后台开发常见必备知识点
排序算法
//快速排序 划分算法
public int Partition(int A[], int low, int hight){
int pivot = A[low];
while (low < hight){
while (low < hight && A[hight] >= pivot) --hight;
A[low] = A[hight];
while (low < hight && A[low] <= pivot) ++low;
A[hight] = A[low];
}
A[low] = pivot;
return low;
}
public void QuickSort(int A[],int low,int hight){
if (low < hight){
int pivotpos = Partition(A, low, hight);
QuickSort(A, low, pivotpos - 1);
QuickSort(A, pivotpos + 1, hight);
}
}
//归并排序
public void MergeSort(int A[],int low,int hight){
if (low < hight){
int mid = (low + hight) / 2;
MergeSort(A, low, mid);
MergeSort(A, mid + 1, hight);
Merge(A, low, mid, hight);
}
}
public void Merge(int A[], int low, int mid, int hight){
int i,j,k;
int[] B = new int[A.length];
for (k = low;k <= hight; k++) B[k] = A[k]; //复制数组
for (i = low, j = mid+1, k = i; i <= mid && j <= hight; k++){
if (B[i] < B[j]) A[k] = B[i++];
else A[k] = B[j++];
}
while (i <= mid) A[k++] = B[i++];
while (j <= hight) A[k++] = B[j++];
}
//堆排序函数
public static void HeapSort(int[] arr) {
int n = arr.length - 1;
for(int i = (n - 1) / 2; i >= 0; i--) {
//构造大顶堆,从下往上构造
HeapAdjust(arr, i, n);
}
for(int i = n; i > 0; i--) {
//把最大的数,也就是顶放到最后
//i每次减一,因为要放的位置每次都不是固定的
swap(arr, i);
//再构造大顶堆
HeapAdjust(arr,0,i - 1);
}
}
//构造大顶堆函数,parent为父节点,length为数组最后一个元素的下标
public static void HeapAdjust(int[] arr, int parent, int length) {
int temp = arr[parent];
// 2 * parent + 1 是其左孩子节点
for(int i = parent * 2 + 1; i <= length; i = i * 2 + 1) {
//如果左孩子大于右孩子,就让i指向右孩子
if(i < length && arr[i] < arr[i+1]) {
i++;
}
//如果父节点大于或者等于较大的孩子,那就退出循环
if(temp >= arr[i]) {
break;
}
//如果父节点小于孩子节点,那就把孩子节点放到父节点上
arr[parent] = arr[i];
//把孩子节点的下标赋值给parent
//让其继续循环以保证大根堆构造正确
parent = i;
}
//将刚刚的父节点中的数据赋值给新位置
arr[parent] = temp;
}
//定义swap函数
//功能:将当前最大的元素放在数组的后面
public static void swap(int[] arr,int i)
{
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
}
Linux 常见文件夹和文件信息
https://blog.csdn.net/qq_17641711/article/details/78847447
面经出现的问题
Q: Redis数据类型有哪些?
A: String / List / Set / Hash / Order Set (ZSET)
Q: sorted set底层实现?
A: sorted set 有两种模式可以选择
//哈希表 + 跳表的组合模式
zobj = createZsetObject();
//ziplist(压缩链表)模式
zobj = createZsetZiplistObject();
- 扩展
- STRING 类型:
String类型在Redis底层可以是 int、raw、embstr
如果一个String对象保存的是整数值,并且可以使用long来表示,那么将会以整数形式保存。
如果一个String对象保存的是字符串值,并且其长度大于32字节,那么就直接使用SDS结构来保存,其encoding标记为raw。如果一个String对象保存的字符串长度小于32字节,那么会使用embstr编码,embstr是一种短字符串的优化,其存储还是使用SDS结构,但raw编码会调用两次内存分配函数来分别创建redisObject结构和SDS结构,而embstr编码则通过调用一次内存分配函数来分配 一块连续的空间,空间中依次包含redisObject和SDS结构。 - List类型: ziplist(压缩列表) 或 linkedlist(双向列表)。
- Hash类型: ziplist(压缩列表) 或 hashtable(Hash表)。
- Set 类型: intset(整数集合) 或 hashtable(Hash表)。
- Zset类型: ziplist(压缩列表) 或 skiplist(跳跃表)。
- 跳跃表 详见:https://www.cnblogs.com/acfox/p/3688607.html
Q: redis分布式锁实现?
