LSTM模型 轨迹经纬度预测
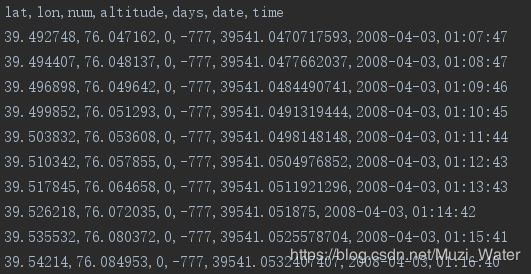
原始时间序列数据如下所示,我们只取前两列纬度和经度作为输入数据
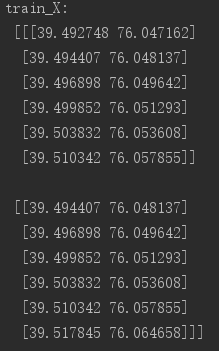
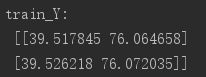
我们设定用前六个位置信息预测下一个位置,则两个样本的输入输出数据如下所示:
 |
 |
创建LSTM网络训练模型:
import numpy as np
from keras.layers.core import Dense, Activation, Dropout
from keras.layers import LSTM
from keras.models import Sequential, load_model
from keras.callbacks import Callback
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import pandas as pd
import os
import keras.callbacks
import matplotlib.pyplot as plt
#设定为自增长
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
KTF.set_session(session)
def create_dataset(data,n_predictions,n_next):
'''
对数据进行处理
'''
dim = data.shape[1]
train_X, train_Y = [], []
for i in range(data.shape[0]-n_predictions-n_next-1):
a = data[i:(i+n_predictions), :]
train_X.append(a)
tempb = data[(i+n_predictions):(i+n_predictions+n_next), :]
b = []
for j in range(len(tempb)):
for k in range(dim):
b.append(tempb[j, k])
train_Y.append(b)
train_X = np.array(train_X, dtype='float64')
train_Y = np.array(train_Y, dtype='float64')
test_X, test_Y = [], []
i = data.shape[0]-n_predictions-n_next-1
a = data[i:(i + n_predictions), :]
test_X.append(a)
tempb = data[(i + n_predictions):(i + n_predictions + n_next), :]
b = []
for j in range(len(tempb)):
for k in range(dim):
b.append(tempb[j, k])
test_Y.append(b)
test_X = np.array(test_X, dtype='float64')
test_Y = np.array(test_Y, dtype='float64')
return train_X, train_Y, test_X, test_Y
def NormalizeMult(data, set_range):
'''
返回归一化后的数据和最大最小值
'''
normalize = np.arange(2*data.shape[1], dtype='float64')
normalize = normalize.reshape(data.shape[1], 2)
for i in range(0, data.shape[1]):
if set_range == True:
list = data[:, i]
listlow, listhigh = np.percentile(list, [0, 100])
else:
if i == 0:
listlow = -90
listhigh = 90
else:
listlow = -180
listhigh = 180
normalize[i, 0] = listlow
normalize[i, 1] = listhigh
delta = listhigh - listlow
if delta != 0:
for j in range(0, data.shape[0]):
data[j, i] = (data[j, i] - listlow)/delta
return data, normalize
def trainModel(train_X, train_Y):
'''
trainX,trainY: 训练LSTM模型所需要的数据
'''
model = Sequential()
model.add(LSTM(
120,
input_shape=(train_X.shape[1], train_X.shape[2]),
return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(
120,
return_sequences=False))
model.add(Dropout(0.3))
model.add(Dense(
train_Y.shape[1]))
model.add(Activation("relu"))
model.compile(loss='mse', optimizer='adam', metrics=['acc'])
model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=1)
model.summary()
return model
if __name__ == "__main__":
train_num = 6
per_num = 1
# set_range = False
set_range = True
# 读入时间序列的文件数据
data = pd.read_csv('20080403010747.txt', sep=',').iloc[:, 0:2].values
print("样本数:{0},维度:{1}".format(data.shape[0], data.shape[1]))
# print(data)
# 画样本数据库
plt.scatter(data[:, 1], data[:, 0], c='b', marker='o', label='traj_A')
plt.legend(loc='upper left')
plt.grid()
plt.show()
#归一化
data, normalize = NormalizeMult(data, set_range)
# print(normalize)
#生成训练数据
train_X, train_Y, test_X, test_Y = create_dataset(data, train_num, per_num)
print("x\n", train_X.shape)
print("y\n", train_Y.shape)
# 训练模型
model = trainModel(train_X, train_Y)
loss, acc = model.evaluate(train_X, train_Y, verbose=2)
