppMaster 首先向 ResourceManager 注册,这样用户可以直接通过 ResourceManager 查看应用程序的运行状态,然后将为各个任务申请资源,并监控它的运行状态,直到运行结束,重复 4 到 7 的步骤。 4、MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和领取资源。 5、一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通讯,要求它启动任务。 6、NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。 7、各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以让 MRAppMaster 随时掌握各个任务的运行状态,从而可以在任务败的时候重新启动任务。 |
- 编写MapReduce作业时,如何做到在Reduce阶段,先对key排序,再对value排序?
| 答:该问题通常称为“二次排序”,最常用的方法是将value放到key中,实现一个组合Key,然后自定义key排序规则(为key实现一个WritableComparable)。 |
- 手写Word Count
| 必须会!!! |
Kafka和sqoop
- kafka基本原理,kafka如何保证接收消息的顺序性
| Kafka基本原理:Kafka是apache开源一个分布式的、可分区的、可复制的消息系统。将消息的发布称producer,将消息的订阅表述为 consumer,将中间的存储阵列称作 broker Producer (push) ---> Broker <----(pull) Consumer Kafka集群中包含若干Producer,若干broker(Kafka支持水平扩展,一般 broker数量越多,集群吞吐率越高),若干ConsumerGroup,以及一个 Zookeeper 集群。 Kafka通过 Zookeeper 管理集群配置,选举 leader,以及在 ConsumerGroup发生变化时进行rebalance。Producer 使用 push 模式将消息发布到broker,Consumer 使用pull 模式从 broker订阅并消费消息。 发布/订阅消息需要指定 Topic 为了使得Kafka 的吞吐率可以线性提高,物理上把Topic 分成一个或多个Partition,每个 Partition在物理上对应一个文件夹,该文件夹下存储这个Partition 的所有消息和索引文件。创建一个 topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka 在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。因为每条消息都被append 到该 Partition中,属于顺序写磁盘,因此效率非常高
Kafka保证接收消息的顺序性: 通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。 |
- kafka的消息产生和消费过程是如何实现的?
| • Broker获取消息的 start offset和size (获取消息的size大小),根据 .index 数据查找 offset 相关的 position 数据,由于 .index 并不存储所有的 offset,所以会首先查找到小于等于 start_offset 的数据, 然后定位到相应的 .log 文件,开始顺序读取到 start_offset 确定 position。
• 根据 position 和 size 便可确认需要读取的消息范围,根据确定的消息文件范围,直接通过 sendfile 的方式将内容发送给消费者。 |
- 如何保证kafka有且仅消费一次?kafka丢数据怎么解决?
| 已经消费了数据,但是offset没提交,设置了offset自动提交 ,至少发一次+去重操作(幂等性)。定位数据是否在kafka之前就已经丢失还事消费端丢失数据的,kafka支持数据的重新回放功能(换个消费group),清空目的端所有数据,重新消费。如果是在消费端丢失数据,那么多次消费结果完全一模一样的几率很低。如果是在写入端丢失数据,那么每次结果应该完全一样(在写入端没有问题的前提下) |
- kafka如何避免consumer得到重复的数据?
| 将消息的唯一标识保存到外部介质中,每次消费处理时判断是否处理过。 |
- kafka一个节点producer收集数据失败,你们是如何知道的,如何解决?
| 使用producer产生数据时,在producer中可以通过配置返回值来确定所产生的数据已经被kafka收录。props.put("request.required.acks", "1");返回值为“1”时,表示producer每生产一条数据会跟leader的replica确认是否收到数据。 |
- KafKa获取的数据如何存入hdfs?
|
- spark读取kafka数据设置的两个参数?
kafkaParams、topics |
- 如何保证Kafka数据不丢失?