A:
SETNX
SETNX key val
当且仅当 key 不存在时,set 一个 key 为 val 的字符串,返回1;
若key存在,则什么都不做,返回0。
expire
expire key timeout
为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
delete
delete key
删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
实现思想:
获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
上述方案存在产生死锁的可能,因此:
- 加锁过程:
锁的过期时间应设置到redis中,保证在加锁客户端故障的情况下锁可以被自动释放
使用set key value EX seconds NX命令进行加锁,不要使用setnx和expire两个命令加锁。
若setnx执行成功而expire失败(如执行setnx后客户端崩溃),则可能造成死锁。
锁记录的值不能使用固定值,应该设置为随机生成的UUID。 使用固定值可能导致严重错误: 线程A的锁因为超时被释放, 随后线程B成功加锁。 B写入的锁记录与A的锁记录没有区别, 因此A在检查时会误判为自己仍持有锁。 - 解锁过程:
解锁操作使用lua脚本执行get和del两个操作,为了保证两个操作的原子性。
若两个操作不具有原子性则可能出现错误时序:
线程A执行get操作判断自己仍持有锁 - 锁超时释放 - 线程B成功加锁
线程A删除锁记录(线程A认为删除了自己的锁记录,实际上删除了线程B的锁记录)。
注:Lua 脚本功能是 Reids 2.6 版本的最大亮点, 通过内嵌对 Lua 环境的支持, Redis 解决了长久以来不能高效地处理 CAS (check-and-set)命令的缺点, 并且可以通过组合使用多个命令, 轻松实现以前很难实现或者不能高效实现的模式。
Q: zk哪几种节点?
A:四种,分别是
持久节点(PERSISTENT)
顺序节点(PERSISTENT_SEQUENTIAL)
临时节点(EPHEMERAL)
临时顺序节点(EPHEMERAL_SEQUENTIAL)
Q: zk作用?
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
Zookeeper实现分布式锁:
锁服务可以分为两类,一个是保持独占,另一个是控制时序。
- 对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
- 对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
Q: 消息队列作用?
- 应用解耦、可恢复性
- 顺序保证
- 缓冲、流量削锋
- 异步处理
- 日志处理
Q: TCP Socket 缓冲区
知识点:应用程序可通过调用 send 利用 TCP Socket 向网络发送应用数据,而 tcp/ip 协议栈再通过网络设备接口把 TCP数据报 真正发送到网络上,由于应用程序调用send的速度跟网络介质发送数据的速度存在差异,所以,一部分应用数据被组织成 TCP数据报 之后,会缓存在 TCP Socket 的发送缓存队列双向链表中,等待网络空闲时再发送出去。同时,TCP 协议要求对端在收到 TCP数据报 后,要对其序号进行ACK,只有当收到一个 TCP数据报 的 ACK 之后,才可以把其从Socket 的发送缓冲队列中清除。
应用程序调用write()或send()时,仅仅是把应用程序buffer中的数据copy到socket的发送缓冲区中(write()或send()返回时,data并不一定已经发送到对端了),在适当的时机,内核会把socket发送缓冲区的数据发送到接收方的socket接受缓冲区。
接收方的应用程序调用read()或receve()时,仅仅是从接收方的socket接受缓冲区中把数据copy到应用程序的buffer中。如果应用程序一直没有调用read()读取的话,此数据会一直缓存在相应的socket的接收缓冲区。
Q: 进程调度策略有哪些
进程调度也是三级调度(高级作业调度、中级内存调度、低级进程调度)中的低级调度。 主要的策略有
- 进程调度
- FCFS 先来先服务
- SPF 短进程优先
- 优先级调度
- 时间片轮转法
- 多级反馈队列调度
- 作业调度算法有:
- FCFS 先来先服务
- SJF 短作业优先
- 优先级调度
- 高响应比优先
Q: Reactor模型 Proactor模型
I/O模型共有四类
(1)同步阻塞IO(Blocking IO):即传统的IO模型。

