Python正则表达式提取网页数据(代码实例)
# coding=utf-8
import re
import urllib.request #urllib在python3不支持,改变格式
import requests
from bs4 import BeautifulSoup
import mysql.connector
url = 'http://www.cnnvd.org.cn/web/vulnerability/querylist.tag '
headers = {'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0'}
#添加了一个头部,伪装成浏览器,此时的url并不是一个裸露的url,而是具有header头部的url
#urllib.request.Request()用于向服务端发送请求,就如 http 协议客户端向服务端发送请求 POST
request = urllib.request.Request(url=url, headers=headers)
#urllib.request.urlopen()则相当于服务器返回的响应,返回的是一个request类的一个对象, GET
# 类似于一个文件对象,可以进行open()操作获取内容
response = urllib.request.urlopen(request, timeout = 10)#延时
content = response.read().decode('utf-8')#转换一下编码才行
print('获取链接文本内容:')
#print(content)
pattern = r'(.*?)' #规则
datalist = re.findall(pattern, content,re.S|re.M)#标志修饰符,findall得到一个列表
datastr = "".join(datalist)#list转换为str
ret = re.sub('<.*?>',"",datastr)#去除HTML标签
oh = ret.replace("/n","")#将换行符用空替代
print(oh)
'''
for value in oh:
print(value)
————————————————————————————————————————最初的
import requests
import re #导入相关的库
url="https://blog.csdn.net/quest_sec"
data = requests.get(url) #请求网页
print(data.text)
pattern = re.compile(r'(.*?)') # pattern:匹配的正则表达式:+*贪婪?最小
title = pattern.findall(data.text)#变量是HTML整个网页 / findall找到所匹配的所有子串,可以指定起始结束位置
print(title)
'''
——————————————————————————————————
爬取网页中所有URL链接:
原文链接:https://blog.csdn.net/eastmount/article/details/51082253
import re
import urllib.request #urllib在python3不支持
url = "http://www.csdn.net/"
content = urllib.request.urlopen(url).read()
urls = re.findall(r"" ,content.decode('utf-8'))# 把content的类型调整一下 + .decode('utf-8')
for url in urls:
print (url,'utf-8')
输出结果:
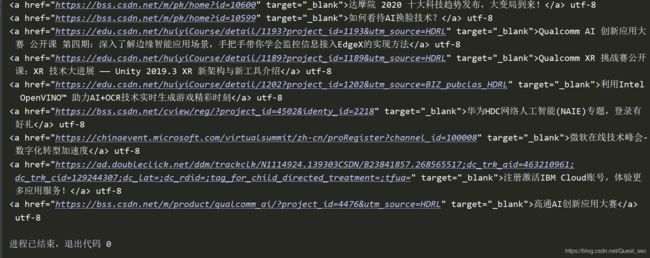
# coding=utf-8
import re
import urllib.request #urllib在python3不支持,改变格式
url = "http://www.csdn.net/"
content = urllib.request.urlopen(url).read()
#把content的类型调整一下 + .decode('utf-8')
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", content.decode('utf-8'))
for url in link_list:
print (url)
输出结果:
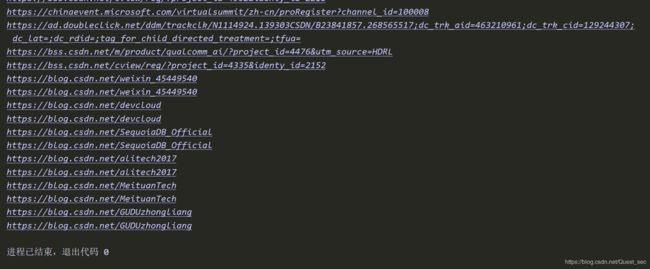
————————————————————————————————————
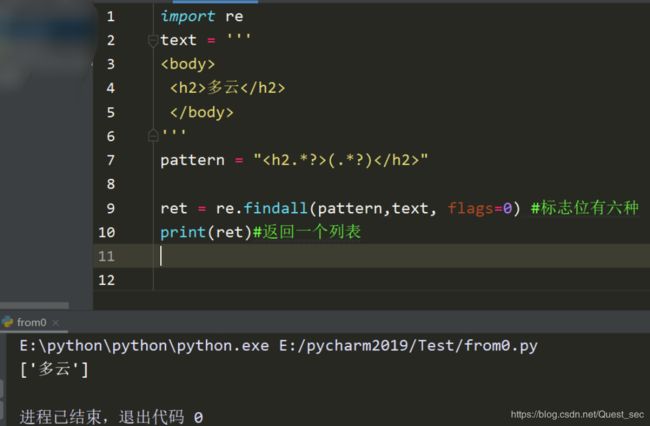
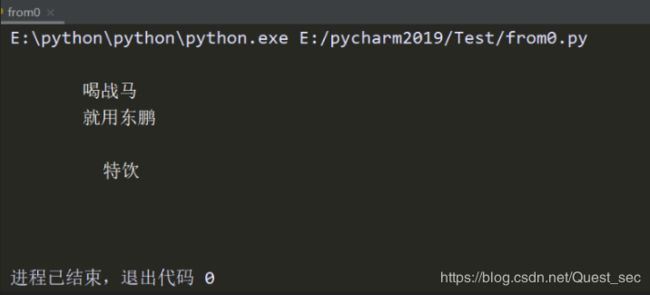
import re
text ="""
喝战马
就用东鹏
特饮
"""
ret = re.sub('<.*?>',"",text)
str = ret.replace('/n',"")
print(str)
import re
html = """
"""
results = re.findall('.*?(.*?)?()?(.*?)(.*?)?' ,html,re.S)
#print(results)
for result in results:
print(result[2])
以上这一小段代码源自 https://blog.csdn.net/weixin_42540398/article/details/90481076
'''
UA//亲测可行
'''
import urllib.request
url = 'https://blog.csdn.net/quest_sec'
headers = {'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0'}
#添加了一个头部,伪装成浏览器,此时的url并不是一个裸露的url,而是具有header头部的url
#urllib.request.Request()用于向服务端发送请求,就如 http 协议客户端向服务端发送请求 POST
request = urllib.request.Request(url=url, headers=headers)
#urllib.request.urlopen()则相当于服务器返回的响应,返回的是一个request类的一个对象, GET
# 类似于一个文件对象,可以进行open()操作获取内容
response = urllib.request.urlopen(request, timeout = 10)#延时
html = response.read().decode('utf-8')
print(html)
'''
IP代理:报错,需修改
'''
import urllib.request
import random
url = 'http://www.nsfocus.net/vulndb/46220'
#定义代理ip,多个代理ip,随机使用
iplist = ['219.223.251.173:3128','203.174.112.13:3128','122.72.18.34:80']
#设置代理
proxy=urllib.request.ProxyHandle({'http':iplist[random.randint(0,len(iplist))]})
#创建一个opener
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandle)
#将opener安装为全局
urllib.request.install_opener(opener)
#用urlopen打开网页
data=urllib.request.urlopen(url).read().decode('utf-8','ignore')
print(data)