| 1.同步模式下: producer.type=sync request.required.acks=1 (0表示不需要反馈信息,1表示写入leader成功,2表示所有备份块写入成功) 2.异步模式下: 如果是异步模式:通过buffer来进行控制数据的发送,有两个值来进行控制,时间阈值与消息的数量阈值,如果buffer满了数据还没有发送出去,如果设置的是立即清理模式,风险很大,一定要设置为阻塞模式 block.on.buffer.full = true 3.当存有你最新一条记录的 replication 宕机的时候,Kafka 自己会选举出一个主节点,如果默认允许还未同步最新数据的 replication 所在的节点被选举为主节点的话,你的数据将会丢失,因此这里应该按需将参数调控为 false; unclean.leader.election.enable = false (默认参数为 true) |
- Kafka leader选举?
| 如果某个分区所在的服务器除了问题,不可用,kafka会从该分区的其他的副本中选择一个作为新的Leader。之后所有的读写就会转移到这个新的Leader上。现在的问题是应当选择哪个作为新的Leader。显然,只有那些跟Leader保持同步的Follower才应该被选作新的Leader。 Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录。 如果某个分区的Leader不可用,Kafka就会从ISR集合中选择一个副本作为新的Leader。 |
- 如果sparkStreaming与kafka对接发现某个分区数据量特别大,怎么解决?
| 1.自定义Kafka分区组件 2.sparkStreaming 重分区 |
- kafka可以按照字典顺序消费数据吗?
| 只能单分区有序,不能全局有序 |
- 说说你对flume的了解?
| Flume 是一个分布式、可靠、高可用的海量日志聚合系统 1.x版本之前是Flume OG版本,之后是Flume NG版本 Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。 Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。 Flume NG中事件Event是基本数据单位,Agent 为最小的独立运行单位,一个agent 由Source、Sink 和 Channel 三大组件构成: Source:配置数据来源,常用的有Avro Source、Exec Source、Spooling Directory Source等 Channel: 主要提供一个队列的功能,对source提供中的数据进行简单的缓存。常用的有了 Memory Channel、JDBC Chanel、File Channel等 Sink:从Channel中取数据,进行相应的存储文件系统,数据库,或者提交到 远程服务器,常用的有HDFSsink、 Logger sink、 Avro sink,kafka sink等 |

- Flume的可靠性保证有哪些?
| 为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点 |
- Sqoop增量导入
| 增量导入:需要指定哪些数据是新增的 --check-column --incremental --last-value 例如: sqoop import \ --connect jdbc:mysql://hadoop02:3306/mysql \ --username root \ --password root \ --table help_keyword \ --target-dir /user/hadoop/myimport3 \ --incremental append \ --check-column help_keyword_id \ --last-value 500 \ -m 1 |
- sqoop 在导入数据到 mysql 中,如何让数据不重复导入?如果存在数据问题 sqoop如何处理?
| 一种方式是在导入前对hdfs的数据进行去重; 另一种方式是导出到mysql,在mysql端写存储过程去重,或者也可以通过增量导入的方式保证不插入重复的数据 |
Spark
- Spark 任务的运行流程?
| 1、构建Spark Application 的运行环境(初始化SparkContext), SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源 2、资源管理器分配 Executor 资源并启动 StandaloneExecutorBackend,Executor 运行情况将随着心跳发送到资源管理器上 3、 SparkContext构建成DAG 图,将DAG 图分解成Stage,并把Taskset发送给TaskScheduler。Executor 向 SparkContext 申请 Task,TaskScheduler 将 Task 发放给 Executor 运行同时SparkContext将应用程序代码发放Executor 4、Task在 Executor上运行,运行完毕释放所有资源。 |
- Spark有几种运行模式
| 4种:standalone模式,Local模式,Spark on YARN 模式,mesos模式 |
- Spark如何指定本地模式
| 在IDEA,Eclipse里面开发的模式就是Local模式。还有,我们直接用Spark-Shell这种进来的模式也是local。 new SparkConf().setMaster("local"),这时候我们默认的分区数 = 你的本台服务器的CPU core的个数。 分区数 = task 的个数 new SparkConf().setMasater("local[N]") 这个时候分区的个数 = N |
- Spark的算子分类
| 1)Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。 Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。 2)Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。 Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统。 |
- Spark中stage的划分规则
| Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。stage是由一组并行的task组成。 |
