【论文阅读AAAI2020】TextScanner: Reading Characters in Order for Robust Scene Text Recogition
目录
1.导语
2.简介
3.方法
概述
预训练(通过字符标注)
互监督机制
4.实验
标准数据集
中文数据集
字符定位精度
5.结论
由于深度学习和海量数据的涌现,场景文字识别技术获得飞速发展。但是先前同类方法存在种种缺点,为此,本文提出 TextScanner,一种鲁棒的基于分割的场景文字识别方法,可以正确读取字符数据,并在一系列相关的文字基准数据集上,取得了当前最佳的性能。本文是旷视研究院与华中科技大学的联合研究成果,已收录于 AAAI 2020。
1.导语
过去数十年,作为计算机视觉子领域的场景文字检测与识别研究相当引人注目,这多半是因为其广泛的应用,诸如自动驾驶,视觉辅助,以及人机交互。由于场景文字承载着关键而具体的信息,精确到文字识别在复杂的现实场景中异常重要。在当前最优的场景文字识别方法中,有着两个流行的范式:1)基于 RNN 注意力的方法,2)基于语义分割的算法。
前者的灵感来自神经机器翻译,把图像编码为特征,并通过注意力机制对齐和解码字符;后者试图从 2D 的视角解决文字识别问题,它首先采用一个全连接卷积网络进行语义分割,接着在分割图中寻找相连的组件,最后为每个相连的组件分类(每个被看作一个字符)。
本质而言,要正确识别文字图像上的内容,就要精确预测字符的数量、顺序以及每个字符的类别。通常情况下,基于 RNN 注意力机制的方法工作良好。但是,当背景中有噪音,或者出现不规则的文字形状,注意力机制就会遇挫,即已评估的注意力图的中心指向一个错误的位置(注意力漂移),造成错误的字符顺序和类别,如图 1 所示。
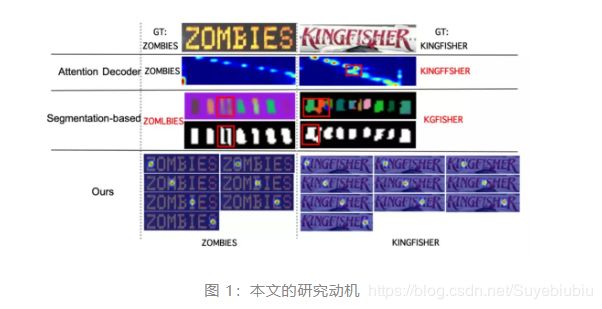
更有甚者,由于 RNN 的循环记忆机制,这样的错误会累加和传播,使情况更严重。基于语义分割的算法探索了一条不同的道路,并对不同形状的文字(水平、有向、弯曲)更具有适应性。但是,从分割图成功分离每个字符很困难,这是由于不恰当的二值化造成了一些窘境:一个字符被分离为多个部分,或者多个字符粘在一块(见图 1)。在这些情况下,字符数量和种类的预测将是错的。总之,现有方法,无论是基于 RNN 注意力还是语义分割,皆不能很好地克服场景文字识别的困难。
2.简介
基于 RNN 的方法存在着注意力飘移的问题,究其根本是由于对齐操作依赖于视觉特征和先前的解码结果。两类信息之间可能发生互扰。因此,有必要在独立的分支上执行字符对齐和分类。在基于语义分割的算法方面,可通过简单的二值化查找字符这一假设,在一些有挑战性的场景上并不成立。为此,一个自然可行的方案是通过不同的通道表示字符的位置和顺序。
本文中,旷视研究院提出一个全新的文字识别框架,称之为 TextScanner。正如一台真实的扫描器(scanner),TextScanner 可以正确的顺序读取字符。如图 2 所示,TextScanner 构建在语义分割之上,它包含两个分支:
- 1)类别分支,用于字符分类
- 2)几何分支,预测字符的位置和顺序。
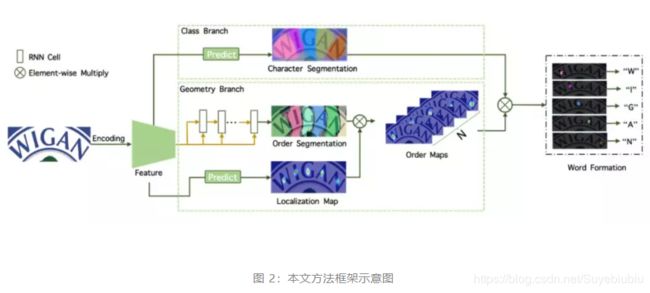
