毛剑:Bilibili 的 Go 服务实践(下篇)
本文是 Blibli 技术总监毛剑在GopherChina 2017大会上所做分享的下篇,包含 B 站的中间件、持续集成和交付,以及运维体系搭建。微服务的演进过程和高可用实践见上篇。
中间件
到一定的时间以后,发现我们的服务稍微稳定了,但是业务越来越大,然后业务也越来越发展,我们发现还是需要很多中间件来辅助我们跟各个对接的业务方,或者是其他的一些平台去对接.所以我们就做了一些事情——做了一个队列(这里叫databus),也做一个 canal ,然后做了一些数据刷新、同步,又基于 twitter的 twemproxy 改了一个多线程的版本,然后还做了一个对象存储,此外还做了一个配置中心,最后是基于 Google 的 dapper 做了一个 APM 的链路追踪。
接下来我来讲一下各个中间件都是什么场景使用的。
Databus
做了一个 redis 的协议,用的时候相当于我先批量存一批过去,用一个长轮询的方式,然后如果它 30 秒没有返回数据,那么下次再来重拉一次。还有就是像 Kafka 不太好做健全,我们又做了一个健全,就是把 Kafka 整个地址网段都屏蔽掉,然后我们的 Databus 再对外。此外会加一些简单的授权,避免一些核心的数据泄露。
回放数据库的 binlog,然后把 Databus 跟 Canal 打通。我们可以把稿件的核心数据或者一些技术,同步给我们的搜索、大数据,甚至一些微服务的,包括我们有一些业务,db 跟 cache 要保持强一致的话,我们都是通过 binlog 们大量使用 Databus 和 Canal 的这么一个组合。

图10
图11所示场景就是我们用 Databus 来加上刚刚那两个 rpc 来支持广播,来做我们服务的 logic cache 的清理。我们有一些业务可能有多个副本,L1、L2这种, cache 可能不太好清,而且我们后续上了 docker ,发现这个IP也是变的,server 非常多,cache 清除更加困难,所以就用这样一个 Job 加一个广播再加 da tabus 订阅的方式来清理,保证整个 cache 的一致。
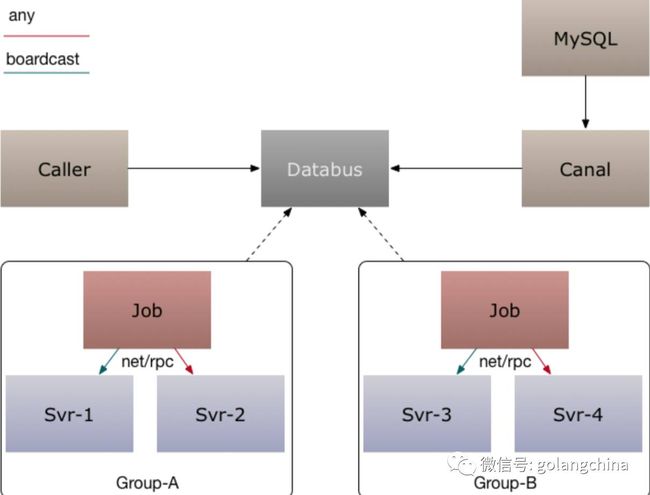
图11
配置中心
后来我们又做了配置中心,如图12。早期也是通过配置文件,后来实在太痛苦了。我们参考了很多家,360、淘宝,后来用最了简单的方法,把配置文件存到 mysql 里面,我们认为 mysql 足够可靠而且可以做主从。们用一个简单的方式来注册,就是请求一个接口带一个版本号。连一个 App ID,如果它没有配置中心就挂起,如果有配置中心就下发。这样是非常方便的,而且写起来也非常简单,因为语言比较多,用http接口是最简单的。
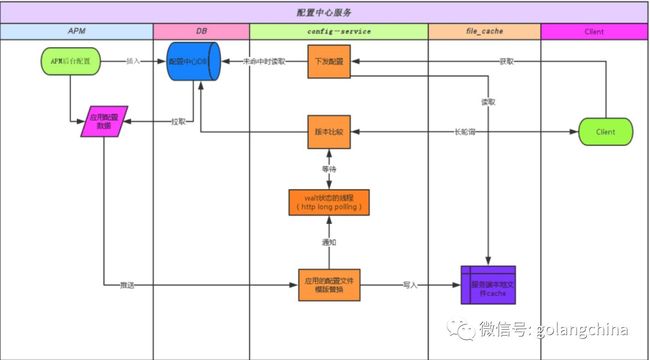
图12
