利用python爬虫抓取虎扑PUBG论坛帖子并制作词云图
作为一个PUBG迷,刷论坛是每天必不可少的事,上面有很多技术贴和职业比赛的帖子,突发奇想,想知道论坛里谈论最多的是什么,便做了一个爬虫爬取了论坛上最新的帖子标题和部分回复,然后利用jieba与wordcloud进行分词然后做了一个词云图。
爬虫的构建与数据的爬取
首先导入制作爬虫需要的包:
from bs4 import BeautifulSoup
import requests
import pandas as pd
import chardet
import numpy as np生成爬虫的函数:
'''
creat beautifulsoup
'''
def creat_bs(url):
result = requests.get(url)
e=chardet.detect(result.content)['encoding']
#set the code of request object to the webpage's code
result.encoding=e
c = result.content
soup=BeautifulSoup(c,'lxml')
return soup
这里利用了chardet.detect自动检测所获取网页内容的编码并转化,防止request识别错误。
接着构建所要获取网页的集合函数:
'''
build urls group
'''
def build_urls(prefix,suffix):
urls=[]
for item in suffix:
url=prefix+item
urls.append(url)
return urls接下来便可以开始获取论坛帖子标题与帖子链接,首先观察一下PUBG论坛首页的html代码:
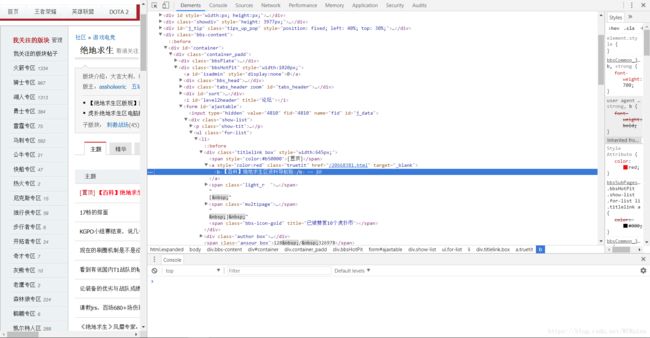
可以看到我们要爬取的帖子标题所在的标签,但是html的常识告诉我,这个标签表示加粗,从左边的网页显示也可以看出字体被加粗了。我们再往下看:

没有加粗的标题并没有标签。看清了网页的代码,便可以开始编写爬虫了:
'''
acquire all the page titles and links and save it
'''
def find_title_link(soup):
titles=[]
links=[]
try:
contanier=soup.find('div',{'class':'container_padd'})
ajaxtable=contanier.find('form',{'id':'ajaxtable'})
page_list=ajaxtable.find_all('li')
for page in page_list:
titlelink=page.find('a',{'class':'truetit'})
if titlelink.text==None:
title=titlelink.find('b').text
else:
title=titlelink.text
if np.random.uniform(0,1)>0.90:
link=titlelink.get('href')
titles.append(title)
links.append(link)
except:
print 'have none value'
return titles,links首先寻找未加粗标题,如果没有标题,则寻找加粗标题。另外由于帖子数量太多,便按10%的概率储存帖子地址。为了避免未搜寻到标签等异常产生,使用了try-except忽略所有异常。
接着,编写爬取回复的函数,同样,先看看网页代码构架:

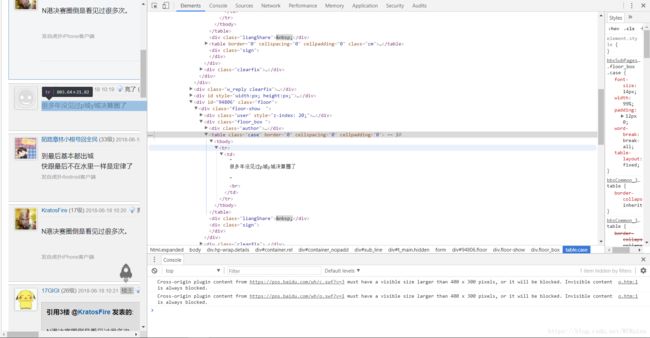
可以看到,主楼是由并且class='floor'的标签所包含,但其id='tpc',而普通回复是由同样的标签包含,但其id为回复用户的编码。由于爬取主楼出现一些奇怪的错误,最后决定就不爬取主楼只爬取回复:
'''
acquire reply in every topic of 10 page
'''
def find_reply(soup):
replys=[]
try:
details=soup.find('div',{'class':'hp-wrap details'})
form=details.find('form')
floors=form.find_all('div',{'class':'floor'})
for floor in floors:
table=floor.find('table',{'class':'case'})
if floor.id!='tpc':
if table.find('p')!=None:
reply=table.find('p').text
else:
reply=table.find('td').text
replys.append(reply)
elif floor.id=='tpc':
continue
except:
return None
return replys
构建完函数后,便可以开始爬取数据了,首先创建爬取页面的url集合,这次我选择了前30页贴子进行爬取:
'''
acquire information from hupu pubg bbs
'''
url='https://bbs.hupu.com/pubg'
page_suffix=['','-2','-3','-4','-5','-6','-7','-8','-9','-10','-11','-12',
'-13','-14','-15','-16','-17','-18','-19','-20','-21','-22','-23','-24',
'-25','-26','-27','-28','-29','-30']
urls=build_urls(url,page_suffix)
爬取标题与链接:
title_group=[]
link_group=[]
for url in urls:
soup=creat_bs(url)
titles,links=find_title_link(soup)
for title in titles:
title_group.append(title)
for link in links:
link_group.append(link)
接着爬取所选帖子的第一页回复:
reply_urls=build_urls('https://bbs.hupu.com',link_group)
reply_group=[]
for url in reply_urls:
soup=creat_bs(url)
replys=find_reply(soup)
if replys!=None:
for reply in replys:
reply_group.append(reply)
爬取完毕后,综合所有数据并保存:
'''
creat wordlist and save as txt
'''
wordlist=str()
for title in title_group:
wordlist+=title
for reply in reply_group:
wordlist+=reply
def savetxt(wordlist):
f=open('wordlist.txt','wb')
f.write(wordlist.encode('utf8'))
f.close()
savetxt(wordlist)由于使用beautifulsoup解析网页内容时会自动将数据转码成unicode形式,所以如果是中文网页在输出时要转码成utf-8,不然就是乱码了。
好了,网页爬取部分已经完成,接下来就可以开始词云图的制作了。
词云图的制作
首先我们使用第三方库jieba进行中文的分词。导入jieba包:
'''
using jieba to splice words in title group
'''
import jieba
为了使其分词更加准确,我们可以导入自己设置的分词词典,尤其是在论坛的回复中,经常会有一些别称或者俗语等,利用普通的分词规则很难准确区分,这时自制的分词词典就很有用了:
jieba.load_userdict('user_dict.txt') 可以看看我设置的词典,由于时间关系,只是写了一些印象深刻的词:

后面的数字代表词频,虽然我也不知道具体是什么意思,就随便设置了数字。
接着进行分词:
wordlist_af_jieba=jieba.cut_for_search(wordlist)
wl_space_split=' '.join(wordlist_af_jieba)
分词完后,便可以开始制作词云图了,导入所需包:
from wordcloud import WordCloud,STOPWORDS
import matplotlib.pyplot as plt
首先设置停止词,去掉一些连词或者语气词等,这里我们可以上网下载中文常用停止词词典:
stopwords=set(STOPWORDS)
fstop=open('stopwords.txt','r')
for eachWord in fstop:
stopwords.add(eachWord.decode('utf-8'))
最后,制作词云图:
wc=WordCloud(font_path=r'C:\Windows\Fonts\STHUPO.ttf', background_color='black',max_words=200,width=700,height=1000,stopwords=stopwords,max_font_size=100,random_state=30)
wc.generate(wl_space_split)
wc.to_file('hupu_pubg2.png')
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')由于是中文,我们需要使用font_path设置中文可用的字体。max_words设置显示的最大词数,max_font_size设置词最大的大小,random_state设置颜色的随机程度。
输出图像:

还不错,从图像中可以看到游戏名当之无愧成了高频词汇,还有包括4AM战队,PCPI比赛,加速器,决赛圈等热词。但是很遗憾不知道是因为中文分词的原因还是词云图制作的原因,所有和数字有关的词全都被剔除了,所以少了很多和17有关的热词。具体原因还有待挖掘。