- 如何区分spark哪些操作是shuffle操作
| Shuffle是划分DAG中stage的标识,同时影响spark执行速度的关键步骤。宽依赖会发生shuffle操作。RDD的Transformtion函数中,又分为窄依赖和宽依赖的操作。窄依赖跟宽依赖的区别是是否发生shuffle操作。窄依赖是子RDD的各个分片不依赖于其他分片,能够独立计算得到结果,宽依赖指子RDD的各个分片会依赖于父RDD的多个分片,会造成父RDD分各个分片在集群中重新分片。 |
- RDD,DataFrame,DataSet的区别
| DataFrame比RDD多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化;Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row |
- 解释一下DAG
| DAG,有向无环图,每个操作生成的RDD之间都会连一条线,最后组成的有向无环图 |
- map和flatmap的区别
| map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象;而flatMap函数则是两个操作--先映射后扁平化:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象,最后将所有对象合并为一个对象。 |
- spark中rdd.persist()和rdd.cache()的区别
| 1)RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY; 2)可以通过persist方法手工设定StorageLevel来满足工程需要的存储级别; 3)cache或者persist并不是action; |
- spark如何提交脚本
| Spark提供了一个容易上手的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。可以指定集群资源master,executor/ driver的内存资源等。 |
- spark内存不足怎么处理?
| 1.在不增加内存的情况下,可以通过减少每个Task的大小 2.在shuffle的使用,需要传入一个partitioner,通过设置 spark.default.parallelism参数3.在standalone的模式下如果配置了--total-executor-cores 和 --executor-memory 这两个参数外,还需要同时配置--executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。 4.如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用 |
- mapreduce和spark计算框架效率区别的原因
| spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别 (1)spark把运算的中间数据存放在内存,迭代计算效率更高,mapreduce的中间结果需要落地,保存到磁盘 (2)Spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性的数据集,这些集合石弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,mapreduce的容错只能重新计算 (3)Spark更通用,提供了transformation和action这两大类的多功能api,另外还有流式处理sparkstreaming模块、图计算等等,mapreduce只提供了map和reduce两种操作,流计算及其他的模块支持比较缺乏。 (4)Spark框架和生态更为复杂,有RDD,血缘lineage、执行时的有向无环图DAG,stage划分等,很多时候spark作业都需要根据不同业务场景的需要进行调优以达到性能要求,mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,运行较为稳定,适合长期后台运行。 |
- Spark数据倾斜怎么处理?
| https://tech.meituan.com/spark_tuning_pro.html |
- Spark如何和kafka对接?
| 1、 KafkaUtils.createStream 执行流程如下: 创建createStream,Receiver被调起执行 连接ZooKeeper,读取相应的Consumer、Topic配置信息等 通过consumerConnector连接到Kafka集群,收取指定topic的数据 创建KafkaMessageHandler线程池来对数据进行处理,通过ReceiverInputDStream中的方法,将数据转换成BlockRDD,供后续计算 2、 KafkaUtils.createDirectStream 执行流程如下: 实例化KafkaCluster,根据用户配置的Kafka参数,连接Kafka集群 通过Kafka API读取Topic中每个Partition最后一次读的Offset 接收成功的数据,直接转换成KafkaRDD,供后续计算
二者区别?: 1.简化的并行:在Receiver的方式中是通过创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
2.高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
3.精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。 |
- Spark如何和mysql对接?
| 实例化Properties,调用put方法,根据用户配置的mysql的参数填写put方法的参数,编写jdbc的链接的URL的信息,使用实例化的SQLContext调用read的jbdc方法,生成一个DataFrame ,供后续计算 |
- Sparkstreaming数据写入mysql用的什么算子?为什么不用mappartition?
| forearchpartition中建立数据库连接:这样一个partition,只需连接一次外部存储。性能上有大幅度的提高,一个partition共享连接,还有重要的一点就是partition中传入的参数是整个partition数据的迭代器。 mappartition该函数只适用于元素为KV对的RDD。 |
- 用过spark和kafka组合吗?Spark阻塞了,是什么原因导致的?
