spark--RDD
spark--RDD
- 1. RDD
- 2. RDD操作
- 2.1 转化操作
- 2.1.1 filter 过滤
- 2.1.2 union 并集
- 2.1.3 map 替换
- 2.1.4 flatMap 合并替换
- 2.1.5 intersection 交集
- 2.1.6 subtract 差集
- 2.1.7 cartesian 笛卡尔积
- 2.1.8 sample 采样
- 2.1.9 转化操作速查表
- 2.2 行动操作
- 2.2.1 count 计数
- 2.2.2 reduce 聚合
- 2.2.3 collect 装载
- 2.2.4 countByValue 元素计数
- 2.2.5 take 取值
- 2.2.6 top 取前n个--降序
- 2.2.7 takeOrdered 取前n个--升序
- 2.2.8 takeSample 采样N个元素
- 2.2.9 fold 指定初始值聚合
- 2.2.10 aggregate 指定返回类型聚合
- 2.2.11 行动操作速查表
- 3. 惰性求值
- 4. 函数传递
- 5. 持久化(缓存)
1. RDD
spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。
存在两种方式创建RDD:
- 读取程序外部数据集
- 程序内构建RDD
举例:
![]()

RDD支持两种操作:转化操作和行动操作。
转化操作和行动操作最大的区别是:转化操作不会进行计算;行动操作会触发计算操作。
默认情况下,行动操作都是spark重新开始计算,如果需要中途保存一些转换操作的中间结果,可以使用persist保存。
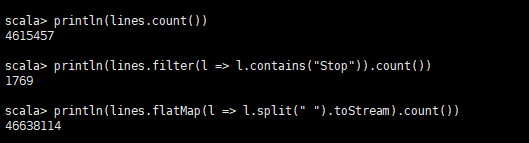
val lines = sc.textFile("hdfs://host-10-0-228-117:8020/data/real.log")
lines.persist()
println(lines.count())
println(lines.filter(l => l.contains("Stop")).count())
println(lines.flatMap(l => l.split(" ").toStream).count())
![]()
2. RDD操作
RDD支持两种操作:转化操作和行动操作。RDD的转化操作是返回一个新的RDD的操作:

RDD的行动操作是返回指定值的操作:
![]()
2.1 转化操作
2.1.1 filter 过滤
格式
RDD filter( => )
过滤,根据返回的boolean值决定是否加入。
val StopLines = lines.filter(l => l.contains("Stop")
2.1.2 union 并集
格式:
RDD1 union RDD2
合并,将两个RDD合并为一个RDD。

2.1.3 map 替换
格式:
RDD map ( => )
该方法接收一个参数,计算结果作为返回值,构建新的结果集
val nums = sc.parallelize(List(1,2,3,4))
println(nums.collect.mkString(","))
val doubleNums = nums map ( x => x * x)
println(doubleNums.collect.mkString(","))

2.1.4 flatMap 合并替换
格式:
RDD flatMap ( => )
flatMap是将多个流合并为1个流
//创建初始RDD[String]
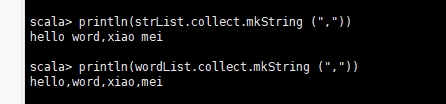
val strList = sc.parallelize(List("hello word","xiao mei"))
//新流根据旧流的每一个元素产生,产生的方式是将旧的元素每一个以空格进行分割,将每个元素分割后的流合并为一个流
val wordList = strList flatMap (str => str split " ")
//输出
println(strList.collect.mkString(","))
println(wordList.collect.mkString(","))

2.1.5 intersection 交集
格式:
RDD1 intersection RDD2
val num1 = sc.parallelize(List(1,2,3))
val num2 = sc.parallelize(List(2,3,4))
val allHaveNum = num1 intersection num2
println(allHaveNum.collect.mkString(","))

2.1.6 subtract 差集
格式:
RDD1 subtract RDD2
val num1 = sc.parallelize(List(1,2,3))
val num2 = sc.parallelize(List(2,3,4))
val subNum = num1 subtract num2
println(num1.collect.mkString(","))
println(num2.collect.mkString(","))
println(subNum.collect.mkString(","))

2.1.7 cartesian 笛卡尔积
格式:
RDD1 cartesian RDD2
val num1 = sc.parallelize(List(1,2,3))
val chr = sc.parallelize(List("a","b","c"))
val chrnum = num1 cartesian chr
println(num1.collect.mkString(","))
println(chr.collect.mkString(","))
println(chrnum.collect.mkString(","))

2.1.8 sample 采样
格式:
RDD sample (Boolean , Double, seed)
第一个Boolean参数是表示采样是否就可以重复
第二个Double参数表示采样分数:当不可以重复采样时,这个分数表示采样命中率,取值范围[0,1];当可以重复采样时,这个分数表示采样重复次数,取值范围[0,+)
第三个参数是随机数种子,建议默认。
val nums = sc.parallelize(List(1,2,3,4,5,6,7,8,9,10))
val sample1 = nums.sample(false,0.5)
println(sample1.collect.mkString(","))
val sample2 = nums.sample(false,1)
println(sample2.collect.mkString(","))
val sample3 = nums.sample(true,2))
println(sample3.collect.mkString(","))