(2)同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java的NIO(New IO)库。

(3)IO多路复用(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
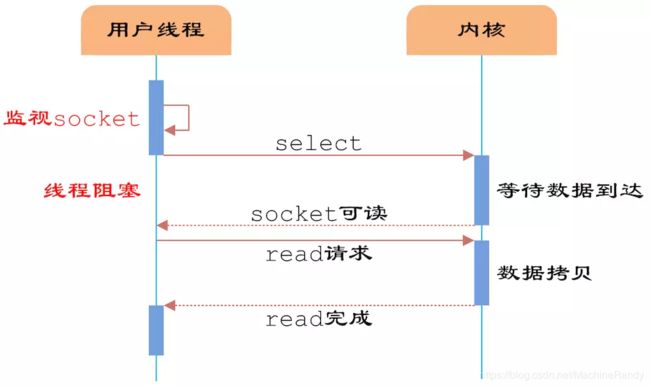
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。
但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。
而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。
IO多路复用模型使用了Reactor设计模式实现了这一机制。
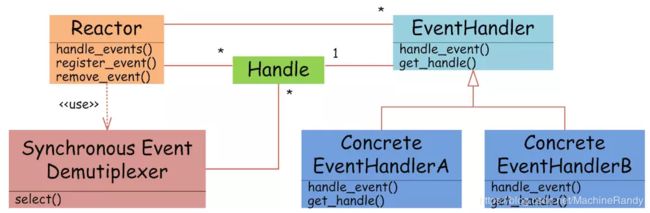
图4 Reactor设计模式
如图4所示,EventHandler抽象类表示IO事件处理器,它拥有IO文件句柄Handle(通过get_handle获取),以及对Handle的操作handle_event(读/写等)。继承于EventHandler的子类可以对事件处理器的行为进行定制。Reactor类用于管理EventHandler(注册、删除等),并使用handle_events实现事件循环,不断调用同步事件多路分离器(一般是内核)的多路分离函数select,只要某个文件句柄被激活(可读/写等),select就返回(阻塞),handle_events就会调用与文件句柄关联的事件处理器的handle_event进行相关操作。
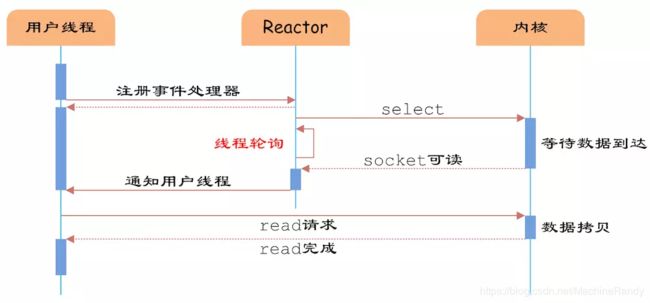
图5 IO多路复用
如图5所示,通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
(4)异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。

图6 Proactor设计模式
如图6,Proactor模式和Reactor模式在结构上比较相似,不过在用户(Client)使用方式上差别较大。Reactor模式中,用户线程通过向Reactor对象注册感兴趣的事件监听,然后事件触发时调用事件处理函数。而Proactor模式中,用户线程将AsynchronousOperation(读/写等)、Proactor以及操作完成时的CompletionHandler注册到AsynchronousOperationProcessor。AsynchronousOperationProcessor使用Facade模式提供了一组异步操作API(读/写等)供用户使用,当用户线程调用异步API后,便继续执行自己的任务。AsynchronousOperationProcessor 会开启独立的内核线程执行异步操作,实现真正的异步。当异步IO操作完成时,AsynchronousOperationProcessor将用户线程与AsynchronousOperation一起注册的Proactor和CompletionHandler取出,然后将CompletionHandler与IO操作的结果数据一起转发给Proactor,Proactor负责回调每一个异步操作的事件完成处理函数handle_event。虽然Proactor模式中每个异步操作都可以绑定一个Proactor对象,但是一般在操作系统中,Proactor被实现为Singleton模式,以便于集中化分发操作完成事件。
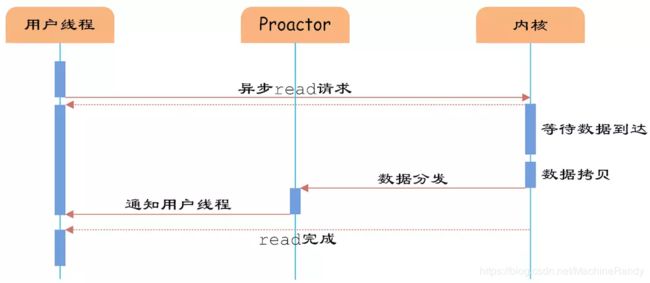
图7 异步IO
如图7所示,异步IO模型中,用户线程直接使用内核提供的异步IO API发起read请求,且发起后立即返回,继续执行用户线程代码。不过此时用户线程已经将调用的AsynchronousOperation和CompletionHandler注册到内核,然后操作系统开启独立的内核线程去处理IO操作。当read请求的数据到达时,由内核负责读取socket中的数据,并写入用户指定的缓冲区中。最后内核将read的数据和用户线程注册的CompletionHandler分发给内部Proactor,Proactor将IO完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步IO。
Q: 内核态和用户态的区别
内核态与用户态是操作系统的两种运行级别,当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核态,此时处理器处于特权级最高的(0级)内核代码中执行。
当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。