| spark streaming虽然是按照时间片消费数据的,但是上一个批次的数据没有处理完,下一个批次也会继续处理,如果有很多批次的数据同时在处理。会拖垮集群,服务器的资源会使用频繁,导致很慢,甚至任务阻塞。 看看时间片是否过小,最小的时间间隔,参考在0.5~2秒钟之间。可以适当放宽时间片的大小。 |
- storm与sparkstraming的优缺点
| 1.Storm是纯实时的,Spark Streaming是准实时的 2.Storm的事务机制、健壮性、容错性、动态调整并行度特性,都要比Spark Streaming更加的优秀 3.但是SparkStream, 有一点是Storm绝对比不上的,就是:它位于Spark生态技术中,因此Spark Streaming可以和Spark Core、Spark SQL无缝集合,也就意味这,我们可以对实时处理出来的数据,立刻进行程序中无缝的延迟批处理,交互式查询等条件操作 |
- Scala隐式转换
| Scala中的隐式转换是一种非常强大的代码查找机制。当函数、构造器调用缺少参数时或者某一实例调用了其他类型的方法导致编译不通过时,编译器会尝试搜索一些特定的区域,尝试使编译通过。
触发时机: 1)当一个对象去调用某个方法的时候,不具备这个方法 2)当某个对象去调用某个方法,但是传入的参数类型不匹配 3)A <% B // <% 是把A类型转化成B类型的意思 A必须是B的子类,但是如果A如果不是B的子类,那么这个时候会触发隐式转换,把A变为B的类型
①在Scala当中,要想使用隐式转换,必须标记为implicit关键字,implicit关键字可以用来修饰参数(隐式值与隐式参数)、函数(隐式视图)、类(隐式类)、对象(隐式对象). ②隐式转换在整个作用域中,必须是单一的标识符,进而避免隐式冲突. ③在隐式转换的作用域查找中,如果当前作用域没有隐式转换,编译器就会自动到相应源或目标类型的伴生对象中查找隐式转换。 ④Scala中的隐式值、隐式类、隐式对象常放在单例对象object中. |
- Scala高级函数
| 可以使用其他函数作为参数,或者使用函数作为输出结果,会自动类型推断,比如 map、foreach |
- Spark整合Hive
| 1.添加对应jar包依赖 2.集群上启动 hivesever2 服务 nohup hiveserver2 1>/dev/null 2>/dev/null & 或者 metastore 服务 metastore需要添加如下配置:
开启服务:nohup hive --service metastore 1>/dev/null 2>/dev/null & 3.将hive-site.xml放进classpath 4.sparkSession=SparkSession.builder().master("local").appName("testhive").enableHiveSupport().getOrCreate() //一定要调用一下enableHiveSupport() |
- (重要)手写 spark 求 π、wordcount、二次排序
| 必须会!!! |
综合
- 说说你熟悉的大数据组件及用处
| HDFS:Hadoop 的分布式文件存储系统 MapReduce:Hadoop 的分布式程序运算框架,也可以叫做一种编程模型 Hive:基于 Hadoop 的类 SQL 数据仓库工具 HBase:基于 Hadoop 的列式分布式 NoSQL 数据库 ZooKeeper:分布式协调服务组件 Mahout:基于 MapReduce/Flink/Spark 等分布式运算框架的机器学习算法库 Oozie/Azkaban:工作流调度引擎 Sqoop:数据迁入迁出工具 Flume:日志采集工具 |
- CDH,HDP,Apache三大hadoop发行商的区别以及优缺点
| Apache: 优点: 完全开源免费。 社区活跃 文档、资料详实 缺点: ----复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。 ----复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。 ----复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。 ----复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
CDH,HDP HDP版本是比较新的版本,目前与apache基本同步,因为Hortonworks内部大部分员工都是apache代码贡献者,尤其是Hadoop 2.0的贡献者。CDH对Hadoop版本的划分非常清晰,CDH文档清晰,很多采用Apache版本的用户都会阅读cdh提供的文档,包括安装文档、升级文档等。 优点: ----基于Apache协议,100%开源。 ----版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。 ----比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。 ----版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。 ----基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch ----提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。 ----运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点: ----涉及到厂商锁定的问题 |
- 如果每小时1000万数据量,需要按分钟或者按小时实现查询。做架构设计
| 每小时1000w,分配到每一秒也就是3000QPS左右,普通的数据库都是可以做到的,比如redis、hbase、es都可以,如果是每小时存储1000w,那么一天就是2.4亿,QPS达到7w,注意,是在这2.4亿中进行查询的,这个时候,数据库查询和存储压力都很大,使用hdfs显然不可以,可以考虑使用redis、hbase、es、ignite,以hbase为例,需要尽可能优化数据的查询方式,也就是rowkey设计。 |
- 最初收集日志的时候,收集到的日志都是杂乱无章的,如何来获取到你想要的数据?