2.1.9 转化操作速查表
| 操作名 | 方法名 | 格式 |
|---|---|---|
| 过滤 | filter | RDD filter ( => ) |
| 并集 | union | RDD1 union RDD2 |
| 替换 | map | RDD map ( => ) |
| 合并替换 | flatMap | RDD flatMap ( => ) |
| 交集 | intersection | RDD1 intersection RDD2 |
| 差集 | subtract | RDD1 subtract RDD2 |
| 笛卡尔积 | cartesian | RDD1 cartesian RDD2 |
| 采样 | sample | RDD sample (Boolean,Double,seed) |
2.2 行动操作
2.2.1 count 计数
格式
RDD count
val nums = sc.parallelize(List(1,2,3,4))
println(nums count)

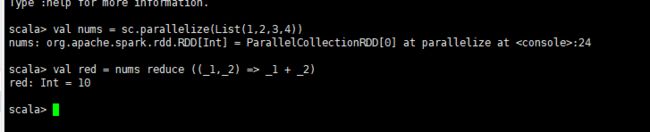
2.2.2 reduce 聚合
格式:
RDD reduce ( => )
val nums=sc.parallelize(List(1,2,3,4))
val red = nums reducce ( (_1,_2) => _1 + _2))
2.2.3 collect 装载
格式:
RDD collect
强制进行计算,并返回计算结果。(注意,要求单机能够全部装载RDD)
val nums = sc.parallelize(List(1,2,3,4))
val col = nums collect
println(col.mkString(","))

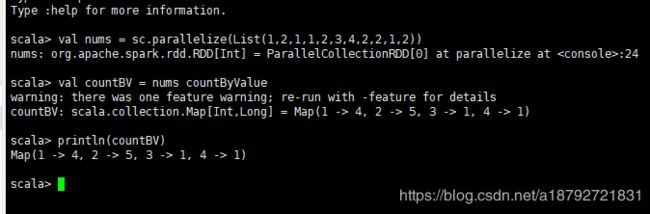
2.2.4 countByValue 元素计数
格式:
RDD countByValue
val nums = sc.parallelize(List(1,2,3,2,1,2,3,4,2,1,2,1))
val countBV = nums countByValue
println(countBV)
2.2.5 take 取值
格式:
RDD take Integer
val nums = sc.parallelize(List(1,2,3,4,5))
val subNums = nums take 4
println(subNums)

2.2.6 top 取前n个–降序
格式:
RDD top Integer
val nums = sc.parallelize(List(1,1,2,3,4,4,5))
val topN = nums top 3
println(topN)

2.2.7 takeOrdered 取前n个–升序
格式:
RDD takeOrdered Integer
val nums sc.parallelize(List(3,2,1))
val tod = nums takeOrdered 2
println(to)

2.2.8 takeSample 采样N个元素
格式:
RDD takeSample(Boolean,Integer,seed)
Boolean是否可以重复采样
Integer采样个数
seed随机数种子
val nums = sc.arallelize(List(1,2,3,4,5,6,7,8,9,10))
val ts1 = nums takeSample(false,3)
val ts2 = nums takeSample(false,3)
val ts3 = nums takeSample(false,3)
val ts4 = nums takeSample(false,3)
val ts5 = nums takeSample(false,3)

val t1 = nums takeSample(true,12)
val t2 = nums takeSample(true,12)
val t3 = nums takeSample(true,12)
val t4 = nums takeSample(true,12)
val t5 = nums takeSample(true,12)
val t6 = nums takeSample(true,12)
注意,如果不允许重复采样,且,采样个数大于总个数,会返回全部数据。所以,虽然指定了采样个数,但是返回值依然有可能不等于采样个数。
2.2.9 fold 指定初始值聚合
格式:
RDD fold (initValue)( => )
val nums = sc.parallelize(List(1,2,3,4,5),1)
val f = nums.fold(3)( _1,_2 => _1 + _2)
3+3+1+2+3+4+5=21
计算过程:
RDD是分布式分区数据结构,所以在fold里面存在两步计算:
1.计算分区内的数据:初始值3加上分区内元素3+1+2+3+4+5=18
2.合并分区计算结果:因为只有一个分区,所以3+18=21

val nums = sc.parallelize(List(1,2,3,4,5),5)
val f = nums.fold(3)(_+_)
3+3+1+3+2+3+3+3+4+3+5=33
1.5个分区内元素计算:
3+1
3+2
3+3
3+4
3+5
2.分区合并
3+ 3+1 + 3+2 +3+3 +3+4 +3+5 = 33

2.2.10 aggregate 指定返回类型聚合
格式:
RDD aggregate(initValue)( => , => )
initValue初始值
第一个 => 初始值与分区内元素转义
第二个 => 是分区内元素聚合计算
aggregate的返回值的类型由初始值确定
val nums = sc.paralleliize(List(1,2,3,4,5),1)
val a = nums.aggregate(3)(_1,_2 => _1 + _2, _1,_2 => _1+_2)

val nums = sc.parallelize(List(1,2,3,4,5),1)
val aa = nums.aggregate(0,0)((init,e) => (init._1+e,init._2+1),(e1,e2) => (e1._1 + e2._1,e1._2 + e2._2))
println(aa._1/aa._2.toDouble)
首先,初始值是一个元组,指定了这个aggregate的返回值是一个元组。
第一个 => 的第一个参数是初始值,第二个参数是分区内第一个元素。然后 => 定义了分区内元素如何进行与初始值的计算以及转义
第二个 => 的两个参数是分区内的元素迭代,定义了分区内的元素如何进行聚合
当然,如果还隐式的包含了分区间的结果聚合。

2.2.11 行动操作速查表
| 操作名 | 方法名 | 格式 |
|---|---|---|
| 计数 | count | RDD count |
| 聚合 | reduce | RDD reduce( => ) |
| 装载 | collect | RDD collect |
| 元素计数 | countByValue | RDD countByValue |
| 取值 | take | RDD take Integer |
| 降序取前N个 | top | RDD top Integer |
| 升序取前N个 | takeOrdered | RDD takeOrdered Integer |
| 采样N个元素 | takeSample | RDD takeSample(Boolean,Integer,seed) |
| 指定初始值聚合 | fold | RDD fold (initValue)( => ) |
| 指定返回类型聚合 | aggregate | RDD aggregate(initValue)( => , => ) |
3. 惰性求值
spark在调用转化操作的时候,不会进行计算,只有调用行动操作的时候,才会进行计算。这对大数据处理是有利的:我们调用sc.textFile时,并没有将文件真正读取进来,进行filter等操作的时候,也没有进行过滤。只有当调用count的时候,才会真正开始读取文件。这样做有一个好处:在读取的时候进行判断,如果判断符合条件,才会真正读取进入内存,如果不符合,那么在读取之后,就从内存中出去数据,以降低内存的占用。
4. 函数传递
在scala中,我们可以把定义的内联函数,方法的引用或者静态方法传递给spark,就像scala的其他函数式API一样。当然,还需要考虑其他的一些细节:传递的函数及其引用的数据可序列化;传递一个对象的方法或者字段时,会包含整个对象的引用。所以,尽可能将需要的字段放在局部变量中,避免将整个对象传递。
class MyFunction(val test: String) {
def isEqual(str: String): Boolean = {
str.contains(test)
}
def getEqualReference(rdd: RDD[String]): RDD[String] = {
// 这里实际使用的是this.isEqual,需要将this传入
rdd.map(isEqual)
}
def getSplitTestReference(rdd: RDD[String]): RDD[String] = {
// 这里实际使用的是 this.test,需要将this传入
rdd.map(x => x.split(test))
}
def getSplitTestRR(rdd: RDD[String]): RDD[String] = {
// 这里传入的是 this.test,不会将this传入
val test_ = this.test
rdd map (x => x split test_)
}
}
5. 持久化(缓存)
spark RDD是惰性求值的,而有会对一个RDD进行一次转化操作,多次行动操作。
因为惰性求值的存在,导致每次行动操作,都会执行一次转化操作。
当数据量较大时,转化操作是一件非常耗费资源的计算过程。
所以,可以将转化操作的结果持久化,后续的行动操作,基于持久化的数据进行操作,这样能够减少资源的耗费。
在持久化的时候,存在不同的持久化级别。
| 级别 | 使用的空间 | CPU时间 | 是否在内存中 | 是否在磁盘上 | 备注 |
|---|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | |
| MOMERY_AND_DISK | 高 | 中等 | 部分 | 部分 | 当数据在内存中放不下,溢写到磁盘上 |
| MOMERY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 当数据在内存中放不下,溢写到磁盘上 |
| DISK_ONLY | 低 | 高 | 否 | 是 |
在scala和Java中,默认情况下persist会把数据已序列化的形式缓存在JVM的堆空间中。
如果有必要,可以在存储级别的末尾加上_2将持久化数据存储2份。
如果缓存的数据太多,内存中放不下,spark会自动利用最近最少使用的缓存策略把最老的分区从内存中移除。对于使用MEMORY_ONLY等的缓存级别的数据,下一次使用已经移除的数据分区的时候,就需要重新计算。对于使用MEMORY_AND_DISK等或者DISK_ONLY级别的缓存,被移除的分区会写入磁盘。
不过,不论是哪一种场景,都不会打断作业的计算。当然
,如果缓存太多不必要的数据,导致需要不断的计算或者读取分区数据,也是一笔很大的开销。
val nums = parallelize(List(1,2,3,4,5))
val newnums = nums map ( x => x*x )
newnums.persist(StorageLevel.DISK_ONLY_2)
newsums count
newsnums countByValue
newsnums collect

只在第一次调用行动操作的时候会进行转化操作,后面的行动操作都不会再次调用转化操作。
如果不进行缓存,每次都会重新调用转化操作。