【命名实体识别(NER)】(1):命名实体识别综述
什么是命名实体识别?
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是自然语言处理中的一项基础任务,应用范围非常广泛。命名实体一般指的是文本中具有特定意义或者指代性强的实体,通常包括 人名、地名、机构名、日期时间、专有名词等。通常包括两部分:
- 实体的边界识别
- 确定实体的类型(人名、地名、机构名或其他)
NER系统就是从非结构化的输入文本中抽取出上述实体,并且可以按照业务需求识别出更多类别的实体,比如产品名称、型号、价格等。因此实体这个概念可以很广,只要是业务需要的特殊文本片段都可以称为实体。
学术上NER所涉及的命名实体一般包括3大类(实体类,时间类,数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)。
实际应用中,NER模型通常只要识别出人名、地名、组织机构名、日期时间即可,一些系统还会给出专有名词结果(比如缩写、会议名、产品名等)。货币、百分比等数字类实体可通过正则搞定。另外,在一些应用场景下会给出特定领域内的实体,如书名、歌曲名、期刊名等。
命名实体识别的价值和应用领域
命名实体识别是NLP中一项基本性的关键任务,是关系抽取、事件抽取、知识图谱、信息提取、问答系统、句法分析、机器翻译等诸多NLP任务的基础,被广泛应用在自然语言处理领域,同时在自然语言处理技术走向实用化的过程中占有重要地位。
- 事件检测: 地点、时间、人物是事件的基本构成部分,在构建事件的摘要时,可以突出相关人物、地点、单位等。在事件搜索系统中,相关的人物、时间、地点可以作为索引关键词。通过事件的几个构成部分之间的关系,可以从语义层面更详细地描述事件。
- 信息检索: 命名实体可以用来提高和改进检索系统的效果,当用户输入“重大”时,可以发现用户更想检索的是“重庆大学”,而不是其对应的形容词含义。此外,在建立倒排索引的时候,如果把命名实体切成多个单词,将会导致查询效率降低。此外,搜索引擎正在向语义理解、计算答案的方向发展。
- 语义网络: 语义网络中一般包括概念、实例及其对应的关系,例如“国家”是一个概念,中国是一个实例,“中国”是一个“国家”表达实体与概念之间的关系。语义网络中的实例有很大一部分是命名实体。
- 机器翻译: 命名实体的翻译(尤其像人名、专有名词、机构名等),常常会有某些特殊的翻译规则(例如中国的人名翻译成英文时要使用名字的拼音来表示,有名在前姓在后的规则),而普通的词语要翻译成对应的英文单词。准确识别出文本中的命名实体,对提高机器翻译的效果有直接的意义。
- 问答系统: 准确识别出问题的各个组成部分,问题的相关领域、相关概念是问答系统的重点和难点。目前,大部分问答系统都只能搜索答案,而不能计算答案。搜索答案进行的是关键词的匹配,用户根据搜索结果人工提取答案,而更加友好的方式是把答案计算好呈现给用户。问答系统中有一部分问题需要考虑到实体之间的关系,例如“美国第四十五届总统”,目前的搜索引擎会以特殊的格式返回答案“特朗普”。
命名实体识别的研究现状和难点
命名实体识别当前并不是一个大热的研究课题,因为学术界部分学者认为这是一个已经解决了的问题,但是也有学者认为这个问题还没有得到很好地解决,原因主要有:
- 命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名)中取得了效果
- 与其他信息检索领域相比,实体命名评测语料较小,容易产生过拟合
- 命名实体识别更侧重高召回率,但在信息检索领域,高准确率更重要
- 通用的识别多种类型的命名实体的系统性很差。
同时,中文的命名实体识别与英文的命名实体识别相比,挑战更大,目前未解决的难题更多。英语中的命名实体具有比较明显的形式标志,即实体中的每个词的第一个字母要大写,所以对实体边界的识别相对容易,任务的重点是确定实体的类别。和英语相比,汉语命名实体识别任务更加复杂,而且相对于实体类别标注任务而言,实体边界的识别更加困难。汉语命名实体识别的难点主要存在于:
- 汉语文本没有类似英文文本中空格之类的显式标示词的边界标示符,命名实体识别的第一步就是确定词的边界,即中文分词
- 汉语分词和命名实体识别互相影响
- 除了英语中定义的实体,
外国人名译名和地名译名是存在于汉语中的两类特殊实体类型 - 现代汉语文本,尤其是网络文本,常出现中英文交替使用,此时汉语命名实体识别的任务还包括识别其中的英文命名实体
- 不同的命名实体具有不同的内部特征,不可能用一个统一的模型来刻画所有的实体内部特征
- 现代汉语日新月异的发展给命名实体识别也带来了新的困难:(1)标注语料老旧,覆盖不全。譬如说,近年来起名字的习惯用字与以往相比有很大的变化,以及各种复姓识别、国外译名、网络红人、流行用语、虚拟人物和昵称的涌现。(2)命名实体歧义严重,消歧困难
命名实体识别解决方案
命名实体识别(NER)一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,命名实体识别(NER)研究进展的大概趋势大致如下图所示:

