Spark2.x详解
Spark2.x
- 1.Spark初始
- 1.1: 什么是Spark
- 1.2: Spark与mapreduce的区别
- 2.SparkCore
- 2.1: RDD
- 2.2 : Spark任务执行原理
- 2.3:代码流程
- 2.4: Transformations转换算子
- 2.5:Action行动算子
- 2.6:控制算子
- 3.Spark2.x安装
- 3. 1:下载安装包
- 3.2: 解压并改名
- 3.3:配置slaves文件
- 3.4:配置spark-env.sh文件
- 4: YARN模式运行
- 4.1: yarn-client提交任务方式
- 4.1.1: 提交命令:
- 4.1.2: 执行流程图
- 4.1.3: 执行流程
- 4.2:yarn-cluster提交任务方式
- 4.2.1: 提交命令
- 4.2.2: 执行流程图
- 4.2.3: 执行流程
- 4.3:ApplicationMaster的作用
- 4.4: 术语解释
- 5.窄依赖和宽依赖
- 5.1: 窄依赖
- 5.2: 宽依赖
- 6.Stage
- 6.1: stage详解
- 6.2:stage计算模式(pipeline)
- 7.Spark资源调度和任务调度
- 7.1: 资源调度和任务调度流程
- 7.2: 图解
- 7.3: 粗粒度资源申请(Spark)
- 7.4: 细粒度资源申请(MapReduce)
- 8:广播变量和累加器
- 8.1:广播变量
- 8.1.1: 理解图
- 8.1.2:广播变量使用
- 8.1.3:注意事项
- 8.2: 累加器
- 8.2.1: 理解图
- 8.2.2: 累加器使用
- 8.2.3: 注意事项
- 9: SparkShuffle
- 9.1: 概念
- 9.2: HashShuffle
- 9.2.1: 普通机制
- 9.2.2: 合并机制(Hash优化机制)
- 9.2: SortShuffle
- 9.2.1: 普通机制
- 9.2.1: bypass机制
- 9.3: Shuffle寻址
- 10: Spark内存管理
- 10.1: 静态内存管理
- 10.1: 统一内存管理
1.Spark初始
1.1: 什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所 具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark是Scala编写,方便快速编程。
1.2: Spark与mapreduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序
2.SparkCore
2.1: RDD
-
概念: RDD弹性分布式数据集
-
RDD的五大特性
1.RDD是由一系列的partition组成
2.算子是作用在partition上面
3.RDD之间有依赖关系
4.分区器是作用在(K,V)格式的RDD
5.partition对外面提供最佳的计算位置

默认子RDD的分区数(partition)是和父RDD的分区数相同
2.2 : Spark任务执行原理

上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程
- Driver与集群节点之间有频繁的通信
- Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom
- Worker是Standalone资源调度框架里面资源管理的从节点
- Master是Standalone资源调度框架里面资源管理的主节点
2.3:代码流程
-
创建SparkConf对象:可以设置Application name,可以设置运行模式及资源需求
-
创建SparkContext对象
-
基于Spark的上下文创建一个RDD,对RDD进行处理
-
应用程序中要有Action类算子来触发Transformation类算子执行
-
关闭Spark上下文对象SparkContext
object WordLines { def main(args: Array[String]): Unit = { //local为本地运行模式 val conf = new SparkConf().setMaster("local").setAppName("word") val sc = SparkSession.builder().config(conf).getOrCreate().sparkContext val count = sc.longAccumulator("longAccumulator") val rdd = sc.parallelize(Array(1,2,3,4,5,6,7)) //collect为Aciton算子 rdd.map(line =>{ count.add(1L) line }).collect() println(count.value) sc.stop() } }
2.4: Transformations转换算子
- 概念: Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行,
需要Action算子触发才能运行 - 常用Transformations算子
2.5:Action行动算子
-
概念:Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是
触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行 -
常用Action算子
2.6:控制算子
- 概念: 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,
持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系
cache() 默认将数据缓存在内存中,懒执行算子 需要action算子触发
persist() 手动指定持久化级别,懒执行算子 需要action算子触发
persist(StorageLevel.MEMORY_ONLY) = cache()=persist()