后面我们到这个阶段以后发现什么问题呢?定位问题,就是查日志,每次一查问题,比如说看到这个页面炸了。每次客服也好、产品也好,找不到的时候,或者老板看到,就认为你是你炸的,其实后面一查发现是别人炸的。我们也参考谷歌的那个,做了一个链路追踪。其实非常简单,就是一个采集日志,把日志储存到上面,然后提供一个API,再做一个好看的界面就可以了。我们通过服务搜集,通过 Kafka 排队。然后一个可以储存到 HBase 里面,就是完整的链路信息,再用 ES 做一些搜索,然后提供一些 API,最终做了一个 APM 的 UI,如图13,方便查看一些问题和使用。

图13
现在是什么定位问题呢?首先我先搜这个服务是什么名字,获取 title ,然后选一个时间段,就能判断这个时间段内的请求数,和我的耗时的图。比如我大部分耗时在100毫秒以上,那就有问题,我需要去定位。下面是一个ID列表,可以来查这个问题。
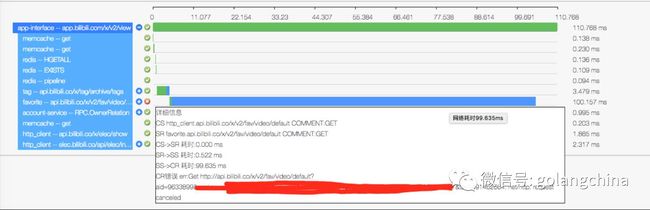
图14
图14中是我点击一个ID以后,这时候我就能看到,这个最长的条就是某一个接口,这个是收藏夹的接口超时了。或者我们发现,它从经过网络传输的时候,包括我们链路设备,应该是交换机上面的一个模块,也用的那种小厂商的,不是买的华为的,因为华为的特别贵。然后发现出问题了,后来我们很老实的全部换成华为的模块了。那通过链路追踪可以找到很多上游和下游链路上的问题,甚至能找到你们通信网络上的问题。我们把所有的核心库常用的网络资源都注入代码里面的方式去打点,然后搜集。其实到这个阶段,我们要优化一个代码非常简单,我只要搜一个API,我看很慢,然后看到底哪里慢,再去推业务方优化。
还有一个好处,我可以看这个服务到底依赖的下游是谁,我的依赖经常梳理的,到最后我们发现,只要有一个依赖就可以把整个总站的所有依赖情况自动划出来,我做到这一步以后,发现通过图15,我们目前做到这个,就是把全站的依赖划出来,是不是有一些不合理的地方,其实再下面是不是把一些流量的密集程度做进去,这个线条是有粗细的,我可以找到我的服务热点,然后去做优化。
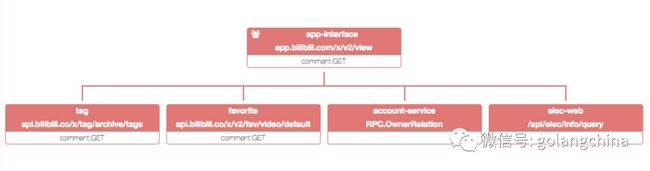
图15
通过15,我们找到几个问题,第一我发现我们核心热点是帐号服务和稿件服务。发现这个服务之前,我们这个图(图16)没有画全,其实还有很多的微服务。我们当时在想,如果你依赖超过了十个服务,每个服务有50个节点,要建500个。所以我们在微服务之间还会做一些 Gateway。相当于是一个 Gateway,这样可以减少最顶层的人依赖,不是平级的依赖,而是有一些层级以来。

图16
然后我们还发现热点怎么解决,回到刚才说的那个 Gateway,我后来发现,当我们的 Gateway 大家都依赖,然后我再扩容它的时候,其实加一个节点带来的性能提升已经非常小了。假设我再扩十个节点,但是它的成本已经非常高了。后来我们参考了 facebook 它当时提出的概念,也包括像微博,像腾讯提的部署方法,我们就会把这种核心的服务做隔离。
