ceph IO切割成对象和对象名的组成(块存储)
看到很多关于oid-->pgid-->osdid映射的文章。 但是 读写IO到-->oid的映射,却没有相关的文章。
我认为一个完整的映射关系应该是这样的:read write IO---->oid---->pgid---->osdid 。下面我们重点研究下read write IO---->oid的映射关系。
一, 读写IO的组成
读写IO,最基本的元素是:
1,offset #在磁盘上的偏移位置
2, length #需要读或者写的长度
3, data #需要读取的数据
二,对象名的组成

一个对象文件名有5部分组成
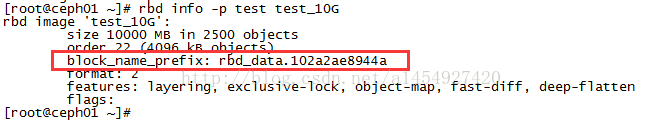
1, rbd\udata.102a2ae8944a
rbd镜像里块的前缀,可以用rbd info查看, 通过他可以查找出对象和镜像的从属关系
2,0000000000000000
对象的序号,每次通过读写IO的 offset 除以对象大小4M,然后取整数,生成。
比如:offset 假如为 4194035, 那么4194035/ 4194034 最后结果为1 ,那么这次IO就写在对象的序号为0000000000000001的对象上。
从上面可以看出,对象是以4M,按序切分的。
假如写入一个20M大小IO 写,产生的对象序号如下:

可以发现,对象的序号非常有序,并且这些对象按序号拼接,刚好组成一个镜像里的数据。
3,__head_
这个指对象在head目录下
4,9577E02B
这个是对象的哈希值,和文件夹的分层有关系。比如:对象数量很多,一个目录容纳有点吃力,目录分层性能更好一些
例如:
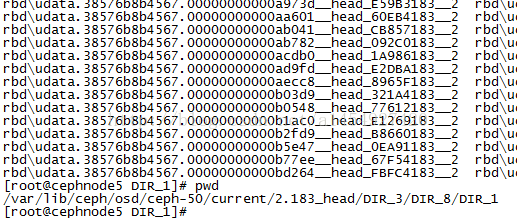
可以看到对象分层后缀为183的,正好在/DIR_3/DIR_8/DIR_1目录下,而且正好是反的。pg下面对象的目录被分了3层。
5,__1
1表示 pool id
三,一个大的IO读写请求,怎么切分成具体对象的读写
1,对象名称的生产
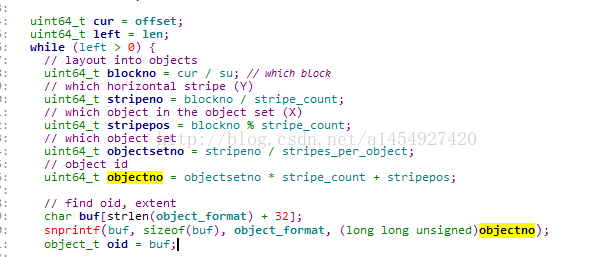
cur就是读写IO的 offset,su就是4M大小。 cur/su,得到的bockno即为对象的序号,
stripe_count为1, stripes_per_object 为 1。 最后算出objectno,即为最终的序号。
最后通过字符串拼接,把block_name_prefix + objectno= oid
2,把业务系统的IO 长度和偏移值,转换为对象里的IO长度和偏移值
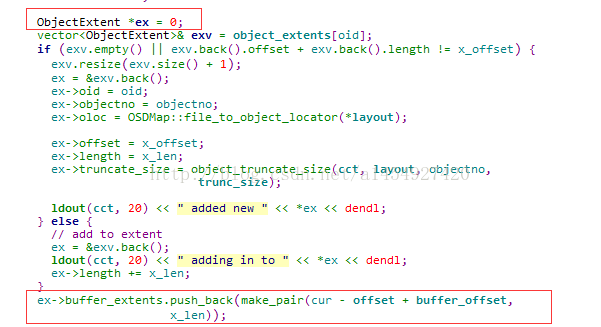
按照4M大小对业务系统IO切割后,把对象的偏移值写入ObjectExtent类的对象ex。