注意:
- 1.cache和persist都是懒执行 需要action算子触发
- 2.对于一个RDD cache 或者 persisit之后可以赋值给一个变量 下次使用之歌变量就是使用持久化rdd
- 3.如果赋值给一个变量 那么cache和persist之后不能紧跟Action算子 如 rdd = rdd.persist().collect()
checkpoint() 懒执行算子 需要action算子触发
- 1)将数据存到磁盘
- 2)切断rdd的联系
- 3)persist(StorageLevel.DISK_ONLY)程序运行完,磁盘文件就被清除,而checkpoin不会
cache persist checkpoint 持久化单位是partition
object Cache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("cache")
val sc = new SparkContext(conf)
//指定checkpoint的磁盘文件存储位置
sc.setCheckpointDir("file:///home/checkpoint")
var rdd: RDD[String] = sc.textFile("")
rdd.checkpoint()
rdd.collect()
rdd = rdd.cache()
rdd = rdd.persist(StorageLevel.DISK_ONLY)
sc.stop()
}
}
3.Spark2.x安装
3. 1:下载安装包
wget https://www-us.apache.org/dist/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
3.2: 解压并改名
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
mv spark-2.3.2-bin-hadoop2.7 spark
3.3:配置slaves文件
cd spark/conf
cp slaves.template slaves
因为我们配置的是单机的,所以可以不用修改,默认就是localhost
3.4:配置spark-env.sh文件
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加以下内容:
export SCALA_HOME=/home/twl/scala/scala-2.12.6
export JAVA_HOME=/home/twl/jdk
export HADOOP_HOME=/home/twl/app/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/twl/app/spark
export SPARK_MASTER_IP=localhost
export SPARK_EXECUTOR_MEMORY=1G
到此已经可以开始你的表演了(要启动Hadoop环境)
4: YARN模式运行
4.1: yarn-client提交任务方式
4.1.1: 提交命令:
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi
--master yarn
lib/spark-examples*jar 10
4.1.2: 执行流程图
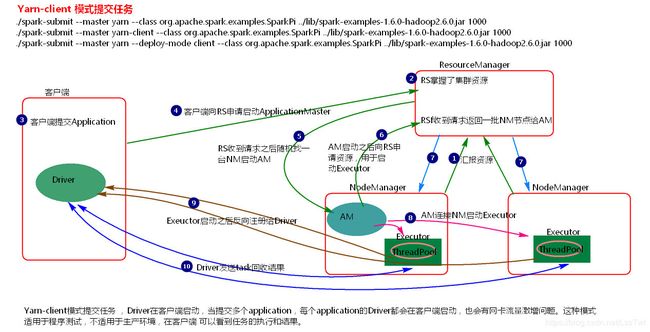
4.1.3: 执行流程
- 1.客户端提交一个Application,在客户端启动一个Driver进程。
- 2.应用程序启动后会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
- 3.RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的****Worker节点
- 4.AM启动后,会向RS请求一批container资源,用于启动Executor.
- 5.RS会找到一批NM返回给AM,用于启动Executor。
- 6.AM会向NM发送命令启动Executor。
- 7.Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
总结:
Yarn-client模式同样是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
4.2:yarn-cluster提交任务方式
4.2.1: 提交命令
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
lib/spark-examples*jar 10
4.2.2: 执行流程图

4.2.3: 执行流程
- 1.客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)
- 2.RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)
- 3.AM启动,AM发送请求到RS,请求一批container用于启动Executor
- 4.RS返回一批NM节点给AM
- 5.AM连接到NM,发送请求到NM启动Executor
- 6.Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor
总结
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志
4.3:ApplicationMaster的作用
-
1.为当前的Application申请资源
-
2.给NameNode发送消息启动Excutor
-
3.任务调度
ApplicationMaster详解
4.4: 术语解释

5.窄依赖和宽依赖
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖
5.1: 窄依赖
概念: 父RDD和子RDD partition之间的关系是
一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生
5.2: 宽依赖
父RDD与子RDD partition之间的关系是
一对多。会有shuffle的产生


