【论文阅读ACL2020】Leveraging Graph to Improve Abstractive Multi-Document Summarization
题目:Leveraging Graph to Improve Abstractive Multi-Document Summarization (基于图表示的生成式多文档摘要方法 )
会议:ACL2020
论文地址:https://arxiv.org/abs/2005.10043
其他:出自百度NLP小组工作

这个是百度 NLP 小组在 ACL2020 上面的一篇工作,当前多文档摘要应用场景和需求也越来越多,接下来我将就论文主要内容做介绍。
目录
1.多文档摘要
2.抽取式 VS 生成式
3.相关工作
4.动机
5.三种显式图结构
6.GraphSum Model
6.1 图感知的自注意力机制
6.2 层次化图注意力机制
6.2.1 Global Graph Attention
7.结合通用预训练模型
8.MDS数据集
9.实验结果
9.1 模型分析
9.2 ablation study消融实验
9.3 人工评估
10.结论
11.问题总结
1.多文档摘要

首先多文档摘要顾名思义就是对多篇文档内容压缩成组,然后生成一份简洁的描述。那么相对于单文档摘要,多文档摘要面临了一些新的挑战。第一个就是多文档输入非常冗长。 多文档建模相对单文档建模,需要建模文档内和跨文档关系。多文档在生成摘要的过程中希望对来自不同文档的多元信息进行有效的组织,从而生成一份连贯的摘要。
2.抽取式 VS 生成式

常见的多文档摘要方法主要分为两类。第一类是生成式方法,另外一种是抽取式方法。抽取式方法相对简单。主要是从输入文档中集中选择重要的句子组成一份摘要。通常面临不可避免的缺陷。比如句子之间不够连贯,或者句子之间包含一些冗余的信息等等。而生成式方法相对困难,他需要对输入的多篇文档进行有效的理解,对多元信息进行一个有效的组织,形成新的句子来描述整个文档级核心信息。
3.相关工作

我们接下来回顾一下多文档摘要的相关工作。多文档摘要我们可以简单分为四个阶段。
第一个阶段主要是抽取式相关工作,其中比较有代表性的是图排序的方法。通过对文档级句子关系图进行排序,选择重要的句子。
第二个阶段是基于句法信息或者篇章结构的生成式方法,更准确的说是压缩式方法,其中包括句子压缩式和句子融合式的方法。
第三个就是基于神经网络序列到序列生成式方法。早期这种生成式方法主要是用在单文档摘要上面,由于多文档摘要缺乏大规模数据集,所以早期基本工作主要是将这种单文档摘要的方法适配到多文档摘要的任务上面。在这个过程中也有两份比较重要的工作,有 2018 年提出的 T-DMCA 方法,首次提出多文档摘要大规模数据集wikisum,其中包含 150W 的训练样本。第二个是 Fabbri 在 2019 年提出的 HierMMR方法,首次提出中等规模面向新闻的多文档摘要数据集multinews,本文的后面的工作也是基于这两个数据集展开的。
第四个阶段就是在拥有这种大规模数据集之后,针对多文档输入的特点进行的模型结构上面一些设计。其中代表性的是 liu 在 2019ACL 上的一篇工作,提出了层次化的 Hierarchical Transformer模型,对输入的多篇文档进行层次化编码表示。另外一个工作也是 ACL2020 同时期的一个工作。利用了图神经网络进行建模,形成一个抽取式的方法。
4.动机

我们这份工作主要面向的是生成式多文档摘要,我们首先回顾一下生成式多文档摘要面临的一些困难。生成式多文档摘要主要分为两个阶段,第一个阶段就是对多篇输入文档进行编码。 在这个阶段我们主要困难是输入冗长,我们需要有效的对文档内和跨文档关系进行建模,第二个阶段对应的是摘要生成阶段,我们需要对来自不同文档多元信息进行有效的重新组织。从而生成这种连贯的摘要。

在这份工作中作者提出,利用文档级显式关系图来解决上述挑战性问题。这种结构关系图,在传统抽取式方法中有非常广泛的应用,特别是在基于图排序的方法,但是在基于神经网络生成模型中没有得到有效的利用。这份工作我们提出将显式的图结构信息引入到神经网络生成式模型之中,从而有效的解决多文档输入的编码和摘要解码过程中遇到的挑战性问题。
5.三种显式图结构

接下来我们看一下显式的图结构信息,我们主要实验验证了三种显式图结构信息。第一类是相似度图,主要是基于句子或者段落这种 TFIDF 的词汇相似度构建而来,这类图在传统图排序抽取式方法中得到了很多的应用。第二类图是主题关系图。我们通过对文档中句子或者段落进行主题建模,然后计算他们的主题相关性从而构建他们的主题关系。第三类图对应的是篇章结构图,这类图在传统工作中也得到了很多的应用。我们可以利用文本中篇章指示词例 如因为所以,以及共指关系,指代关系构建一个篇章图。这种篇章图结构在之前的抽取式方法中也有一些应用。接下来我们介绍我们如何把这样一些文档级显式图结构信息引入到我们神经网络之中。
6.GraphSum Model
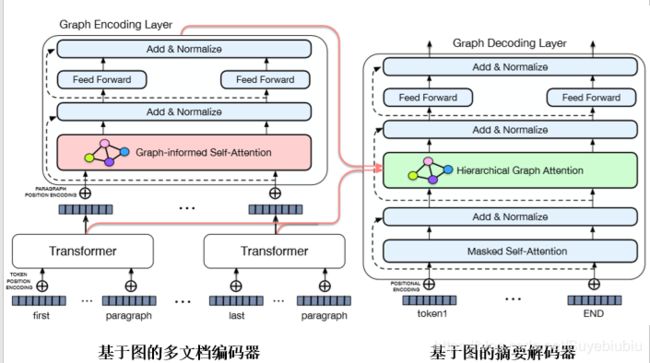
为此我们提出了一种多文档生成式摘要模型。GraphSum Model,我们的模型主要有两个部分,第一个部分是基于图的多文档编码器,第二部分是基于图的摘要解码器。
我们对输入文档切分成不同的段落,然后我们基于 transformer 模型对每一个段落进行独立的编码,得到每一个段落的表示。我们进一步进入我们的图编码层,我们在图编码器中,我们基于图感知的自注意力机制引入输入文档级的显式图结构信息,将这种显式图结构信息融入到编码过程中,从而提升多文档输入的编码效果。 另一部分,在摘要解码过程中,我们设计了一个基于图的摘要的解码层。其中一个核心模块是层次化的图注意力机制。可以将输入文档级的显式的图结构信息引入到摘要的解码过程中,利用这种图结构信息,来引导我们整个摘要解码过程。
6.1 图感知的自注意力机制