当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。
在内核态下,CPU可执行任何指令(包括 I/O、置中断、存取内存保护的寄存器等特权指令),在用户态下CPU只能执行非特权指令。当CPU处于内核态,可以随意进入用户态;而当CPU处于用户态,只能通过 中断、异常、系统调用或调用访管指令(非特权指令)的方式进入内核态。
Q: zk 和 paxos
Zookeeper使用了Zookeeper Atomic Broadcast(ZAB,Zookeeper原子消息广播协议)的协议作为其数据一致性的核心算法。
ZAB主要包括消息广播和崩溃恢复两个过程,进一步可以分为三个阶段,分别是发现(Discovery)、同步(Synchronization)、广播(Broadcast)阶段。ZAB的每一个分布式进程会循环执行这三个阶段,称为主进程周期。
-
发现(选主),选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈,PL产生newepoch(每次选举产生新Leader的同时产生新epoch)。
-
同步,PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)。
-
广播,Leader处理客户端的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)。
在正常运行过程中,ZAB协议会一直运行于阶段三来反复进行消息广播流程,如果出现崩溃或其他原因导致Leader缺失,那么此时ZAB协议会再次进入发现阶段,选举新的Leader。
Paxos 算法:
Paxos是一个基于消息传递的一致性算法。
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。
好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
好,我觉得Paxos的精华就这么多内容。现在让我们来对号入座,看看在ZK Server里面Paxos是如何得以贯彻实施的。
小岛(Island)——ZK Server Cluster
议员(Senator)——ZK Server
提议(Proposal)——ZNode Change(Create/Delete/SetData…)
提议编号(PID)——Zxid(ZooKeeper Transaction Id)
正式法令——所有ZNode及其数据
貌似关键的概念都能一一对应上,但是等一下,Paxos岛上的议员应该是人人平等的吧,而ZK Server好像有一个Leader的概念。没错,其实Leader的概念也应该属于Paxos范畴的。如果议员人人平等,在某种情况下会由于提议的冲突而产生一个“活锁”(所谓活锁我的理解是大家都没有死,都在动,但是一直解决不了冲突问题)。Paxos的作者Lamport在他的文章”The Part-Time Parliament“中阐述了这个问题并给出了解决方案——在所有议员中设立一个总统,只有总统有权发出提议,如果议员有自己的提议,必须发给总统并由总统来提出。好,我们又多了一个角色:总统。
总统——ZK Server Leader
联系:
① 都存在一个类似于Leader进程的角色,由其负责协调多个Follower进程的运行。
② Leader进程都会等待超过半数的Follower做出正确的反馈后,才会将一个提议进行提交。
③ 在ZAB协议中,每个Proposal中都包含了一个epoch值,用来代表当前的Leader周期,在Paxos算法中,同样存在这样的一个标识,名字为Ballot。
区别:
Paxos算法中,新选举产生的主进程会进行两个阶段的工作,第一阶段称为读阶段,新的主进程和其他进程通信来收集主进程提出的提议,并将它们提交。第二阶段称为写阶段,当前主进程开始提出自己的提议。
ZAB协议在Paxos基础上添加了同步阶段,此时,新的Leader会确保存在过半的Follower已经提交了之前的Leader周期中的所有事务Proposal。
ZAB协议主要用于构建一个高可用的分布式数据主备系统,而Paxos算法则用于构建一个分布式的一致性状态机系统。
Q: mysql高可用架构,relay log中保存什么?
简单的高可用架构:主从同步
主从复制同步的原理:
主从复制是MySQL数据库提供的一种高可用、高性能的解决方案,其实并不复杂,它不是完全的实时,其实是一种异步的实时过程,如果由于网络的原因延迟比较严重的时候,这时候要考虑将其延迟时间作为Nagios报警的选项参数,其具体工作步骤如下。
1)主服务器把数据更新记录到二进制日志中;
2)从服务器把主服务器的二进制日志复制到自己的中继日志中,这个由从服务器的I/O线程负责;
