canal介绍及HA集群模式搭建
快速了解canal
1.首先大概介绍一下canal是干啥的?
canal是用来实时同步mysql数据的。对于离线任务可以通过sqoop将mysql业务库的数据导入hive数仓中计算,但是想要处理实时任务就要借助canal解析binlog日志来实现了。
官网的详细介绍: https://github.com/alibaba/canal/wiki
2.canal是如何实时获取mysql数据的?
canal服务伪装成mysql的从节点,接收mysql主节点的binlog日志(binlog日志文件里面记录了数据库的实时操作),然后解析binlog就知道mysql做了哪些操作。
在数据实时同步方案中
跟mysql的binlog日志类比的有
sqlserver同步采用的cdc,(或者给表添加rowversion,唯一缺点就是不能识别具体是更新还是插入操作)
mongodb副本集模式的oplog
通过解析这些数据库的操作凭证文件就可以实时同步数据,处理实时任务
开启mysql的binlog
这是使用canal同步mysql数据的前提,必须要开启binlog,否则canal解析什么?
1.查看mysql是否启用binlog
show variables like '%log_bin%'
显示bin_log的值为ON则表示开启,OFF则为关闭
2.开启binlog日志
配置my.cnf(linux下的mysql)或者my.ini(windows下的mysql)开启binlog日志,添加以下内容
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
3.创建canal访问账号
在MySQL中创建一个专门的canal访问账号,账号密码都为canal(这个可以自定义,只需在后面canal的配置文件中写的即可)
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT
ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
canal的HA集群模式部署
canal服务的部署其实特别简单,解压之后只需配置两个文件即可(canal.properties;instance.properties)
下面讲一下具体配置流程:
先在一台机器上部署服务,执行以下1-4步
1.首先要下载canal
下载地址 https://github.com/alibaba/canal/releases
2.解压到安装目录
tar -zxf canal.deployer-1.1.3.tar.gz
解压出来的目录结构是这样的
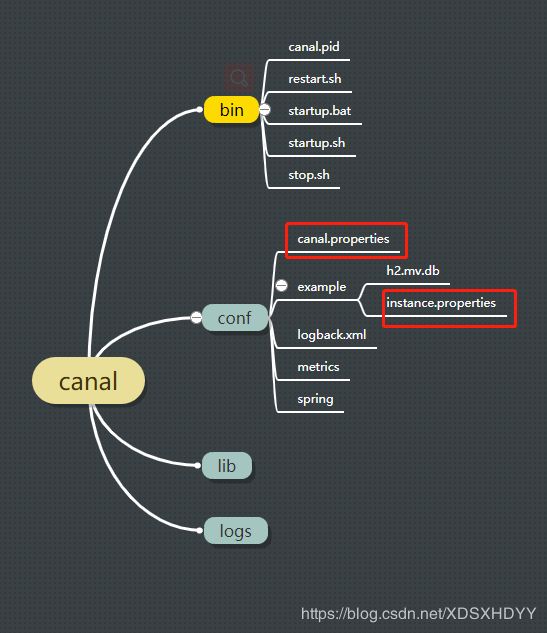
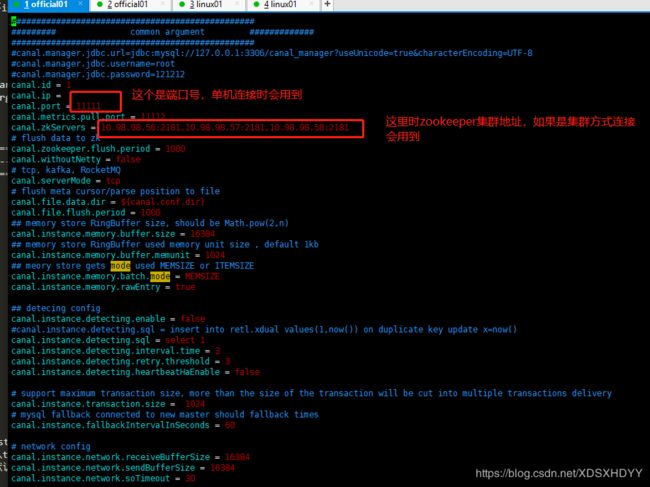
3.修改配置文件canal.properties
canal.zkServers=192.168.135.27:2181,192.168.135.28:2181,192.168.135.29:2181