接下来我们具体看一下,图感知的自注意力机制, 首先得到文档输入级显示图结构信息,将边上的权重归一化到 0 到 1 之间,构成了一个权重图,然后利用高斯转换函数,将显式的图结构转化为一个图编码矩阵。这个矩阵编码了我们图结构信息。我们继续把这个图编码矩阵引入到自注意力机制中,图感知的注意力机制就包括两个模块。第一个模块就是传统的自注意力机制模块,基于段落的向量表示 来建模段落之间隐式关系。第二个模块就是输入的文档级段落的显示图结构信息,我们将图结构信息引入到段落的编码过程中从而得到一个更好的多文档输入的编码表示,更好的建模段落之间语义关系。
6.2 层次化图注意力机制
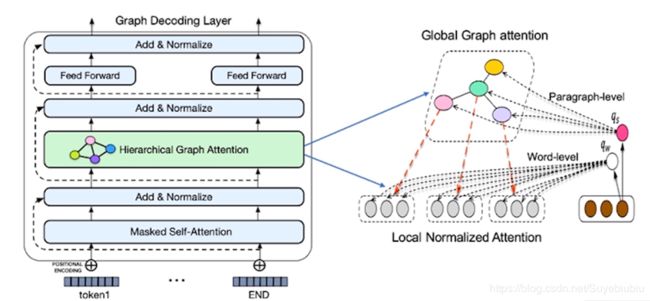
在解码过程中,我们的层次化图注意力机制主要包括两个层次。第一层对应的是段落级全局图注意力机制,第二层对应的是词汇级的局部归一化注意力机制。我们词级的注意力权重是基于段落级注意力权重进行的一个加权归一化。我们在段落级全局图注意力机制中,引入输入文档级的图结构信息。利用我们的图结构信息来引导我们的摘要解码过程。
6.2.1 Global Graph Attention
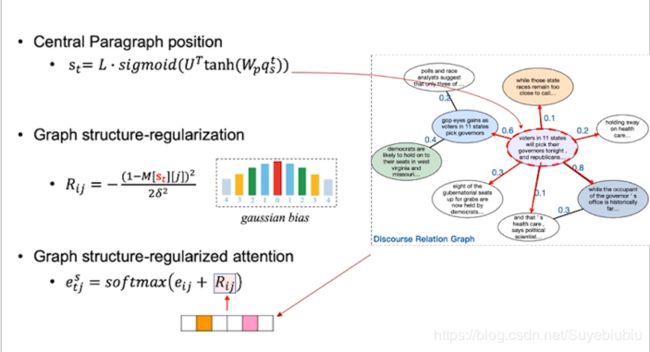
具体的,我们基于当前解码步的向量表示, 首先定位一个它的中心段落,进一步基于我们的图结构,得到当前段落和其他所有段落之间的图结构关系。我们将这个图结构关系,利用我们的高斯转化函数,转化成一个图结构的向量。 我们把这个向量引入我们的摘要解码器上下文注意力机制中,然后利用图结构信息,来对上下文注意力机制进行一个约束或者是正则化。从而实现我们利用显式图结构信息来引导整个摘要解码的过程。
7.结合通用预训练模型

我们的模型也可以和各种通用的预训练模型进行结合。例如常用的通用预训练模型:bert,roberta,xlnet,百度的 ernie。我们可以简单的将这种输入的段落拼接成序列,然后利用通用预训练模型进行编码表示。基于每个段落前的 CLS TOKEN 做整个段落的表示,进一步输入到我们的图编码层中,进行 段落级图编码。然后利用我们的图解码器解码,生成摘要。
8.MDS数据集


本文工作主要是在 wikisum 和 multinew 这两个大规模多文档摘要数据集上进行的。Wikisum 他的输入对应的是 wiki 百科对应的参考文献以及基于 wiki 百科的 title 标题在搜索引擎中检索回来的相关页面。输出是 wiki 百科第一个段落。由于我们的输入中参考文献和搜索引擎检索结果信息非常冗余杂乱。我们进一步对这种输入的文档进行了段落的切分,然后基于段落和标题之间的相关性对段落进行了 一个排序。我们取 toprank 的排序的段落作为整个模型的输入。这个数据集大概有 150W 的 训练集,3.8W 的验证和测试集。
另一个数据集是 mult-news,是传统的新闻摘要数据集。输入对应多篇新闻文档,输出对应的是人工编辑的摘要。
9.实验结果
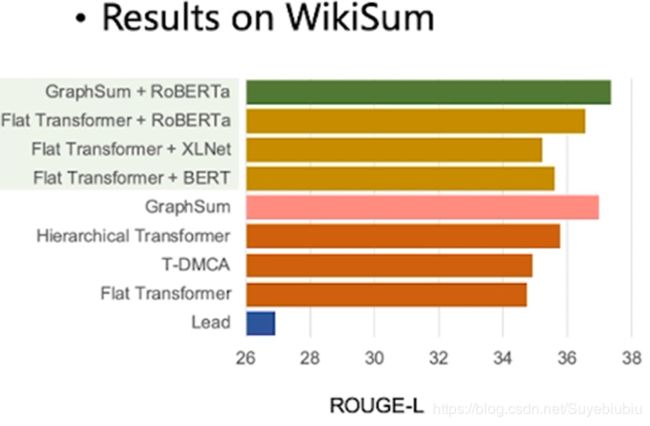
接下来我们看一下实验结果。首先在 wikisum 数据集上,我们的模型是显著超越了之前的模型。进一步来看一下我们 graphsum 模型和各种通用预训练模型结合的表现。我们首先将 flat transformer 的 encode,替换成各种通用预训练模型。 从而设计了三个强有利的模型。因为 robert 在摘要任务上任务表现最好,我 们让它和我们的模型结合,可以看到表现显著。这结果可以说明即使在有 robert 这种大规模预训练模型上,我们在这种端到端建模过程中,引入这种显式图结构信息,对于多文档摘要这个任务也是非常有用的。同时它也超越了下面单独使用 graphSum 模型,说明在其基础 上,进一步融合预训练模型,多文档摘要效果还有进一步提升的空间。
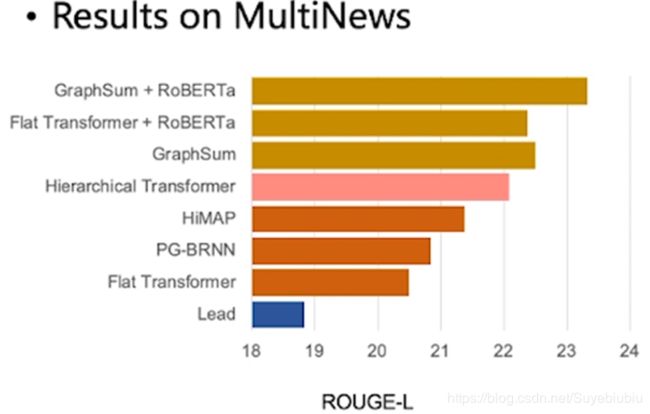
我们在 multnews 也得到了类似的结果,表现优异。
9.1 模型分析