3)从服务器执行中继日志,把其更新应用到自己的数据库上,这个由从服务器的SQL线程负责。
relaoy log 记录了主节点发来的数据库变化信息,并且由 I/O thread 写入。之后 SQL thread 在备节点上执行 relay log 文件里的事件。
master info log 文件记录了备节点的连接信息,例如用户名,密码等信息。
relay log info log 文件记录了备节点应用 relay log 文件的进度情况。
Q: 一致性Hash
一致性哈希算法(Consistent Hashing Algorithm)是一种分布式算法,常用于负载均衡。
Memcached client也选择这种算法,解决将key-value均匀分配到众多Memcached server上的问题。它可以取代传统的取模操作,解决了取模操作无法应对增删Memcached Server的问题(增删server会导致同一个key,在get操作时分配不到数据真正存储的server,命中率会急剧下降)。
一般HASH 算法的缺点:容错性和扩展性不好。
所谓容错性是指当系统中某一个或几个服务器变得不可用时,整个系统是否可以正确高效运行;而扩展性是指当加入新的服务器后,整个系统是否可以正确高效运行。
现假设有一台服务器宕机了,那么为了填补空缺,要将宕机的服务器从编号列表中移除,后面的服务器按顺序前移一位并将其编号值减一,此时每个key就要按h = Hash(key) % (N-1)重新计算;同样,如果新增了一台服务器,虽然原有服务器编号不用改变,但是要按h = Hash(key) % (N+1)重新计算哈希值。因此系统中一旦有服务器变更,大量的key会被重定位到不同的服务器从而造成大量的缓存不命中。而这种情况在分布式系统中是非常糟糕的。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - (2^32)-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
整个空间按顺时针方向组织。0和(2^32)-1在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:
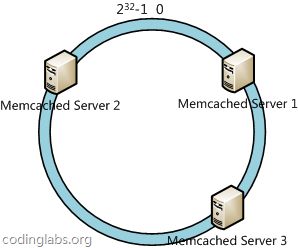
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
###3.2 容错性与可扩展性分析### 下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:
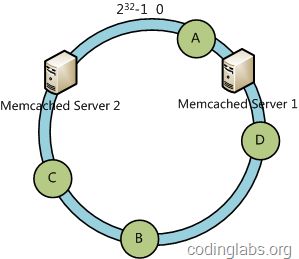
可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:
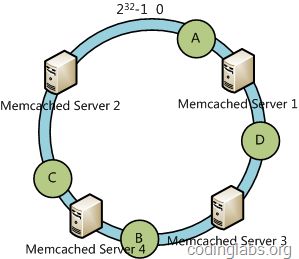
此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:
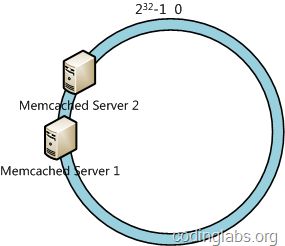
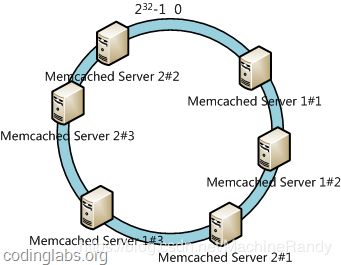
此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:
Q: 设计一个秒杀系统
http://www.cnblogs.com/diegodu/p/9244955.html
https://blog.csdn.net/CSDN_Terence/article/details/77744042
Q: 海量数据处理问题
https://blog.csdn.net/zailushang1708/article/details/38496993
https://blog.csdn.net/v_july_v/article/category/1106578
Q: CAP 与 最终一致性
一致性(Consistency)
可用性(Availability)
分区容忍性(Partition tolerance)
CAP原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性。
https://my.oschina.net/xianggao/blog/541003
Q: AVL 树 和 红黑树
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此AVL树适合用于插入与删除次数比较少,但查找多的情况。
红黑树是一种弱平衡二叉树(由于是弱平衡,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,用红黑树。