3,根据ObjectExtent类里的偏移值和长度对业务系统的数据buf,进行切割,切割成碎片后,放到bufferlist里
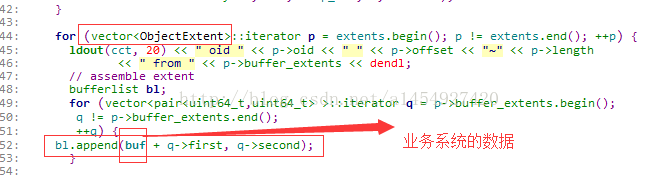
四,一个读IO,分切成若干读对象任务后返回
一个读取IO的操作,需要切分成很多对象读操作,当取得若干对象里的数据后,需要合并成一个大的返回值
1,首先把读取到的每个对象的数据,写到 Striper::StripedReadResult 这个类的partial里面,这个过程叫做收集
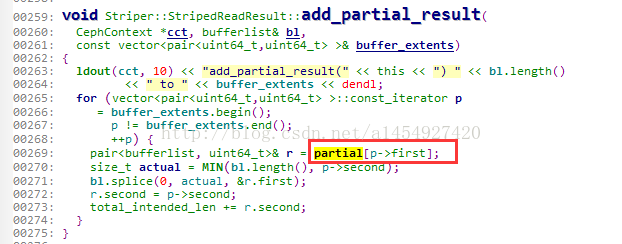
2,把partial里的值,全部写入bufferlsit,合并成一个完整的返回值,这个过程叫合并
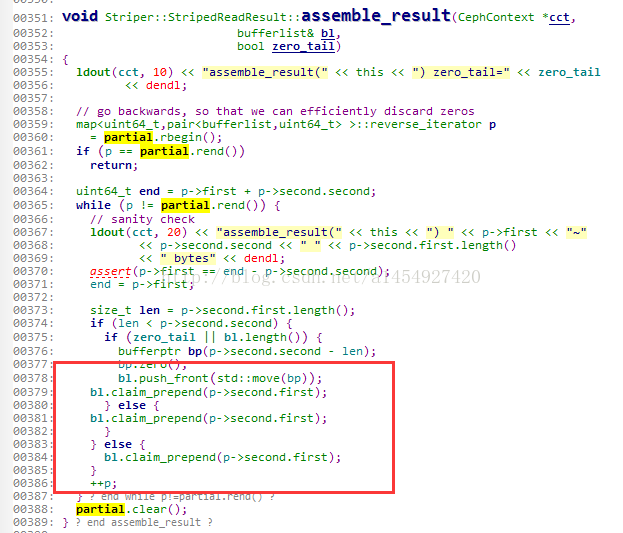
五, 读写IO在对象文件里的表现形式
不是所有对象都是4M大小的。即使对象的最大大小设定为4M
假如写一个1M数据的IO,落到对象里面,造成的对象文件大小,可能为1M,2M,3M,4M,等等,都有可能。关键看数据在对象内的偏移值。
下面做个实验,假如从业务系统写入一个1M大小的数据,偏移位置为2M
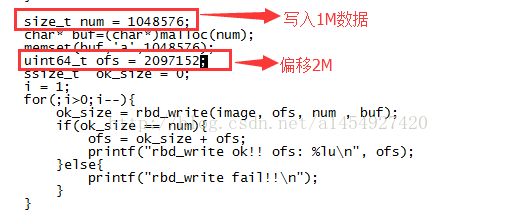
集群的大小如下
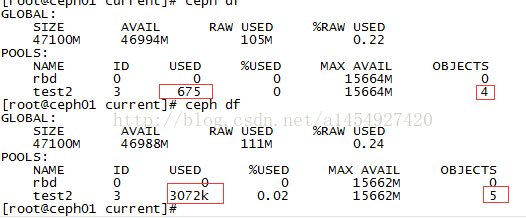
集群从4个对象,变成5个,从675个字节大小,变成3072K,也就是3M。
再看对象文件的大小
![]()
对象文件也为3M大小。
为什么写入1M的数据,对象文件是3M大小? 其实对象文件是根据偏移值来填充了。当数据落到对象文件里的位置确定后,偏移位置之前全部填充NUL值
![]()
在文件2M的偏移位置,2M之前是NUL值,2M之后为写入的真实数据,字符串"aaaaaaa....."
所以这就是为什么随机IO,对集群的存储空间占用非常大,因为随机IO在对象文件内造成了随机的落点位置
六,对象的名字,在数据恢复中的应用。
通过以上结论,得出,rbd image下的所有对象,包含了image里的所有数据。
当一个ceph集群死亡后,如果数据盘里的数据还完整。我们依然可以通过对象拼接出一个rbd image。用于数据的恢复
方法为:
1,收集想要恢复的image下的所有对象,通过rbd info中的block_name_prefix
2,把对象,通过dd命令拼接出整个image的数据文件
3,把恢复好的image数据文件导入新的ceph集群
官网上给出命令和脚本
官网:http://ceph.com/geen-categorie/ceph-recover-a-rbd-image-from-a-dead-cluster/