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
canal.destinations = example
(这个example就是conf目录里的实例,如果要建别的实例'test'就建个test目录,把example里面的instance.properties文件拷贝到test的实例目录下就好了,然后在这里的配置就是canal.destinations = example,test)
配置太长了,下面两张图是一起的

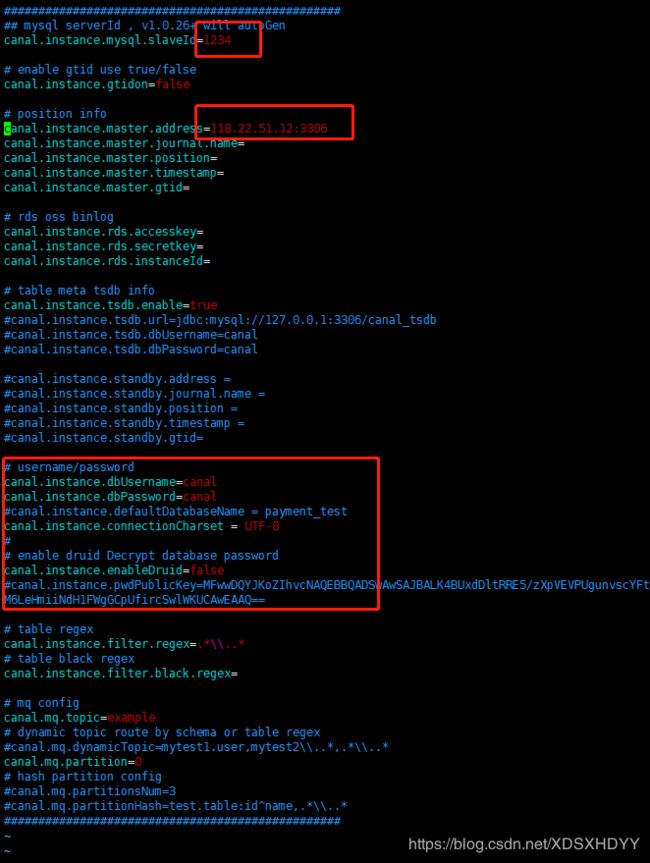
4.修改配置文件instance.properties
canal.instance.mysql.slaveId = 1234 ##另外一台机器改成1235,保证两台机器上的slaveId不重复
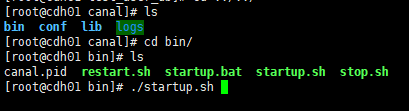
到此为止就部署好了单台canal服务,可以进入到bin目录下启动canal服务
代码里面客户端连接的时候就可以采用单节点方式连接
CanalConnector mConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.135.27", "11111"), "example", "", "");
HA集群模式的部署
在另外一台机器上再做一次上面同样的操作,只是第4步的
instance.properties中的canal.instance.mysql.slaveId(canal伪装的mysql slave的编号,不能与mysql数据库与其他的slave重复。)不一样。其余一模一样。
至此HA集群模式配置好了。HA模式在启动的时候要两台机器都启动canal服务,然后由zookeeper自动管理active和standby状态。
客户端连接服务的时候就可以采用集群方式连接了
基于zookeeper动态获取canal server的地址,建立链接,其中一台server发生crash,可以支持failover
CanalConnector connector = CanalConnectors.newClusterConnector("192.168.135.27:2181", "example", "", "");
理解canal的server和instance
server代表一个canal运行实例,相当于一个jvm
instance相当于一个数据队列,即一个mysql实例 (1个server可以对应多个instance)
server对应的properties配置文件:
canal.properties (系统根配置文件)
instance对应的properties配置文件:
instance.properties (instance级别的配置文件,每个instance一份)
可以监听多个数据库,每个数据库一个文件名一个配置文件,就像刚刚上面介绍的example和test这俩个实例
另,再附上client端连接服务端解析binlog日志,再将解析的数据发到kafka的代码
github地址