6.Stage
6.1: stage详解
Spark任务会根据RDD之间的依赖关系,形成一个
DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行
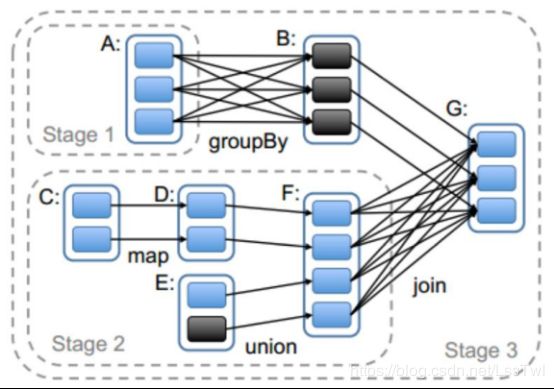
6.2:stage计算模式(pipeline)
pipeline管道计算模式,pipeline只是一种计算思想,模式

每个task相当于执行了一个高阶函数,f3(f2(f1(sc.textFile("…")))),
数据是一条一条地读取,读取一条就落地,而mapreduce是读完再落地
Mapreduce相当于是: 1+1=2 ;2+1=3
Spark是 1+1+1 = 3
数据一直在管道里面什么时候数据会落地?
- 1.对RDD进行持久化
- 2.shuffle write的时候
Stage的task
并行度是由stage的最后一个RDD的分区数来决定的
如何改变RDD的分区数?
例如:reduceByKey(XXX,3),GroupByKey(4)
测试验证pipeline计算模式
val conf = new SparkConf()
conf.setMaster("local").setAppName("pipeline");
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3,4))
val rdd1 = rdd.map { x => {
println("map--------"+x)
x
}}
val rdd2 = rdd1.filter { x => {
println("fliter********"+x)
true
} }
rdd2.collect()
sc.stop()
可以看出数据是一条一条被读取再落地
7.Spark资源调度和任务调度
7.1: 资源调度和任务调度流程
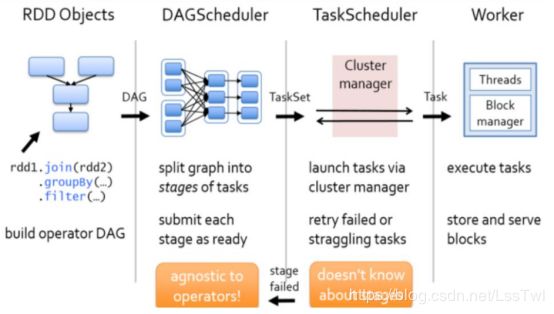
- 1:启动集群后,Worker节点会向Master节点汇报资源情况,Master掌握了集群资源情况
- 2:当Spark提交一个Application后,根据RDD之间的依赖关系将Application形成一个DAG有向无环图
- 3:任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,DAGScheduler是任务调度的高层调度器,是一个对象
- 4:DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage
- 5:然后将这些Stage以TaskSet的形式提交给TaskScheduler(TaskScheduler是任务调度的低层调度器,这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务)
- 6:TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)
- 7:task在Executor线程池中的运行情况会向TaskScheduler反馈
- 8;当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了
- 9:stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了
TaskScheduler不仅能重试失败的task,还会重试straggling(落后,缓慢)task(也就是执行速度比其他task慢太多的task)
如果有运行缓慢的task那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过spark.speculation属性来配置
注意:
- 对于ETL类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
- 如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态
7.2: 图解

7.3: 粗粒度资源申请(Spark)
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源
-
优点: 在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了
-
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用
7.4: 细粒度资源申请(MapReduce)
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源
- 优点:集群的资源可以充分利用
- 缺点:task自己去申请资源,task启动变慢,Application的运行就相应的变慢了
8:广播变量和累加器
8.1:广播变量
8.1.1: 理解图

