Tensorflow入门2(模型训练,模型评估)
模型训练
接着上一节,模型已经用y = tf.nn.softmax(tf.matmul(x,W) + b)实现,现在来训练它,但是怎么才能知道训练得好不好呢?所以我们需要定义一个指标来评估模型的好坏,然后让这个指标最小,这个指标一般是成本(cost)或损失(loss),不过这两种方式其实也是一样的。常用的一个好用的成本函数叫交叉熵(cross-entropy)(感觉回到了高等热力学)。交叉熵产生于信息论里面的信息压缩编码技术,不过后来转到博弈论/机器学习等领域的评估手段,看下定义:
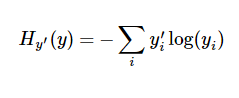
其中y是预测的概率分布,y’是实际的分布(就是输入的one-hot vector).可以把它理解为预测用于描述争相的效果如何的量度。这个概念还是很重要的。
为了计算交叉熵,做一个上面的y’,用y_代替
y_ = tf.placeholder("float", [None,10])计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))其中,tf.log(y)是计算y的对数。然后将y_和tf.log(y)里的元素相乘,最后用tf.reduce_sum来计算张量所有元素的总和。(这个地方的交叉熵不是用单一的一对预测值真实值,而是用所有的图片的交叉熵的总和,这样能更为准确的描述我们模型的性能。)
那么现在需要模型做什么呢?其实Tensorflow训练的过程是很简单的,tf有一张描述各个小计算单元的图,它可以自动的使用反向传播算法(backpropagation algorithm)来有效的确定你的变量是如何影响你最想要的最小化成本的那个值,你要做的告诉它你想把什么最小就行,tf自己会优化变量以降低成本。设置每一步的训练:
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)这里是用丽梯度下降法,以0.01的速率最小化交叉熵。梯度下降算法是一个简单的学习过程,不知道的童鞋可以自行百度。想使用其他算法,只需要更改这行代码就行。
Tensorflow在这个过程中所做的是在后台描述计算的图中增加了一系列的新的操作单元用来实现反向传播和梯度下降算法,它返回回来的是一个单一操作,运行这个操作时,它用梯度下降训练了你的模型,微调你的变量,不断减少成本。
现在模型已经设置好了,想要运行,还需要增加一个操作来初始化创建的变量:
init = tf.initialize_all_variables()现在在一个Session里面启动我们的模型,并初始化变量:
sess = tf.Session()
sess.run(init)现在来训练模型,这里训练1000次:
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})在循环的步骤中,每步都会随机抓取训练数据的100个批处理数据点,然后用这些点替换之前的数据点的占位符来运行tran_step.
使用一小部分的随机数据来进行的训练被称为随机训练(stochastic training) 在这里更确切的说是随机梯度下降训练。在理想的情况下,我们希望用我们的所有数据来进行进一步的训练,因为这能给我们更好的训练结果,不过这必然会需要很大的开销,所以,每一次训练我们可以使用不同的数据子集,这样既可以减少计算开销,又可以最大化学习到数据的总体特性。
模型评估
训练好之后,怎么知道模型的好坏呢?
模型评估就得运用到上一节中,最开始的测试数据集了。用模型来预测图片,然后进行标签比对。tf.argmax是一个非常有用的函数,它的返回值是某个tensor对象在一维上的其数据最大值所在的索引值。标签向量是由0和1组成,因此最大值1所在的索引位置就是类别标签,例如说tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而tf.argmax(y_,1)代表正确的标签,而用tf.equal来检测预测标签是否与真实标签相匹配。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))这串代码返回的是一串匹配结束的布尔值,为了确定正确预测项的比例,可以将布尔值转换为浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,在训练的模型上看一看正确率吧:
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})结果是0.905这个结果其实很差,但这只是一个学习范例嘛,最一些改进后可以得到97%的正确率。最好的可以达到99.7%。要理解这里面的思想,一个是深度学习闹明白了没。一个是Python的实现问题。