我们对模型进一步分析,首先我们在 multinews 数据集上,基于我们的 graphsum 和 rebort 模型对比分析不同的显式图结构信息,对于多文档摘要的影响,我们对比分析了相似度图,主题关系图,篇章结构图三种图结构。实验结果看出:主题关系图 rouge1 和 2 明显超过了相似关系图。而我们篇章结构图在 rouge2 和 rougeL 超越了主题关系图。这个结果可以表明当我们给模型输入更加丰富的语义关系的图结构的时候,对于整个多文档 摘要效果是有明显提升的。
我们进一步分析不同输入长度对整个模型效果的影响,因为多文档摘要一个主要挑战就是输入非常长,来自于多篇文档。我们和之前sota的模型 HT 对比。在五种不同长度下,可以看出,当我们输入文档越长的时候,我们相对 ht 模型优势越大。这个结果表明我们输入越长, 图结构信息越来越有效。
9.2 ablation study消融实验

本文进一步对模型也做了消融验证试验,我们通过将图编码器和图解码器中图结构信息去掉。我们可以看到模型效果会有一个显著的下降。这个结果也表明显式图结构信息,无论在多文档输入编码过程中还是在摘要的解码过程中,都有非常重要的作用。
9.3 人工评估

因为这部分工作对应的是生成式多文档摘要。那么 rouge 这种评价指标,通常很难评价一个生成模型的流畅性。我们进一步进行了一个人工评估。我们通过让数据标注语言对 5 个系统 摘要结果进行了按照摘要质量从 1 到 5 排序。左边这张图展示了各个系统摘要质量排在第 一的比例关系。可以看到我们 graph 和 graph 结合 roberto 模型显著超越了其他模型。右面这张图进一步对每一个系统从 1 到 5 按照 2 分 1 分 0 分-1-2 进行打分计算每一个系统的平均得分。可以看到 Graph 和 graph 结合 roberta 模型也是显著超越其他三个系统。
10.结论

最后我们对整个工作进行一个总结: 我们通过大量的实验验证和分析,可以看到显式图结构信息对多文档摘要是非常有效的。 我们利用一种简洁的方式将显式图结构信息引入到神经网络中。我们也提出将 graph 模型同各种预训练模型相结合的方式。通过结合更有效的预训练模型,我们模型也有进一步提升空间。第三个就是我们模型在两个数据集上相比之前 sota 生成式多文档摘要模型取得显著提升。
11.问题总结

