机器学习之优化算法
在机器学习中,由于问题解的计算量通常很大,一般会采用迭代的方式来进行优化求解。最常用的优化算法包括:梯度下降法(BGD、SGD、MBGD)、坐标上升法(Coordinate Ascent)、牛顿法和拟牛顿法等。
1、梯度下降法(Gradient Descent)
梯度下降法是最简单常用的最优化方法之一。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向。梯度下降法越接近目标值,步长越小,前进越慢。
一种直观解释:比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
梯度下降法不一定能找到全局最优解,速度也未必是最快的,但当目标函数(损失函数)是凸函数时,梯度下降法的解一定是全局最优解。
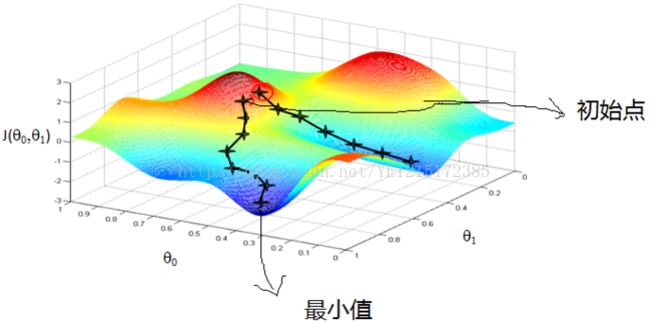
梯度下降法根据每次迭代时训练样本的参与情况,可以分为三种:批量梯度下降法(Batch Gradient Descent)、随机梯度下降法(Stochastic Gradient Descent)、小批量梯度下降法(Mini-batch Gradient Descent)。
拿线性回归模型为例,假设下面的h是要拟合的函数,J为损失函数,theta是需要求解的向量参数,要迭代求解的值。其中m是训练集的样本个数,n是特征的个数。


1.1、批量梯度下降法(BGD)
将J对theta求偏导,得到每个theta分量对应的的梯度:

设alpha为迭代步长,每个theta分量的更新如下:
从上式可以看出,每迭代一步,都要用到所有训练样本,当m很大时,迭代速度会相当的慢,计算量为m*n*n。所以,由此产生了随机梯度下降法。
1.2、随机梯度下降法(SGD)
alpha任为迭代步长,每个theta分量的更新改为如下:
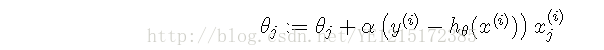
可以从上式看出,随机梯度下降法每次迭代只使用一个训练样本,其计算量只需n*n,所以随机梯度下降法迭代一次的速度要远快于批量梯度下降法。但是SGD带来的问题是收敛速度不如梯度下降,也就是说为了达到同样的精度,SGD需要的总迭代次数要大于梯度下降,但是,单次迭代的计算量要小得多。SGD最小化每个样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。所以:如果想快速得到一个可以勉强接受的解,SGD比BGD更加合适,但是如果想得到一个精确度高的解,应当选择BGD。
1.3、小批量梯度下降法(MBGD)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用q个样子来迭代,1
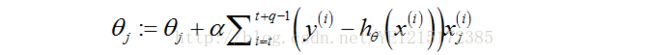
2、坐标上升法(Coordinate Ascent)
考虑如下无约束优化问题:
其中,W是向量α 的函数。参数α的更新如下,直到算法收敛:

在该算法的内循环中,除了α 的第i个分量当做变量,其它值都固定,使用前一次迭代的值。坐标上升法的迭代过程如下图所示:
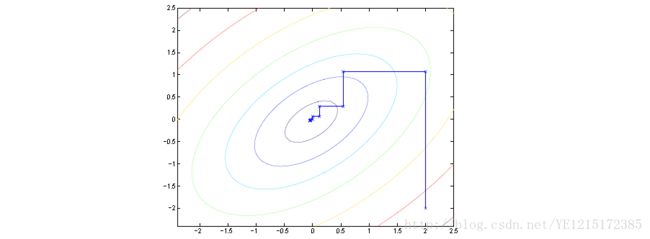
上图中一圈一圈的椭圆表示优化函数或损失函数的轮廓。由于每一步值优化一个变量,所以坐标上升法的每一步在图中的连接线都平行于优化变量所对应的坐标轴。
3、牛顿法和拟牛顿法
牛顿法使用函数f (x)的泰勒展开来寻找方程f (x) = 0的根。将 f (x)在 x0 做一阶Taylor展开:

则有:
所以:

只要不停的迭代,x的值便会不断接近最优解。因此,x的迭代公式可以写成:

牛顿法的迭代过程如下图所示:

对于损失函数L(theta),最小化L也就是求L的导数为0的解。所以,参数theta的更新公式如下:
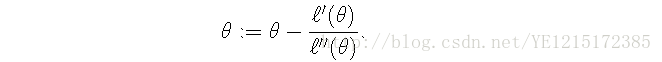
当theta是一个向量时,牛顿法在此时关于theta的更新公式可以表示为:
其中,H表示Hessian矩阵:
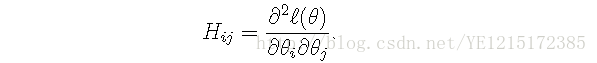
牛顿法具有二阶收敛性,每一轮迭代会让误差的数量级呈平方衰减。即在某一迭代中误差的数量级为0.01,则下一次迭代误差为0.0001,再下一次为0.00000001。而梯度下降是一阶收敛,所以牛顿法收敛速度更快,但是大规模数据时,Hession矩阵的计算与存储将是性能的瓶颈所在。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。
针对Hession矩阵的计算与存储问题,提出了拟牛顿法。拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。常用的拟牛顿法例如:DFP算法、BFGS算法。
参考文献:
1、吴恩达机器学习
2、http://blog.csdn.net/owen7500/article/details/51601627
3、https://zhuanlan.zhihu.com/p/22402784
4、http://blog.csdn.net/qsczse943062710/article/details/76763739