类别分支生产多通道分割图,其中每个位置的值表示字符类别(包括背景类别)的概率。几何分支也生产多通道的分割图,但是每个位置的值的意义与类别分支中的不同。由于字符对齐良好,且顺序确定,TextScanner 可以避免基于 RNN 方法中的注意力飘逸现象;同时,在几何分支中,不同的字符被严格分配至不同的通道,因此可被轻松提取。正如 FAN 和 CA-FCN,TextScanner 也需要字符级别的标注用于训练,这是因为几何分支把字符中心作为监督信号。但是,实际上有大量的真实图像没有字符层面的标注,从而非常有益于训练文字识别器。为充分利用这些真实数据,本文提出一个互监督机制。对于没有字符标注的图像实例,只通过序列层面的标注信息,便可实现两个分支的预测的互监督。结果,TextScanner 可以充分利用全部现有的训练信息,包括合成的和真实的文字图像在内。
3.方法
概述
本文方法的整体架构如图 2 所示,这一网络的解码器由两个分支组成:1)类别分支;2)几何分支。
- 类别分支
TextScanner 的类别分支产生字符分割图,它直接来自由 CNN backbone 提取的可见特征;分支的预测模块由两个堆叠的卷积层组成,核大小分别是 3x3 和 1x1。分支通过在类别维度上应用 Softmax 归一化以生产字符分割图。
- 几何分支
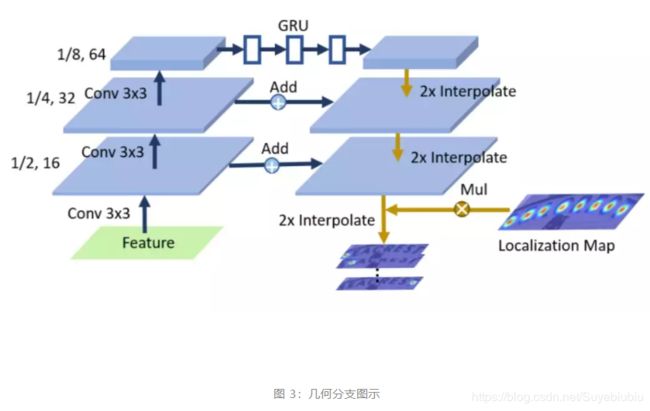
首先,借助 Sigmoid 激活函数,从和类别分支相同的可见特征生成一个字符定位图。同时,采用一个自上而下的金字塔结构生成顺序分割图。尤其,下采样路径顶层的特征图被 RNN 模块编码以建模上下文。遵从上采样路径,通过两个卷积层生成顺序分割图,它同样也被 Softmax 归一化。接着,一个顺序图可通过逐元素相乘被顺序分割图的第 k 个通道和字符定位图计算。几何分支细节如图 3 所示。
预训练(通过字符标注)
当在合成数据上预训练时,TextScanner 可使用字符标注实现优化。
- 标签生成
由于弯曲或者密集文字中的正方形并不精确,本文保留了字符区域多边形的定义。为避免由相邻字符的边所造成的重叠,多边形字符的边界框借助 Vatti 裁剪算法被收缩至一个区域,其中相应字符的类别被渲染为字符分割的 groud truth。为生成带有字符标注的顺序图的 groud truth,高斯图的中心首先被检测,通过计算字符边界框的中心点。
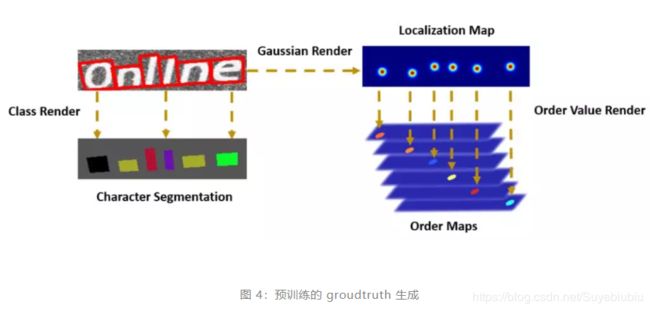
如图 4 所示,为每个字符生成 2D 高斯图和中心点期望值,接着字符的顺序按照 2D 高斯图区域内的像素做渲染,最后,每个字符的顺序图 groundtruth 被归一化为 [0, 1] 。
- 损失函数
整个损失函数是上述三个任务所有损失的加权总和:
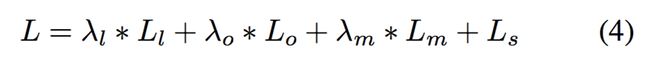
定位损失图被计算为一个平均平滑的 L1 损失。顺序分割和字符分割的损失被计算为预测分值和相应 ground truth 之间的交叉熵。在交叉熵计算中,两个分割任务重的背景类别被忽略。
互监督机制
为减少对字符标注的依赖,本文提出互监督机制,它是基于 TextScanner 的双分支结构。如图 2 所示,可通过结合字符分割图 G 和顺序图 H 生成文字的顺序。给定一个字符标签和两个结果中的一个,可以生成另一个结果的监督信号。