8.1.2:广播变量使用
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
8.1.3:注意事项
- 1. 能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去 - 2. 广播变量只能在Driver端定义,不能在Executor端定义
- 3. 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值
8.2: 累加器
8.2.1: 理解图
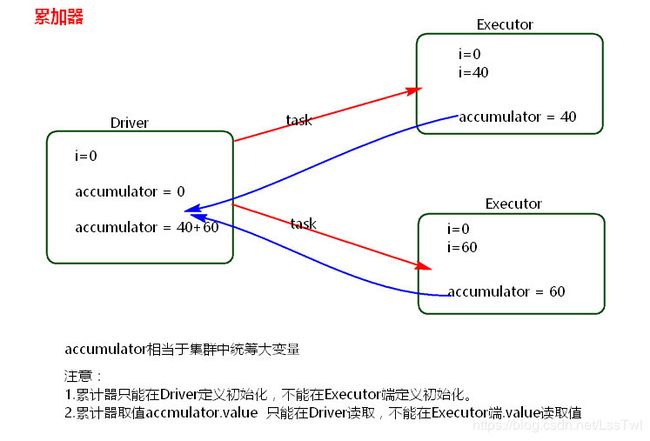
8.2.2: 累加器使用
val conf = new SparkConf().setMaster("local").setAppName("word")
val sc = SparkSession.builder().config(conf).getOrCreate().sparkContext
val count = sc.longAccumulator("longAccumulator")
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7))
rdd.map(line =>{
count.add(1L)
line
}).collect()
println(count.value)
sc.stop()
8.2.3: 注意事项
- 累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新
9: SparkShuffle
Hash Shuffle是Spark 1.2之前的默认Shuffle实现,并在Spark 2.0版本中被移除,因此,了解Hash Shuffle的意义更多的在于和Sort Shuffle对比,以及理解为什么Sort Shuffle能够完全取代Hash Shuffle
9.1: 概念
Shuffle就是在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低对数据进行重组
9.2: HashShuffle
9.2.1: 普通机制

执行流程(Spark中时不存在map reduce,只是流程和Hadoop相似,以下出现是为了形象解释而以)
- 1: 每一个map task将不同结果写到不同的buffer中,每个buffer的大小为
32K。buffer起到数据缓存的作用 - 2: 每个buffer文件最后对应一个磁盘小文件
- 3: reduce task来拉取对应的磁盘小文件
产生的磁盘小文件的个数: M(map task的个数)*R(reduce task的个数)
存在的问题
- 1: 在Shuffle Write过程中会产生很多写磁盘小文件的对象
- 2: 在Shuffle Read过程中会产生很多读取磁盘小文件的对象
- 3: 在JVM堆内存中对象过多会造成频繁的gc,gc还无法解决运行所需要的内存 的话,就会OOM
- 4: 在数据传输过程中会有频繁的网络通信,频繁的网络通信出现通信故障的可能性大大增加,一旦网络通信出现了故障会导致shuffle file cannot find 由于这个错误导致的task失败,TaskScheduler不负责重试,由DAGScheduler负责重试Stage
9.2.2: 合并机制(Hash优化机制)

每一个Executor进程根据核数,决定Task的并发数量,比如executor核数是2,就是可以并发运行两个task,如果是一个则只能运行一个task
假设executor核数是1,ShuffleMapTask数量是M,那么它依然会根据ResultTask的数量R,创建R个bucket缓存,然后对key进行hash,数据进入不同的bucket中,每一个bucket对应着一个block file,用于刷新bucket缓存里的数据
产生磁盘小文件的个数:C(core的个数)*R(reduce的个数)
9.2: SortShuffle
9.2.1: 普通机制

执行流程:
- a) map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M
- b) 在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。
- c) 如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。
- d) 在溢写之前内存结构中的数据会进行排序分区
- e) 然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据,
- f) map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件,同时生成一个索引文件。reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据
产生磁盘小文件的个数: 2*M(map task的个数)
9.2.1: bypass机制

bypass运行机制的触发条件如下:
shuffle reduce task的数量小于spark.shuffle.sort.bypassMergeThreshold的参数值。这个值默认是200
产生的磁盘小文件为:2*M(map task的个数)
9.3: Shuffle寻址

Shuffle文件寻址流程
- a)当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MpStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
- b)在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
- c)在reduce task执行之前,会通过Excutor中MapOutPutTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
- d)获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的* ConnectionManager,然后通过BlockTransferService进行数据的传输。
- e) BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M
10: Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理;可以通过参数spark.memory.useLegacyMode 设置为true(默认为false)使用静态内存管理
10.1: 静态内存管理
存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置

10.1: 统一内存管理
与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以互相借用对方的空间

reduce 中OOM如何处理?
- 1)减少每次拉取的数据量
- 2)提高shuffle聚合的内存比例
- 3)提高Excutor的总内存