详解 BP 神经网络基本原理及 C 语言实现
BP(back propagation)即反向传播,是一种按照误差反向传播来训练神经网络的一种方法,BP神经网络应用极为广泛。
BP 神经网络主要可以解决以下两种问题:
1.分类问题:用给定的输入向量和标签训练网络,实现网络对输入向量的合理分类。
2.函数逼近问题:用给定的输入向量和输出向量训练网络,实现对函数的逼近。
本文主要介绍 BP 神经网络的基本结构,而后简单介绍用 C 语言实现神经网络必需要用到的语法知识(老手请放心跳过),最后一步一步从构建单个神经元开始到完成整个神经网络的构建和训练。
BP 神经网络原理
人工神经元模型如下图所示:
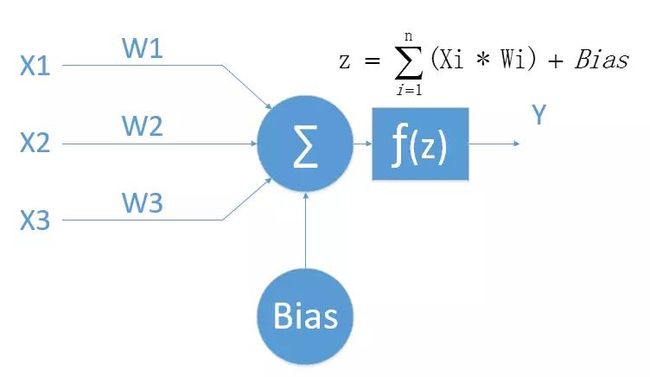
一般神经元模型包含这样几个要素:
1.输入:X1、X2、X3......Xn(可以有多个)。
2.权重:W1、W2、W3......Wn。
3.偏置:Bias。
4.激活函数:f(x)。
5.输出:y(仅一个)。
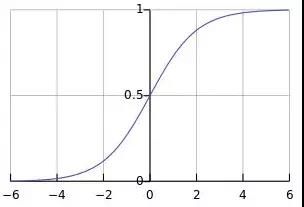
本文只用 Sigmoid 函数,下图给出了 Sigmoid 函数图像。
现在神经元模型的结构比较清楚了,下面看看如何计算模型的输出。通过给定的权重对输入进行加权求和后(默认加上偏置 Bias),再将得到的和作为参数输入一个激活函数,得到的激活函数的输出值即为神经元的输出。
对应的数学公式如下:
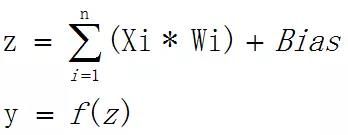
下面举个例子来说明一下计算输出的过程。
设 X1=1,X2=0,X3=0,W1=0.1,W2=0.2,W3=0.3,Bias=0.1,f(x)=x。由上面给出的计算公式可得:
z = X1W1+X2W2+X3*W3+Bias = 0.1+0+0+0.1 = 0.2
y = f(z) = z = 0.2下面简单介绍一下人工神经元模型的训练方法。为了减少不必要的演示计算步骤,这里我们用只有两个输入一个输出(只有 X1、X2)的模型进行演示,方法如下。
先给模型一个任意权值和偏置,设 W1=0,W2=0,Bias=0,再设激活函数为:
![]()
再给定两组训练用的数据,模拟一个简单的二分类问题:
第一组:data1=1,data2=1,期望输出aim_output1=1
第二组:data3=-1,data4=-1,期望输出aim_output2=0
然后我们先把第一组 data 代入模型根据前面所说的计算神经元输出的方法进行计算,得到实际输出 real_output1=f
(data1W1+data2W2+Bias)=f(0)=0。根据这个差值,可以通过如下公式来修正我们随机给定的权值和偏置:
W1=W1+etaerr1data1
W2=W2+etaerr1data2 Bias=Bias+eta*err1这里的 eta 表示学习率,一般取 0~1 之间的值。eta 值越大学习速率也越快,也就是每一次训练,权值和偏置的变动越大,但也并不是越大越好。如果 eta 过大容易产生震荡而不能稳定到目标值,若 eta 值越小,则效果相反。这里我们简单的取 eta=1,带入计算式可得经过一次修正过后的权值和偏置:
W1=1,W2=1,Bias=1注意,这里第一次训练还没结束,还要继续代入第二组的 data,并且要记住 W1、W2、Bias 已经改变,通过相同的方法计算输出:
real_output2=f(data3W1+data4W2+Bias)=f(-1-1+1)=0计算差值为:
err2=aimoutput2-realoutput2=0这样第一次训练结束,继续下一次训练。
还是先把第一组 data 代入模型进行计算得到实际输出:
real_output1=f(data1W1+data2W2+Bias)=f(11+11+1)=1计算差值:
err1=aimoutput1-realoutput1=0再把第二组 data 代入模型得输出:
real_output2=f(data3W1+data4W2+Bias)=f(-1-1+1)=0计算差值:
err2=aimoutput2-realoutput2=0至此训练完成,这个模型已经能对输入的两组数据准确分类,现在给出解决这个二分类问题的 C 语言代码。
由于我的编译器中文乱码,所以我把作者原文的中文输出改成了英文。
#include
#include
//定义训练用的数据
double data1[2]={1,1};
double data2[2]={-1,-1};
//定义数据的标准分类
double data1_class=1;
//假设data1的类型为
double data2_class=0;
//假设data2的类型为0//定义权重和偏置
double w[2]={0,0};
//这里用任意值初始化即可,训练的目的就是自动调整这个值的大小
double b=0;
//加权求和
double sumfun(double *data,double *weight,double bias)
{
return (data[0]*weight[0]+data[1]*weight[1]+bias);
}
//这里采用阶跃函数作为激活函数
double step(double sum)
{
if(sum>0)
return 1;
else
return 0;
}
int main(){
double sum=0; //存放加权求和的值
double output1=0,output2=0; //把加权求和的值代入激活函数而得到的输出值
int count=0; //训练次数的计数变量
double err=0; //计算的误差,用于对权值和偏置的修正
int flag1=0,flag2=0; //训练完成的标志,如果某组数据训练结果达标,则把标志置1,否则置0
while(1)
{
sum=sumfun(data1,w,b); //代入第一组data进行计算
output1=step(sum);
if(output1==data1_class)//判断输出是否达标,若达标则把标志置1,否则修正权值和偏置
flag1=1;
else
{
flag1=0;
err=data1_class-output1;
w[0]=w[0]+err*data1[0];
w[1]=w[1]+err*data1[1];
b=b+err;
}
sum=sumfun(data2,w,b); //代入第二组data进行计算
output2=step(sum);
if(output2==data2_class)//判断输出是否达标,若达标则把标志置1,否则修正权值和偏置
flag2=1;
else
{
flag2=0;
err=data2_class-output2;
w[0]=w[0]+err*data2[0];
w[1]=w[1]+err*data2[1];
b=b+err;
}
printf("The %d's training output:\n",count+=1); //输出训练结果
printf(" First Group's data belongs to %1.0f class.\n",output1);
printf(" First Group's data belongs to %1.0f class.\n",output2);
if(flag1==1&&flag2==1) //如果所有数据都训练达标,则直接跳出循环
{
break;
}
}
printf("\n\nThe traning done!\n\n"); return 0;
} 输出结果:
D:\test>a.exe
The 1's training output:
First Group's data belongs to 0 class.
First Group's data belongs to 0 class.
The 2's training output:
First Group's data belongs to 1 class.
First Group's data belongs to 0 class.
The traning done!原文地址:http://mp.weixin.qq.com/s/9AUioTRWSAvKDCd5hPymHQ