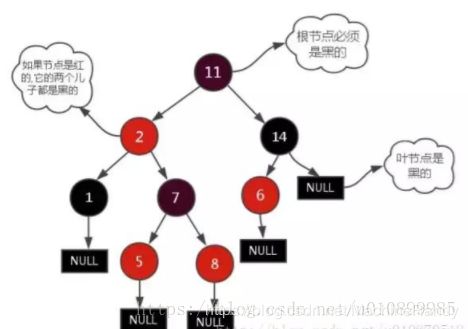
红黑树的性质:
- 每个节点非红即黑
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如图所示,如果一个节点是红的,那么它的两儿子都是黑的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
- 每条路径都包含相同的黑节点;
总结:
红黑树的查询性能略微逊色于 AVL树 ,因为他比 AVL树 会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的 AVL树 最多多一次比较,但是,红黑树在插入和删除上完爆 AVL树 , AVL树 每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于 AVL树 为了维持平衡的开销要小得多。
Q: 手写 LRU
// 方法一
class LRUCache {
private MapCache cache;;
public LRUCache(int capacity) {
cache = new MapCache(capacity);
}
public int get(int key) {
return cache.getOrDefault(key,-1);
}
public void put(int key, int value) {
cache.put(key,value);
}
}
class MapCache extends LinkedHashMap<Integer, Integer> {
private int MAX;
//调用父类构造函数,令 accessOrder = true
MapCache(int max){
super(max,0.75f,true);
this.MAX = max;
}
protected boolean removeEldestEntry(Map.Entry<Integer,Integer> eldest){
return size() > MAX;
}
}
// 方法二
class LRUCache {
LinkedHashMap<Integer,Integer> map = new LinkedHashMap<Integer,Integer>();
private Integer capacity;
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
if(!map.keySet().contains(key)) return -1;
int value = map.get(key);
map.remove(key);
map.put(key,value);
return value;
}
public void put(int key, int value) {
if(map.keySet().contains(key)) {
map.remove(key);
map.put(key,value);
return;
}
if(map.size() == capacity) {
int old = map.entrySet().iterator().next().getKey();
map.remove(old);
}
map.put(key,value);
}
}
Q: 手写 KMP 算法
public class KMP {
// 生成 next 数组
public int[] genNextArray(String T) {
char[] t = T.toCharArray();
int[] next = new int[t.length];
int i = 0; /* T[i] 表示后缀的单个字符 */
int j = -1; /* T[j] 表示前缀的单个字符 */
next[0] = 0;
while (i < t.length - 1) {
if (j == -1 || t[i] == t[j]) {
i++;
j++;
next[i] = j + 1;
} else {
j = next[j] - 1;
}
}
for (int k = 0; k < next.length; k++) {
next[k] -= 1;
}
return next;
}
// kmp 匹配
public int kmpStringMatch(String S, String T) {
char[] s = S.toCharArray();
char[] t = T.toCharArray();
int n = s.length;