基于规则和字典的方法
基于规则的方法多采用语言学专家手工构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词(如尾字)、中心词等方法,以模式和字符串相匹配为主要手段,这类系统大多依赖于知识库和词典的建立。基于规则和词典的方法是命名实体识别中最早使用的方法,它们依赖于手工规则的系统,都使用命名实体库,而且对每一个规则都赋予权值。当遇到规则冲突的时候,选择权值最高的规则来判别命名实体的类型。一般而言,当提取的规则能比较精确地反映语言现象时,基于规则的方法性能要优于基于统计的方法。但基于规则和字典的方法也有其缺陷:
- 规则往往依赖于具体语言、领域和文本风格,制定规则的过程耗时且难以涵盖所有的语言,特别容易产生错误,系统可移植性差,对于不同的系统需要语言学专家重新书写规则
- 代价太大,存在系统建设周期长、需要建立不同领域知识库作为辅助以提高系统识别能力等问题
基于统计机器学习的方法
基于统计机器学习的方法主要包括:隐马尔可夫模型(Hidden Markov Moder, HMM)、最大熵模型(Maximum Entropy Model, MEM)、支持向量机(Support Vector Machine, SVM)、条件随机场(Conditional Random Field, CRF)等等。在基于机器学习的方法中,NER被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。NER 任务中的常用模型包括生成式模型HMM、判别式模型CRF等。条件随机场(Conditional Random Field,CRF)是NER目前的主流模型。
条件随机场(CRF) 的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用维特比算法进行解码。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。

在传统机器学习方法中,常用的特征如下:

四种学习方法的优缺点分析
- 最大熵模型结构紧凑,具有较好的通用性,主要缺点是训练时间复杂性非常高,有时甚至导致训练代价难以承受,而且最大熵模型需要归一化计算,导致开销比较大
- 条件随机场为命名实体识别提供了一个特征灵活、全局最优的标注框架,但同时存在收敛速度慢、训练时间长的问题
- 一般说来,最大熵和支持向量机在正确率上要比隐马尔可夫模型高一些,但是隐马尔可夫模型在训练和识别时的速度要快一些,主要是由于在利用Viterbi算法求解命名实体类别序列的效率较高
- 隐马尔可夫模型更适用于一些对实时性有要求以及像信息检索这样需要处理大量文本的应用,如短文本命名实体识别
基于统计的方法对特征选取的要求较高,需要从文本中选择对该项任务有影响的各种特征,并将这些特征加入到特征向量中。依据特定命名实体识别所面临的主要困难和所表现出的特性,考虑选择能有效反映该类实体特性的特征集合。主要做法是通过对训练语料所包含的语言信息进行统计和分析,从训练语料中挖掘出特征。有关特征可以分为具体的单词特征、上下文特征、词典及词性特征、停用词特征、核心词特征以及语义特征等。基于统计的方法对语料库的依赖也比较大,而可以用来构建和评估命名实体识别系统的大规模通用语料库又比较少,这是此种方法的又一大制约。
基于深度学习的方法
NN/CNN-CRF模型
《Natural language processing (almost) from scratch》 是较早使用神经网络进行NER的代表工作之一。在这篇论文中,作者提出了窗口方法与句子方法两种网络结构来进行NER。这两种结构的主要区别就在于窗口方法仅使用当前预测词的上下文窗口进行输入,然后使用传统的NN结构;而句子方法是以整个句子作为当前预测词的输入,加入了句子中相对位置特征来区分句子中的每个词,然后使用了一层卷积神经网络CNN结构。

在训练阶段,作者也给出了两种目标函数:
- 词级别的对数似然,即使用softmax来预测标签概率,当成是一个传统分类问题
- 句子级别的对数似然,其实就是考虑到CRF模型在序列标注问题中的优势,将标签转移得分加入到目标函数中。后来许多相关工作把这个思想称为结合了一层CRF层,所以我这里称为NN/CNN-CRF模型。