给定文字顺序标签 T,从它的第一个字符到最后一个执行互监督。在 T 中的第 k 个字符,它的顺序是 k,类别是 T(k):
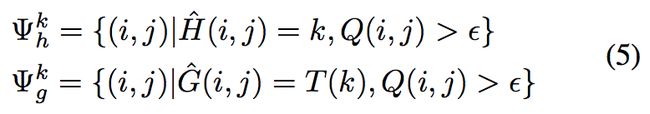
而互监督的形式如下所示:
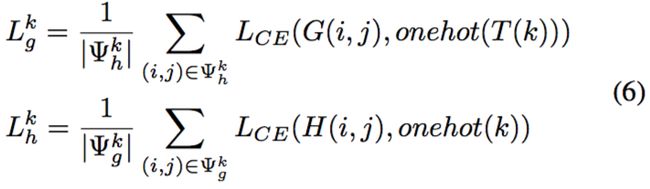
互监督过程的第一步如图 5(a)所示:

过程执行到 T 的最后一个字符。请注意,在一个选择中选择了 Gˆ 的多个区域,因为字符在 T 中出现多次,因此不能用于 H 的监督,如图 5(b)所示。因此从交叉监督过程中去掉这些实例。
G 和 H 的置信度标示为:
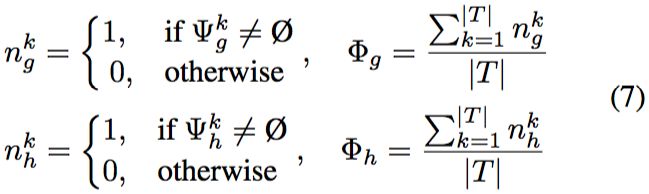
4.实验
本文在基准数据集上进行了一系列实验,以评估 TextScanner 的性能,并与其他方法做了对比,具体实验结果请见表 1:
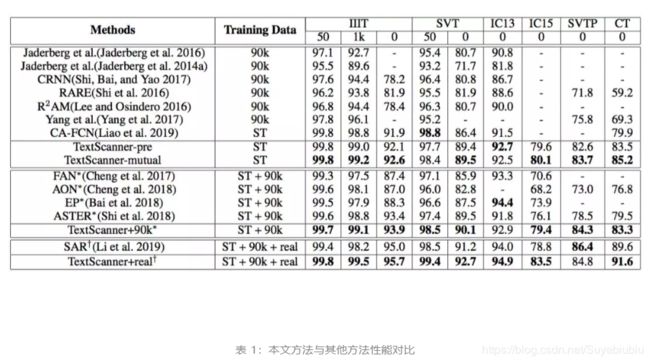
标准数据集
表 1 给出了不同方法在标准基准上的识别精度,其中既有常规文字数据集如 IIIT,SVT,IC13,也非常规数据集如 IC15,SVTP,CT。
TextScanner 的自然建模使其在棘手实例上更鲁棒,比如文字是弯曲的或有向的。如表 1 所示,TextScanner 的三个变体在相同数据集上超越全部先前方法。尤其是在弯曲文字方面,使用合成数据训练的 TextScanner+90k,在数据集 IC15,SVTP,CT 上,分别取得了 3.3% ,4.1% ,4.0% 的提升。
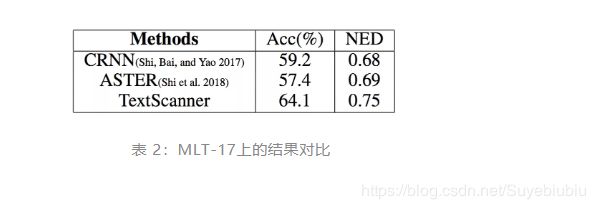
中文数据集
为进一步验证 TextScanner 的汉字识别性能, 本文与两个较有代表性的汉字识别方法 CRNN 和 ASTER 做了性能对比,量化结果如表 2 所示:
字符定位精度
对于两个注意力解码器和 TextScanner 而言,注意力位置或者字符定位的精确预测对识别非常关键,由于两者都生成字符中心点,本文在数据集 IC13 上对比了字符定位性能,方法是测量宽度轴上已生成的字符中心点和 groundtruth 中心点之间的归一化距离,其概率密度如图 7 所示:

5.结论
旷视研究院在本文中提出 TextScanner,一个高效的基于分割的双分支的场景文字识别框架,它克服了先前方法的困难和缺点,并不不同的具有挑战性的场景下表现良好。
其中,一个全新的互监督机制的提出,使得充分利用真实和合成数据成为可能。另外,TextScanner 还在处理困难文字方面表现出较强的适应性。
参考文献
-
Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
-
Cheng, Z.; Bai, F.; Xu, Y.; Zheng, G.; Pu, S.; and Zhou, S. 2017. Focusing attention: Towards accurate text recognition in natural images. In ICCV 2017, 5086–5094.
-