| 需要进行数据的清洗和处理的操作,可以通过shell脚本的方式或是通过SparkStreaming进行实时的数据清洗和处理,从而来获得自己想要的数据 |
- 一个完整的日志处理的业务流程是怎样的?画图描述。
| 通过前端写的数据埋点从而获取到用户相关的日志信息,通过Nginx服务器获取相应的信息日志数据,如果才是的是实时的话可以通过kafka实时的拉取数据,然后中间进行一些需求的实现或是操作,如果是离线的话可以通过flume拉取在Nginx服务器上获取的日志信息数据,存储到hdfs上,然后再进行处理和分析等操作 |
- 对于处理好的数据,如何进行数据可视化?
| 可以把处理好的数据存储到hive上,通过sqoop数据迁移工具把数据迁移到mysql上,然后通过jdbc的操作和ssm的整合进行可视化的效果展示 |
- 对用户画像的理解
| 用户画像的本质就是根据用户行为数据对用户打上各种维度的标签,这些标签的集合就是用户画像,构建用户画像分为3步: 1) 基础数据收集(网络行为数据、用户内容偏好数据、用户交易数据等) 2) 行为建模(技术手段:各种机器学习算法) 3) 构建画像(基本属性、购买力、兴趣爱好等) |
********************项目部分************************
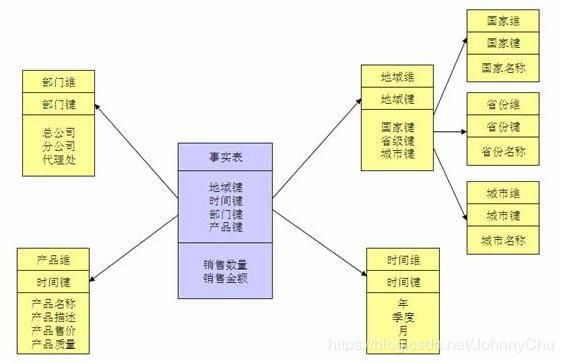
- 你们数据仓库是怎么设计的,hdfs,hive,hbase之间是怎么导数据的,怎么实现自动化?
| 参考1: 数据仓库是分5层架构(Buffer采集缓冲层、ODS临时存储层、DW数据仓库层、DM数据集市层、APP数据应用层)按照子主题,采用事实表+维度拉链进行设计的,数据导入主要用sqoop和flume 使用 hue + oozie 配合实现自动化 |
| 参考2: 上游把数据文件放在hdfs上,然后我们先建外表,再建内表,然后主题加工进主题表,然后再导出到hdfs上,再由入hbase程序(公司大牛写的)入到hbase下游就能调了。 每天晚上固定时间通过oozie定时执行脚本。 |
- 数据仓库有多少张表,怎么建的表,数据在hdfs中是怎么存储的,每天有多少数据加入,你们又是怎么存的?每天,每小时数据量有多大?业务有多少张表?
| 参考1: 数据仓库约400+以上表 主要是ods层临时表+dw层事实表维度表+DM层聚合表 建表按照主题依据缓慢渐变SCD3 设计的维度表,然后依照维度表抽取聚合形成主题事实表 数据在hdfs上是列式存储的 每天新增数据量大约40余万条,记录是按照周期增量导入方式存储,可以依据不同的需求,采用时间分区表 每天新增1个G左右的数据,平均每小时40M,高峰期每小时200M 业务表总共600多张 其中常用的约260多张 |
| 参考2: 我们公司业务表有2987张业务表。通过flume拉取数据存入HDFS按照每天时间做后缀的目录中。每天700万-900万条新增数据。 |
- 数据怎么来的?