我举个例子,比如我们的移动端,是不是把它所有依赖服务打包,然后部署。那么再把其他的一些重要的类似的做一些拆分,这样就避免一个 gateway ,比如我一百个节点,甚至一千个节点,然后去做一个隔离。
导致每次测出来不知道是环境的问题,还是我们的功能 bug ,我每次看到这个测试,都说这个 bug 应该是环境导致的,一上线就挂了。首先我们是做了这些几件事,首先是版本管理,所有的都是语义化,都是有大的语义。都是带一些功能的增加,但是不破坏功兼容性就用这个版本,那么还有大版本。
那么通过这种方式的话,比如我是一个服务提供者,你是一个消费者,有一个概念,就是让消费者做测试,就是我是提供者,你是消费者,如果你觉得我不可靠,或者不兼容了,你去提供这个测试代码,或者我们测试的同事提供测试代码,然后把这个做到集成环境里面去。我随着这个版本越来越多,肯定要考虑兼容的,我们更多的是共存的方式,就是V1、V2共同存在,当V1流量没有人用了,再把V1下掉,最后大家都用V2。其实我们走的是共存的路线。
再讲一下代码环节,如图17。其实就是功能分支,假设我要提测,我就会发一个,非常方便。它会回复一个 +1 就会有一个点赞的手势,如果超过两三个,大家都觉得OK了就可以定了。其实这有一个好处,就是你的代码发给别人看,别人看了虽然这个业务不是你做的,但是大家都可以熟悉对方做的事情。还有一个好处就是甚至我经常在看我们团队的一些代码,有时候我甚至会想,有一些代码我不一定写的这么好,我可以学到很多东西。也是一个相互学习的过程。
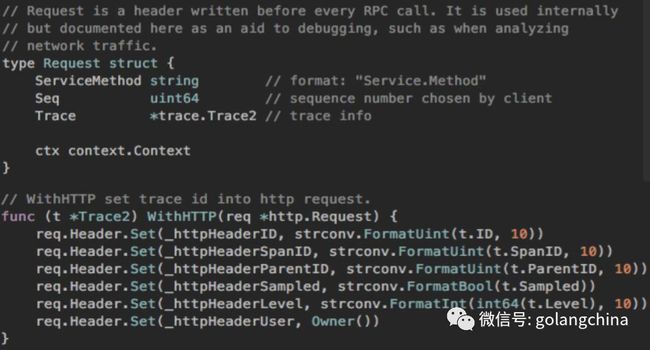
图17
持续集成和交付
最后就是
-
版本管理(语义化)
-
分支管理(gitlab+mr review)
-
环境管理(集成环境)
-
测试(单元测试+服务测试)
-
发布(冒烟、灰度、蓝绿)
使用语义化的版本管理(Major.minor.patch),如图18所示。
-
MAJOR:改变意味着其中包含不向后兼容的修改;
-
MINOR:改变意味着有新功能的增加,但应该是向后兼容的;
-
PATCH:改变代表对已有功能的 bug 修复
因此是使用对方服务时候,需要明确有微服务或者是 API 的版本管理,基于此我们知道是否是兼容的。

图18
这个构建的话,构建一个 docker,那么真正的这个环境是上面的集成测试环境,我们是通过运营,比如 FAT1 ,FAT2 ,然后测试只要把这个服务的运营可以和上面的集成环境同时连上,而不会破坏测试环境,不会破坏兼容性的代码合进去,导致整个测试环境毁掉。一旦服务环境测试稳定以后,再做一个集成环境部署。最终合并到集成环境。所以我们就做了一个平台,如图19所示。就是包括提交分发,到构建,到测试,到集成。后来还做了一些像交付。比如说线上的一些10%、20%的操作。