Li, H.; Wang, P.; Shen, C.; and Zhang, G. 2019. Show, attend and read: A simple and strong baseline for irregular text recognition. In AAAI, volume 33, 8610–8617.
-
Liao, M.; Zhang, J.; Wan, Z.; Xie, F.; Liang, J.; Lyu, P.; Yao, C.; and Bai, X. 2019. Scene text recognition from two-dimensional perspective. In AAAI.
-
Long, S.; He, X.; and Ya, C. 2018. Scene text detection and recognition: The deep learning era. arXiv preprint arXiv:1811.04256.
-
Phan, T. Q.; Shivakumara, P.; Tian, S.; and Tan, C. L. 2013. Recognizing text with perspective distortion in natural scenes. In 2013 IEEE International Conference on Computer Vision, 569–576.
-
Jaderberg, M.; Simonyan, K.; Vedaldi, A.; and Zisserman, A. 2014a. Deep structured output learning for unconstrained text recognition. arXiv preprint arXiv:1412.5903.
-
Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; and Bai, X. 2018. Aster: An and attentional scene and text recognizer and with flexible and rectification. In PAMI, 1–1. IEEE.
-
Risnumawan, A.; Shivakumara, P.; Chan, C. S.; and Tan, C. L. 2014. A robust arbitrary text detection system for natural scene images. Expert Systems with Applications 41(18):8027 – 8048.
-
LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P.; et al. Gradient-based learning applied to document recognition. 1998. Proceedings of the IEEE 86(11):2278–2324.
-
Lee, C.-Y., and Osindero, S. 2016. Recursive recurrent nets with attention modeling for ocr in the wild. In CVPR, 2231–2239.