| 数据来源主要是 运营数据库数据 用户行为埋点日志解析数据 、数据挖掘建模分析的结果数据、爬虫数据 |
- 工作中遇到过什么问题?
| 参考1: 数据数据抽取、清洗、hive中拆分为星型模型的事实表维度表以及向应用数据库导出时总共会运行约1800多个job 。如何有效的完成集群资源调度,避免因为任务并行造成的资源死锁。还有的难点是如何实现运营数据--行为采集数据--爬虫数据--挖掘数据之间的交叉合并分析以及调度 |
| 参考2: 前一段时间遇到过一个表中某一个字段的内容全是解析的网页数据带有各种html标签,但是都是文本格式的,不是html的。没办法将数据按照业务要求保存到不同字段。最后同过java代码过滤掉各种标签,然后jdbc将解析出的不同标签的数据内容保存到新表的不同字段。通过for循环执行jdbc的sql语句时,造成了OOM。才发现只有执行最后一个sql语句的时候,引用对象才会被关闭,前面的都没有被关闭所以才造成了内存溢出。 |
- 公司的cpu,内存设置是怎么样的?
| 参考1: 租用了6台阿里云服务器 CPU:Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz,内存64G |
| 参考2: 联通: IBM,联想,戴尔,浪潮等等 20+2硬盘 = 20盘作为数据盘 + 2硬盘 操作系统使用 每个盘 1 个T 4个CPU 每个CPU 8 个 Core = 32 Core 128G内存 Namenode:256G内存 Contos 6
58同城: 浪潮(性价比不错) 1T * 8 盘(7200转)机械硬盘 128G内存 2个cpu 每个CPU 8 个 Core Centos 7 |
- 长时间运行发生oom后如何解决?如何定位到出错是由内存泄漏引起的?
| OOM主要分三类: permgen OOM , heap OOM, stack overflow permgen OOM: 这个主要是由于加载的类太多,或者反射的类太多,还有调用 String.intend(jdk7之前)也会造成这个问题。所以出现了这个问题,就检查这三个方面; heap OOM:可通过命令定期抓取heap dump 或者启动参数OOM时自动抓取heap dump,主要是因为一些无用对象没有及时释放造成的,检查代码加上 heap dump 去分析吧; stack overflow: 这个主要是由于调用层数,或者递归深度太大造成的,看异常信息,基本上就能定位得出来了。 一般的如果是内存溢出导致的错误的话,在日志文件都能看出来,具体要看是哪一块出现问题,通过一些JVM监控工具(推荐yourkit):通过监控资源和调用栈,以及可以查看该进程的maps表,看进程的堆或mmap段的虚拟地址空间是否持续增加。如果是,说明可能发生了内存泄漏。如果mmap段虚拟地址空间持续增加,还可以看到各个段的虚拟地址空间的大小,从而可以确定是申请了多大的内存。 |
- 设计一个抽奖系统,尽量完整的画出系统服务端架构图,考虑高并发场景时用户请求的响应速度
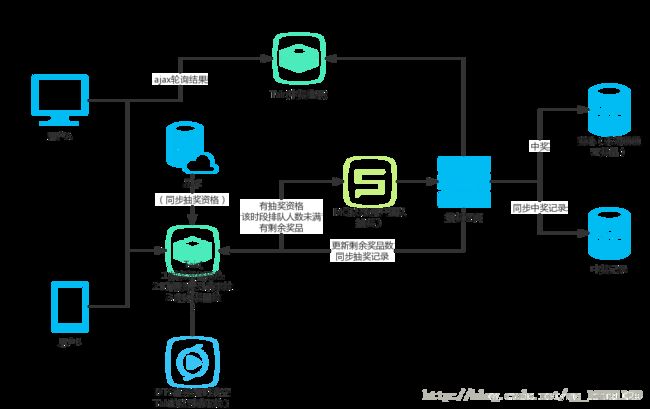
| 一. 项目思考 由于项目发起了一个抽奖活动,发起活动之前给所有用户发短信提示他们购买了我们的产品有抽奖权益。然后用户上来进入抽奖页面点击爆增,过了一会儿页面就打不开了。后面查看了下各种日志,发现了瓶颈在数据库,由于读写冲突严重,导致响应变慢,有不少连接都超时了。后面看到监控和日志留下的数据,发现负责抽奖的微服务集群qps暴涨12倍,db的qps也涨了10倍。这很明显是一个高并发下如何摆脱数据库读写,I/O瓶颈的问题。 整点开抢后瞬时巨量的请求同时涌入,即使我们Nginx端做过初步限流,整个业务逻辑校验阶段运作良好,但是系统的瓶颈就转移到其他环节:大量的读写请求,导致后面的请求全部排队等待,等前面一个update完成释放行锁后才能处理下一个请求,大量请求等待,占用了数据库的连接!一旦数据库同一时间片内的连接数被打满,就会导致这个时间片内其他后来的全部请求因拿不到连接而超时,导致访问此数据库的其他环节也出现问题!所以RT就会异常飙高! 于是我们在思考着怎么优化这个高并发下的抽奖问题 二. 