print('Loss : {}, Accuracy: {}'.format(loss, acc * 100))
# 保存模型
np.save("./traj_model_trueNorm.npy", normalize)
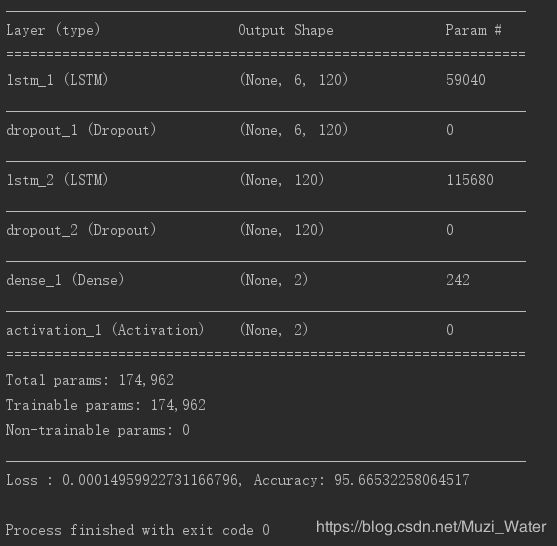
model.save("./traj_model_120.h5")模型训练结果如下:
创建LSTM网络预测模型:
import numpy as np
from keras.layers.core import Dense, Activation, Dropout
from keras.layers import LSTM
from keras.models import Sequential, load_model
from keras.callbacks import Callback
import keras.backend.tensorflow_backend as KTF
import tensorflow as tf
import pandas as pd
import os
import keras.callbacks
import matplotlib.pyplot as plt
import copy
#设定为自增长
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
KTF.set_session(session)
def rmse(predictions, targets):
return np.sqrt(((predictions - targets) ** 2).mean())
def mse(predictions, targets):
return ((predictions - targets) ** 2).mean()
def reshape_y_hat(y_hat,dim):
re_y = []
i = 0
while i < len(y_hat):
tmp = []
for j in range(dim):
tmp.append(y_hat[i+j])
i = i + dim
re_y.append(tmp)
re_y = np.array(re_y, dtype='float64')
return re_y
#多维反归一化
def FNormalizeMult(data,normalize):
data = np.array(data, dtype='float64')
#列
for i in range(0, data.shape[1]):
listlow = normalize[i, 0]
listhigh = normalize[i, 1]
delta = listhigh - listlow
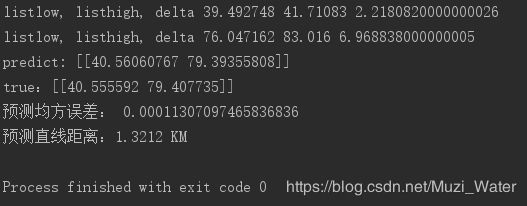
print("listlow, listhigh, delta", listlow, listhigh, delta)
#行
if delta != 0:
for j in range(0, data.shape[0]):
data[j, i] = data[j, i]*delta + listlow
return data
#使用训练数据的归一化
def NormalizeMultUseData(data,normalize):
for i in range(0, data.shape[1]):
listlow = normalize[i, 0]
listhigh = normalize[i, 1]
delta = listhigh - listlow
if delta != 0:
for j in range(0, data.shape[0]):
data[j, i] = (data[j, i] - listlow)/delta
return data
from math import sin, asin, cos, radians, fabs, sqrt
EARTH_RADIUS = 6371 # 地球平均半径,6371km
# 计算两个经纬度之间的直线距离
def hav(theta):
s = sin(theta / 2)
return s * s
def get_distance_hav(lat0, lng0, lat1, lng1):
# "用haversine公式计算球面两点间的距离。"
# 经纬度转换成弧度
lat0 = radians(lat0)
lat1 = radians(lat1)
lng0 = radians(lng0)
lng1 = radians(lng1)
dlng = fabs(lng0 - lng1)
dlat = fabs(lat0 - lat1)
h = hav(dlat) + cos(lat0) * cos(lat1) * hav(dlng)
distance = 2 * EARTH_RADIUS * asin(sqrt(h))
return distance
if __name__ == '__main__':
test_num = 6
per_num = 1
data_all = pd.read_csv('20080403010747.txt', sep=',').iloc[-2*(test_num+per_num):-1*(test_num+per_num), 0:2].values
data_all.dtype = 'float64'
data = copy.deepcopy(data_all[:-per_num, :])
y = data_all[-per_num:, :]
# #归一化
normalize = np.load("./traj_model_trueNorm.npy")
data = NormalizeMultUseData(data, normalize)
model = load_model("./traj_model_120.h5")
test_X = data.reshape(1, data.shape[0], data.shape[1])
y_hat = model.predict(test_X)
y_hat = y_hat.reshape(y_hat.shape[1])
y_hat = reshape_y_hat(y_hat, 2)
#反归一化
y_hat = FNormalizeMult(y_hat, normalize)
print("predict: {0}\ntrue:{1}".format(y_hat, y))
print('预测均方误差:', mse(y_hat, y))
print('预测直线距离:{:.4f} KM'.format(get_distance_hav(y_hat[0, 0], y_hat[0, 1], y[0, 0], y[0, 1])))
# 画测试样本数据库
p1 = plt.scatter(data_all[:-per_num, 1], data_all[:-per_num, 0], c='b', marker='o', label='traj_A')
p2 = plt.scatter(y_hat[:, 1], y_hat[:, 0], c='r', marker='o', label='pre')
p3 = plt.scatter(y[:, 1], y[:, 0], c='g', marker='o', label='pre_true')
plt.legend(loc='upper left')
plt.grid()
plt.show()预测结果如下: