cephfs 的数据与元数据组织形式 (cephfs探索二)
cephfs 文件系统,由数据和元数据2部分组成。元数据即目录和文件。数据就是文件里的数据和内容。
不管数据还是元数据,最后在底层filestore层,都以对象文件的形式存储。
一,cephfs相关模块
1,ceph-fuse,cephfs-kernel
ceph客户端有2种模式,使用ceph-fuse挂载为应用层模式,使用内核的mount - ceph挂载是内核模式。
用户使用客户端挂载cephfs成本地文件夹后,访问ceph集群。
2,ceph-mds
这是cephfs元数据的内存缓存,为了加快元数据的访问,里面有元数据的cache,也有类似journal一样保持数据 一致性的日志系统。ceph-mds core dump了,并不会引起数据丢失,他仅仅是个缓存,数据已经持久化保存在osd上。重启mds的时候会通过replay的方式从osd上加载之前缓存的元数据。
3,ceph-osd
cephfs文件系统里的数据(文件内容)和元数据(目录,文件)最后都以对象文件的形式保存在osd上。
二,数据
cephfs的文件里的数据会被切分为4M大小的对象文件。假如有一个20M大小的文件,会被切分成5个对象文件
1,下面我们做一个实验,在cephfs文件系统里写入一个20M的文件
![]()
2, 查看文件的inode号为:1099511627776
![]()
3,这个inode号是10进制的,我们用计算器换算成16进制,正好等于10000000000
然后查看文件系统数据池里的对象 rados ls -p cephfs_data

4,总结下上面的实验结果: 一个20M的文件被切分成5个对象,对象的名称为文件的inode号.偏移值。
偏移值是在内核里切割文件时给出的。(具体怎么切割和发送数据的,且听下回分解)
三,元数据
上面解释了文件里的数据是怎么存放的,下面我们解释下文件名和目录是怎么存放的。以及目录树是怎么构建的。
一个文件系统的目录,是树形状的,首先是树的根"/" ,然后根据根"/"的元数据dentry,可以找到子目录元数据存储的位置(即子目录的dentry和inode)。逐层遍历,最后形成整个文件系统树的关联关系。
1,文件系统的元数据。
一个文件系统本身也有元数据,superblock,根目录的元数据,等相关信息。当我们创建一个cephfs文件系统的时候,不用往文件系统里写数据,就会产生一些对象,用来保存文件系统本身的元数据。下面为初创文件系统的元数据相关对象
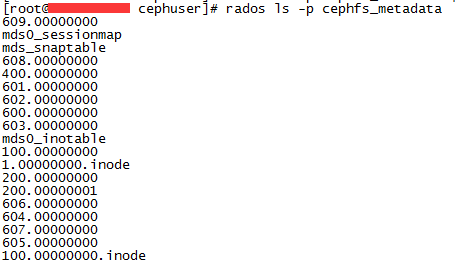
这些对象里除了保存了文件系统的元数据,还用做保存cephfs日志,日志是用来恢复mds里的元数据缓存,和还没有应用成对象的元数据。
2, 目录的保存方式
cephfs里面元数据写入首先写入日志mdlog,然后再把日志里的元数据应用到对象上。下面我们创建一个目录,并且强制让他应用成对象。
创建目录fsaaaaa

fsaaaaa的inode号为1099511627860,换算成16进制为:10000000054
因为创建目录后,首先元数据只是提交到了日志里,还没有应用成对象,下面我们强制元数据刷新成对象
ceph daemon /var/run/ceph/ceph-mds.hc-25-60-4.asok flush journal
 return 0 ,刷新成功
return 0 ,刷新成功
查看生成的元数据对象。
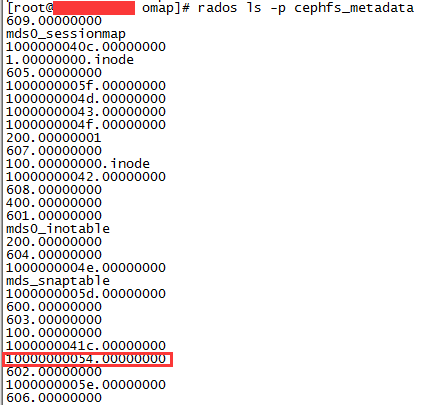
这样我们的fsaaaaa目录就保存到了到了10000000054.00000000这个对象里
3,文件元数据的保存方式
我们cd进fsaaaaa目录,创建一些文件和文件夹,继续测试

我们发现,只能找到目录的元数据对象,不能找到文件元数据对象。

我个人认为因为文件没有下级目录,所以没必要单独弄一个对象来保存元数据,只需要保存在上级目录的元数据里面
4,目录和子目录,子文件的关联关系
每个目录的元数据都保存了下级目录和文件的名称,以及inode号
我们查看下fsaaaa目录的元数据,fsaaaaa对应的对象名为:10000000054.00000000
rados -p cephfs_metadata listomapvals 10000000054.00000000
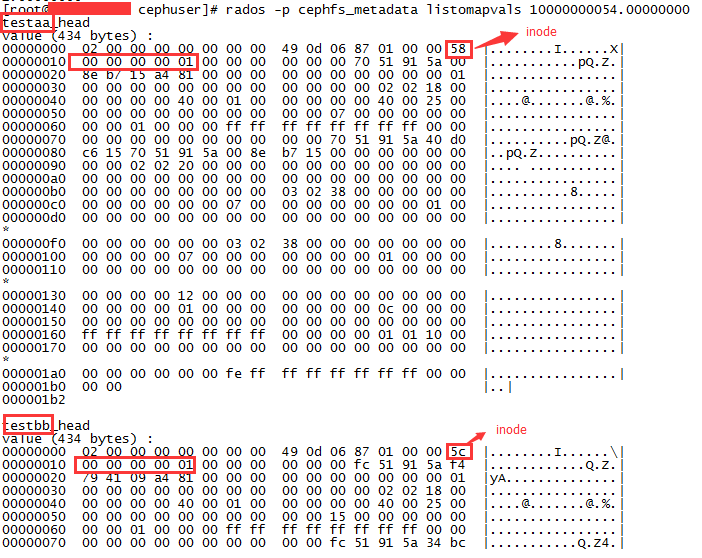

我们可以看到fsaaaaa目录的对象里保存了子目录和子文件的名称和inode编号(注意:因为linux是小端模式,看内存数据得倒着看),这样就可以建立一个文件系统数的元数据对应关系。
四,应用
理解数据关系,可以很好的理解cephfs的设计思路,并且可以做元数据的备份和恢复,即使mds不起作用了,我们也能从对象文件中恢复出一个文件系统。