优化思路 听了经验丰富的师兄的经验,也借鉴了下网上的一些思路,能采用的有效措施主要是:降级,限流,缓存,消息队列。主要原则是:尽量不暴露db,把大部分请求在服务的系统上层处理了。 三. 优化细节 1. 抽奖详情页 a. 线上开启缓存 线上已写缓存逻辑,但是没有用switch开启。开启后可以减少数据库的并发IO压力,减少锁冲突。 b. 关于本地缓存淘汰策略的细节处理 缓存超过或等于限制大小全部清空。建议等于时不清空,而使用缓存淘汰算法:比如LRU,LFU,NRU等,这样不会出现缓存过大清空后,从数据库更新数据到缓存,缓存里数据依旧很大。导致缓存清空频率过高,反而降低系统的吞吐量。例如guava cache中的参数是 //设置缓存容器的初始容量为10 initialCapacity(10) //设置缓存最大容量为100,超过100之后就会按照LRU最近虽少使用算法来移除缓存项 maximumSize(100) 2. 抽奖逻辑 a.队列削峰 用额外的单进程处理一个队列,下单请求放到队列里,一个个处理,就不会有qps的高并发问题了。场景中抽奖用户会在到点的时间涌入,DB瞬间就接受暴击压力,hold不住就会宕机,然后影响整个业务。队列的长度保持固定,对于如果请求排队在队伍中靠后,比如奖品100个的情况下,中奖率10%,队列里请求任务超过1000时,就直接将后续的抽奖请求返回不中奖。用tair记录排队数,如果奖品没发完,再请空tair,允许请求继续入队列。这样队列起到了降级和削峰的作用。 b.将事务和行级悲观锁改成乐观锁 原来的代码是通过悲观锁来控制超发的情况。(比如一共有100个商品,在最后一刻,我们已经消耗了99个商品,仅剩最后一个。这个时候,系统发来多个并发请求,这批请求读取到的商品余量都是99个,然后都通过了这一个余量判断,最终导致超发。) 在原来的代码中用的是for update行锁,在高并发的情况下会很多这样的修改请求,每个请求都需要等待锁,某些线程可能永远都没有机会抢到这个锁,这种请求就会死在那里。同时,这种请求会很多,瞬间增大系统的平均响应时间,结果是可用连接数被耗尽,系统陷入异常。 可以采用乐观锁,是相对于“悲观锁”采用更为宽松的加锁机制,大都是采用带版本号(Version)更新。实现就是,这个数据所有请求都有资格去修改,但会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。 c.对于与抽奖无直接关系的流程采用异步 比如抽奖成功之后的发短信功能另起一个线程池专门处理。这样可以提高请求的处理速率,提高qps上升后的乘载能力。 d.数据库的读写分离 现在的数据库查询都是读的主库。将数据库的大量查询改为从库,减轻主库的读写压力。主服务器进行写操作时,不影响查询应用服务器的查询性能,降低阻塞,提高并发。 e.同一时间片内,采用信号量机制 确保进来的人数不会过多导致系统响应超时: 信号量的采用,能够使得抽奖高峰期内,同一时间片内不会进入过多的用户,从底层实现上规避了系统处理大数据量的风险。这个可以配合队列进行限流处理。 f. 消息存储机制 将数据请求先添加到信息队列中(比如Tair存储的数据结构中),然后再写工具启动定时任务从Tair中取出数据去入库,这样对于db的并发度大大降低到了定时任务的频率。但是问题可能会出在保持数据的一致性和完整性上。 g.必要时候采用限流降级的测流 当并发过多时为了保证系统整体可用性,抛弃一些请求。对于被限流的请求视为抽不到奖。 3.额外考虑 a.防止黑客刷奖 防止黑客恶意攻击(比如cc攻击)导致qps过高,可以考虑策略在服务入口为相同uid的账户请求限制每秒钟的最高访问数。 b. 中奖数据预热 中奖只是少数,大部分人并不会中奖,所以可以在第一步便限制只有少数用户的请求能够打到真正抽奖逻辑上。是否可以考虑在抽奖之前先用随机算法生成一批中奖候选人。然后当用户请求过来时如果其中绝大多数请求都非中奖候选人,则直接返回抽奖失败,不走抽奖拿奖品的流程。少部分用户请求是中奖候选人,则进入队列,排在队列前面的获得奖品,发完为止,先到先得。 举个例子:10万个用户抽奖,奖品100个,先随机选出中奖候选人500个。用户请求过来时,不走抽奖查库逻辑的用户过滤掉99500个,剩余的候选人的请求用队列处理,先到先得。这样可以把绝大多数的请求拦截在服务上游不用查库,但是缺点是不能保证奖品一定会被抽完(可能抽奖候选人只有不到100人参与抽奖)。 四.设计架构图:
|
- 请简要描述你对数据仓库中星型结构的理解?
| 在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。 当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型,如下图1。 星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
图1. 销售数据仓库中的星型模型 当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。它的优点是: 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
图2. 销售数据仓库中的雪花型模型 星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。 使用选择星形模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中常用到的两种方式,而它们之间的对比要从四个角度来进行讨论。 数据优化雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。 相比较而言,星形模型实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。 业务模型主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID将是Account_dimension的一个外键。 在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。 性能第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。 而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将Advertiser的维度表和事实表连接即可。 ETL雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。 星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。 总结雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”
|

1、java面向对象的三大特征是什么?
2、jvm垃圾回收机制
3、进程和线程的区别:
4、排序算法你会多少种,时间复杂度和稳定性是怎样的?怎样判定稳定性?
5、HashMap的底层原理:
6、红黑树的原理:
7、hive的原理:
8、zookeeper的原理,数据一致性怎样保证
9、java怎样创建一个线程池:
10、接口和类的区别:
11、js的闭包是什么
12、mysql为什么有索引,底层原理是什么?
13、hbase的原理
14、sqoop原理:
15、flume的原理以及能有什么用
16、MapReduce的原理和过程
17、高可用的理解
18、怎样设置maptask和reducetask的个数
19、HashMap是线程安全的吗?什么是线程安全?
20、代码实现怎样判断一棵树是否是平衡二叉树
21、代码实现获取单链表的倒数第k个元素
22、100G的数据怎样获取单词出现次数最多的前100个
23、数组、链表、队列、堆栈的区别
24、rdd是什么
25、tcp和upd的区别:
26、tcp的三次握手请求原理
27、get和post的区别:
28、http的方法有get,post,还有哪些?
29、客户端能否自行断开与服务器的连接?
30、js怎样实现跨域进行数据传输,什么是跨域?
31、怎样实现负载均衡?
32、什么是数据倾斜,怎样解决数据倾斜的问题
33、java可以继承吗?接口可以多继承吗?