int m = t.length;
int i = 0;
int j = 0;
int[] next = genNextArray(T);
while (i < n && j < m) {
if (j == -1 || s[i] == t[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j == m) return i - m;
return -1;
}
public static void main(String[] args) {
KMP kmp = new KMP();
System.out.println(kmp.kmpStringMatch("abcgloogle","gle"));
}
}
Q: select poll epoll
视频讲解: https://www.bilibili.com/video/av10403903?from=search&seid=1363457268108346945
文章:
https://www.cnblogs.com/jeakeven/p/5435916.html
epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现。
1、select
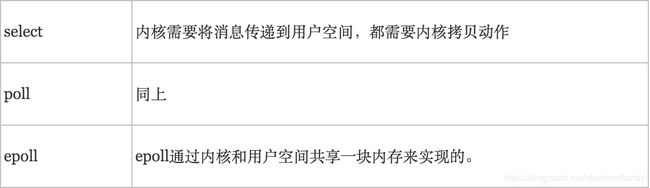
基本原理:select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
-
select最大的缺陷就是单个进程所打开的FD是有一定限制的,它由FD_SETSIZE设置,默认值是1024。
-
对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。
-
需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
2、poll
基本原理:poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1)大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2)poll还有一个特点是 水平触发,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
3、epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
基本原理:epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)。
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。
只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
消息传递方式
Q: 算法:字典序的第K小数字
class Solution {
public int findKthNumber(int n, int k) {
// 看作一个十叉树问题
int curr = 1;
k = k - 1;
while (k > 0) {
long steps = 0, first = curr, last = curr + 1;
// 计算相邻节点之前先序遍历之间相隔的个数
while (first <= n) {
steps += Math.min((long)n + 1, last) - first;
first *= 10;
last *= 10;
}
if (steps > k) { // 如果 间隔steps 大于 k 说明在其子树下
curr *= 10;
k -= 1;
} else { // 如果 间隔steps 不大于 k 说明在其相邻节点子树下
curr += 1;
k -= steps;
}
}
return curr;
}
}
Q: 算法:字典序排数
class Solution {
List<Integer> result = new ArrayList<Integer>();
public List<Integer> lexicalOrder(int n) {
for (int i = 1; i <= 9; i++) {
lexicalOrder(i, n);
}
return result;
}
public void lexicalOrder(int n, int threshold) {
if(n > threshold) return;
result.add(n);
for (int i = 0; i <= 9; i++) {
lexicalOrder(10 * n + i, threshold);
}
}
}