在作者的实验中,上述提到的NN和CNN结构效果基本一致,但是句子级别似然函数即加入CRF层在NER的效果上有明显提高。
RNN-CRF模型
借鉴上面的CRF思路,出现了一系列使用RNN结构并结合CRF层进行NER的工作。模型结构如下图:
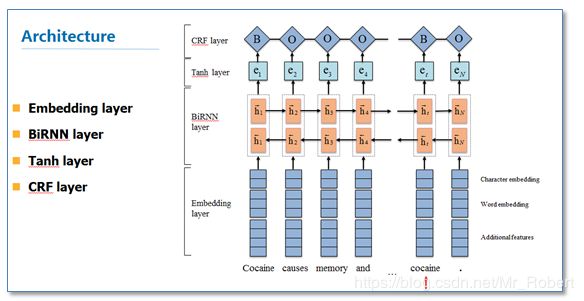
它主要有Embedding层(主要有词向量,字符向量以及一些额外特征),双向RNN层,tanh隐层以及最后的CRF层构成。它与之前NN/CNN-CRF的主要区别就是他使用的是双向RNN代替了NN/CNN。这里RNN常用LSTM或者GRU。实验结果表明RNN-CRF获得了更好的效果,已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
近期工作
Attention-based
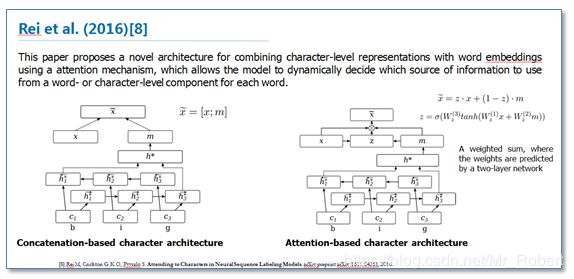
《Attending to Characters in Neural Sequence Labeling Models》 该论文还是在RNN-CRF模型结构基础上,重点改进了词向量与字符向量的拼接。使用attention机制将原始的字符向量和词向量拼接改进为了权重求和,使用两层传统神经网络隐层来学习attention的权值,这样就使得模型可以动态地利用词向量和字符向量信息。实验结果表明比原始的拼接方法效果更好。
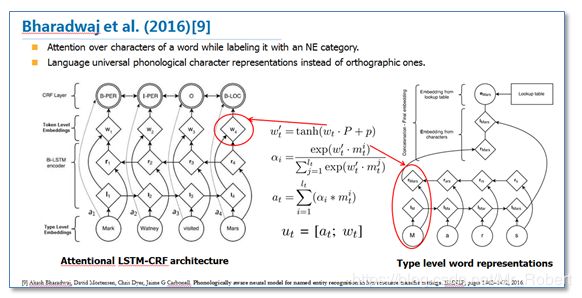
另一篇论文《Phonologically aware neural model for named entity recognition in low resource transfer settings》,在原始BiLSTM-CRF模型上,加入了音韵特征,并在字符向量上使用attention机制来学习关注更有效的字符,主要改进如下图:
少量标注数据
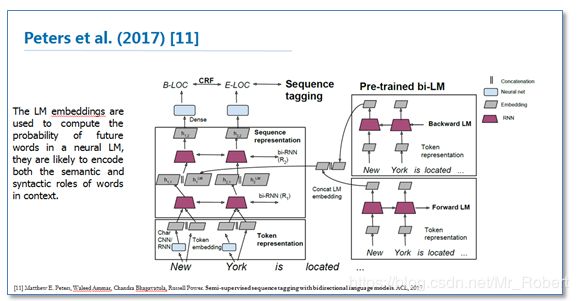
对于深度学习方法,一般需要大量标注数据,但是在一些领域并没有海量的标注数据。所以在基于神经网络结构方法中如何使用少量标注数据进行NER也是最近研究的重点。其中包括了迁移学习《Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks》和半监督学习。这里我提一下最近ACL2017刚录用的一篇论文《Semi-supervised sequence tagging with bidirectional language models》。该论文使用海量无标注语料库训练了一个双向神经网络语言模型,然后使用这个训练好的语言模型来获取当前要标注词的语言模型向量(LM embedding),然后将该向量作为特征加入到原始的双向RNN-CRF模型中。实验结果表明,在少量标注数据上,加入这个语言模型向量能够大幅度提高NER效果,即使在大量的标注训练数据上,加入这个语言模型向量仍能提供原始RNN-CRF模型的效果。整体模型结构如下图:
总结
对于统计机器学习方法而言,将 NER 视作序列标注任务,利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。常用的应用到 NER 任务中的模型包括生成式模型HMM、判别式模型CRF等。比较流行的方法是特征模板 + CRF的方案。
随着硬件能力的发展以及词的分布式表示(word embedding)的出现,神经网络成为可以有效处理许多NLP任务的模型。通过将神经网络与CRF模型相结合的NN/CNN/RNN-CRF模型成为了目前NER的神经网络领域的主流模型。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字符向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。
近年来,命名实体识别在多媒体索引、半监督和无监督的学习、复杂语言环境和机器翻译等方面取得大量新的研究成果。随着半监督的学习和无监督的学习方法不断被引入到这个领域,采用未标注语料集等方法将逐步解决语料库不足的问题,将会成为未来NER研究领域的热点和重点。
在后续博客中,我会陆续更新利用HMM、CRF、神经网络+CRF的解决方案解决中文领域命名实体识别任务。请随时关注。
参考资料
-
《统计自然语言处理》
-
神经网络结构在命名实体识别(NER)中的应用
-
一文详解深度学习在命名实体识别(NER)中的应用
-
DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别