【论文笔记】Octave CNN(OctConv)更好更快地卷积神经网络,持续更新
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
降八度:使用八倍卷积降低卷积神经网络的空间冗余
论文地址:https://arxiv.org/pdf/1904.05049.pdf
论文由Facebook,新加坡国立大学,奇虎360合作
在天然的图像里,信息往往被表现成不同的频率,其中高频信息常被编码成精琢细节,低频嘻嘻常被编码成结构概况。相似地,一个卷积层的输出特征图谱也可以被看作是不同频率信息的整合。(卷积经常是把两个信号像绳索一样拧成一股)
本论文旨在根据频率来分解特征图谱,并且设计一个新型的八倍卷积神经网络OctConv操作来存储和处理低分辨率的特征图谱,降低了内存和计算成本。
不同于已有的大规模解决方案,OctConv被编写成单一、泛型、即插即玩的卷积单元,并且可被直接用来替代原本的卷积单元而不用调整任何网络结构。并且她可以与其他方法一起使用(交错或者补充的)以得到更好的效果或者降低卷积层之间通道的冗余。
该论文的方法已被实验证明可以仅在代替其他卷积单元的情况下稳定提高图片和视频识别任务的预测准确率,同时降低了内存和计算成本。 ResNet-152(OctConv)+ImageNet = 82.9% accuracy + 22.2 GFLOPs
 (from paper)天然图像含有不同频率的空间表达
(from paper)天然图像含有不同频率的空间表达
从图中可以看出,一个天然图像(左)可以被表示成较低空间的频率部分(中)来表示平滑变化的结构 + 较高空间频率的部分(右)来表示迅速变化的精美细节。相似地,一个卷积层的输出特征图谱也能被分成不同空间频率的特征从而使用新颖的多频特征表达(multi-frequency feature representation)来分组存储高频和低频的特征图谱。因此,低频组可以安全地通过和邻近的像素分享信息从而降低空间冗余度,如下图(中)所示。下图(右)表示OctConv将两种频率的张量放进同一个特征图谱,不把低频组解码成高频组,而直接将信息从低频特征图谱抽取出来。
博主认为论文实际上就是在网络内部把图像做了虚化和锐化处理啊dammn,然后……
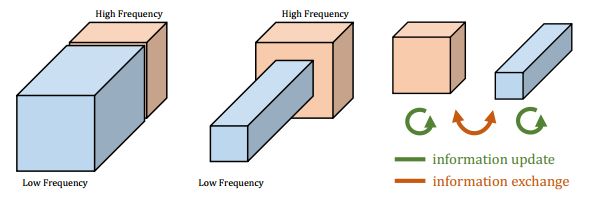 (from paper)多频卷积层特征表达
(from paper)多频卷积层特征表达
OctConv是泛型的模型,可即插即用来代替原卷积结构。可以用在group, depth-wise和3D卷积情况。
拓展:什么是group, depth-wise和3D 卷积?
Group Convolution 和 Depth-wise Convolution
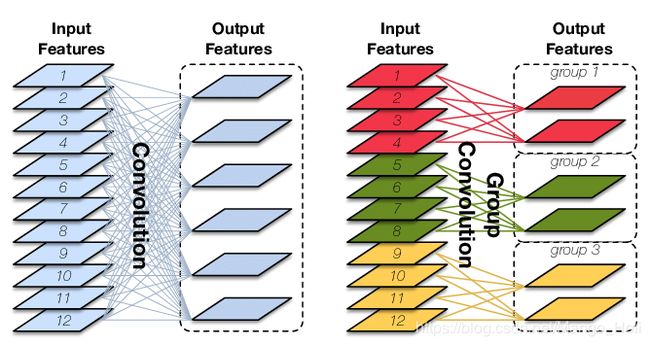 对比普通卷积(左)与Group卷积(右)
对比普通卷积(左)与Group卷积(右)
概念:
Group Convolution对输入feature map进行分组,然后每组分别卷积。总参数量减少为原来的1/Group。如上图右,N=12,G=3
Depth-wise Convolution是在Group Convolution概念的基础上当分组等于实际输入的feature map数量等于实际输出的feature map数量。即在卷积前后的feature map不变,卷积对其进行二维的映射。参数量进一步缩减。
用途:被用来切分网络,使其在2个GPU上并行运行。
3D Convolution
常见的2D Convolution是对单张图片进行处理,3D Convolution试图从序列角度直接对图像序列做时间维度的卷积来处理视频文件。除了使用3D Convolution对视频序列进行处理,还可以使用CNN+RNN的形式在卷积之后对卷积完输出的feature map进行处理。一些文献在实验过程中发现3D Convolution比CNN+RNN的形式在处理序列的时候效果更好,原因和具体参考资料可自行查找,博主这里不一一列举了。
参考文献:
1. Group Convolution分组卷积,以及Depthwise Convolution和Global Depthwise Convolution