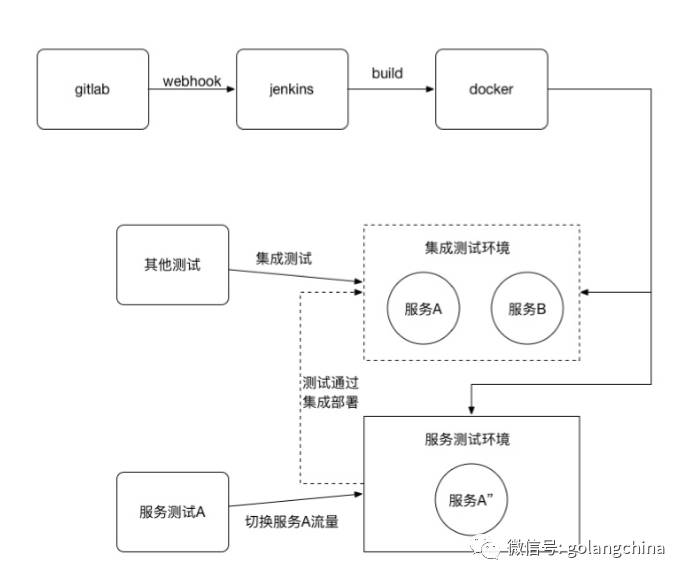
图19
运维体系
如果没有一些运维周边的支撑,微服务是没法落地的。图20-1是我们的 PaaS 平台,这个是非常方便我们扩容,只要接入到这个平台,通过这个平台以后我们可以很方便的看这个容器内监控的一些状态,包括CPU,网络等,如图20-2。然后当我们出现一些比较诡异的BAG,我们查不到,但是我这个进程夯住了怎么办?还要接一个外部的,让我可以连进去。
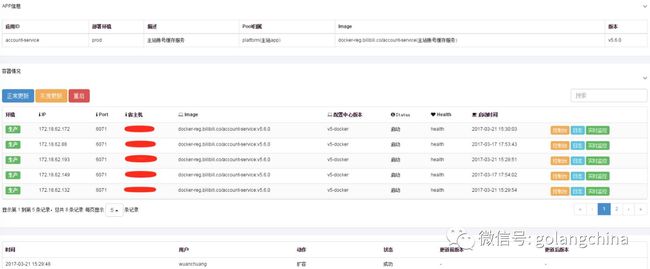
图20-1

图20-2
其实我们提出两个Agent的概念,或者我们还是想做一个类似于系统Agent,来处理所有运维的指令。第二个Agent是采集数据。我们是把它放到同一个里面,我们的业务代码就可以打给它,然后我们的分发系统,也叫一个分捡系统,它分捡就可以把日志一部分给到Nas,一部分给ES,后来是通过 kibana 查看我们的日志。如图21。

图21
到这个阶段以后有了电子监控,但是还是差一些监控系统,后来我又想了一下,整个运维监控体系应该怎么做呢?其实我在另外一个会议上分享过,我思考过运维监控怎么做。如图21。首先最底层是 Zabbix ,目前可用的Zabbix 未必是最佳选择。刚刚我们说有链路监控的,还有查看日志的,其实我们还查看一些异常。指标监控,我们开发了一个叫Traceon的一个系统,这个系统目前还在开发阶段,会采集一些重要的指标。包括我们有一次去携程看,他们可能会采集某一个地区订单量,当低于多少的时候会报警,类似一些重要指标的监控。
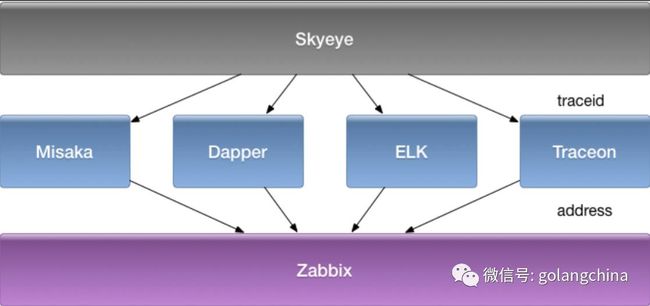
图21
还有一些异常的搜集,比如说我可能有一些超时,有熔断,我不看日志就不知道了。那么它顶层有运维的同事看到这个系统,比如最近的变更是什么,然后它触发了报警,有没有人认领这个报警,如果没有人认领,它会不断的升级报警。
其实还有一块,我们这个层面解决了很多服务端的问题,还有一个端的监控,端的监控指的是我们移动端跟外部端的监控,因为有时候网络连不上,可能有DNS污染,甚至还有流量的劫持等等,这时候通过我们客户端的买点上报来做一些端上的监控。比如说我们发现某一个区域突然大规模的连不上,那么这个上报可以通过客户端想办法报上来的,这时候我们可以做一些处理,可以把我们的CDN,是不是把流量切到别的地方去。
这是一个报警代码,我们在那个墙上放很大的电视,放这种变更等等方便他们及时的处理。其实整个微服务需要各个环节各个部门,包括运维,测试,包括开发也好,集体去构思它到底整体是怎么运作起来的。谢谢大家!
提问精选
Q:非常感谢毛老师的精彩分享,有一个问题,就是你刚才说的Databus,我想问一下,如果我要做消息的重复消费,我应该怎么处理呢?
A:其实我们做完这个东西,跟业务方扯皮了很长时间,我们是这么说的,尽可能的让他,我们都是使用至少一次消费,我们会跟业务方提一些要求。