hadoop集群搭建--虚拟机克隆、ssh免密登录
虚拟克隆、shh免密登录
- 虚拟机克隆
- 关闭防火墙
- 修改网卡名称
- 修改hosts文件
- 安装jdk:
- 克隆
- 克隆虚拟机客户端
- 网络配置
- 问题-解决办法
- ssh免密登录
虚拟机克隆
在克隆之前,即将被克隆的虚拟机已经配置好网络。如果还没有,可以参考鄙人博文,链接:minimal版的网络配置
关闭防火墙
我测试了下,如果克隆前,被克隆的虚拟机关闭并阻止开机启动防火墙,那么克隆后的新虚拟机的防火墙就不需要再次关闭了,默认就是关闭了。
查看firewall的状态:
[hadoop@min1 ~]$ firewall-cmd --state
running
查看firewall服务状态:
[hadoop@min1 ~]$ systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active:active (running)since Fri 2019-09-27 14:45:53 CST; 2min 25s ago
Main PID: 3188 (firewalld)
CGroup: /system.slice/firewalld.service
└─3188 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
关闭防火墙:
关闭:
[hadoop@min1 ~]$ sudo systemctl stop firewalld.service
取消开机启动
[hadoop@min1 ~]$ sudo systemctl disable firewalld.service
查看下状态:
[hadoop@min1 ~]$ systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
防火墙关闭成功!
修改网卡名称
centos7装好后的原生网卡名称是eno16777736,我在未修改网卡名称的情况下克隆虚拟机,克隆后的新虚拟机网卡名称被改变了(可以通过ip addr查看到网卡名称),这样,在配置网络的时候,如果不修改网卡名称,网络就配置不成功。这是我克隆后遇到的实际问题,所以我在这个位置先说明一下,免得克隆后又一台一台的修改或者删除已经克隆的机器,修改网卡后再克隆。把自己犯过的错遇到过的问题尽早分享出来,可以节省大家的时间。
进入网卡目录
[hadoop@min1 network-scripts]$ cd /etc/sysconfig/network-scripts/
[hadoop@min1 network-scripts]$ ll
total 232
-rw-r--r--. 1 root root 142 Sep 26 15:41 ifcfg-eno16777736
-rw-r--r--. 1 root root 254 Sep 16 2015 ifcfg-lo
......
#我这里的文件名是:ifcfg-eno16777736
重命名网络配置文件:
adoop@min1 network-scripts]$ sudo mv ifcfg-eno16777736 ifcfg-eth0
修改ifcfg-eth0文件:
[hadoop@min1 network-scripts]$ sudo vi ifcfg-eth0
修改完之后:
TYPE=Ethernet
BOOTPROTO=static
NAME=eth0 #修改name
DEVICE=eth0 #修改device
ONBOOT=yes
IPADDR=192.168.8.101
NETMASK=255.255.255.0
GATEWAY=192.168.8.2
再修改grub:
[hadoop@min1 sysconfig]$ sudo vi /etc/sysconfig/grub
在rhgb quietde 的前面加上net.ifnames=0 biosdevname=0的(有看网上介绍是加在quiet后面的,我也有加在后面成功过的经历,但是这次加在后面就灭成功过,也不知道是哪里出了问题,我甚至都加乐规则了,但还是不行。最后我就加在现在这个位置了,结果成了,不过这是在一台克隆后的新虚拟机上尝试的。)

加完之后的样子:
[hadoop@min1 ~]$ cat /etc/sysconfig/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap net.ifnames=0 biosdevname=0 rhgb quiet"
GRUB_DISABLE_RECOVERY="true"
执行命令:sudo grub2-mkconfig -o /boot/grub2/grub.cfg

重启生效:
[hadoop@min1 sysconfig]$ sudo reboot
安装ifconfig:sudo yum install -y net-tools
验证:
[hadoop@min1 ~]$ ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.8.101 netmask 255.255.255.0 broadcast 192.168.8.255
inet6 fe80::20c:29ff:feee:97f8 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4a:2c:5f txqueuelen 1000 (Ethernet)
RX packets 1695 bytes 138124 (134.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1291 bytes 291153 (284.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
如果修改还不成,那就进行下面的操作:
修改命名规则
进入rules.d文件夹:cd /etc/udev/rules.d

编辑70-persistent-net.rules文件(如果没有,就自己创建一个70-persistent-net.rules的文件):sudo vi 70-persistent-net.rules
加上一行内容:
SUBSYSTEM=="net",ACTION=="add",DRIVERS=="?*",ATTR{address}=="00:0c:29:4a:2c:5f",ATTR{type}=="1" ,KERNEL=="eth*",NAME="eth0"
其中:ATTR{address}是虚拟机的MAC地址:可通过ip addr命令查看,如下:

重启网络。
修改hosts文件
修改hosts文件,用于ssh连接的时候能够通过主机名去连接
[hadoop@min1 ~]$ sudo vi /etc/hosts
[sudo] password for hadoop:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
192.168.8.101 min1
192.168.8.102 min2
192.168.8.103 min3
这里的ip和主机名,与虚拟机克隆后要修改的ip和主机名要对应上。在原始虚拟机上先配置好这些,是为了克隆后不需要在每台机器上重复配置。不过为了保险起见,最好克隆之后,把相应的修改项都检查一遍。
安装jdk:
在被克隆虚拟机上安装jdk后,其他机器就不用安装了,免去一些重复操作。安装命令:
[hadoop@min1 software]$ tar -zxvf jdk-8u221-linux-x64.tar.gz -C ~/apps/
配置环境变量:
#jdk
export JAVA_HOME=/home/hadoop/apps/jdk1.8.0_221
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
验证:java -version
[hadoop@min1 software]$ source /etc/profile
[hadoop@min1 software]$ java -version
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
jdk安装成功!
克隆
克隆虚拟机客户端
在克隆前,必须将虚拟机处于关闭状态,挂起状态也不行。如果不是关闭状态,在克隆的时候,它会提示你并要求你将虚拟机关闭。
虚拟机关闭后,鼠标右击虚拟机,选择“管理”->“克隆”,如下图:

点击克隆,
下一步,
下一步,
选择创建完整克隆,下一步,

下一步,
等一会,就克隆成功。
克隆完之后,在:“我的计算机”这里会自动显示你刚刚克隆的虚拟机,如下:
我一次克隆了4台机器,操作和上面一样。
网络配置
修改虚拟机hadoop2的网络配置,详细操作请参照:网络配置
- 修改主机名称:->min2
- 修改/etc/sysconfig/network
- 修改 /etc/sysconfig/network-scripts/ifcfg-eno16777736(修改ip)
- dns服务器:/etc/resolv.conf(这个克隆之后,文件内容没有了)
- 重启网络:sudo service network restart
- 验证:ping www.tmall.com
其他几台虚拟机都是类似的操作
问题-解决办法
克隆之后的虚拟机网卡名称变了,导致网络配置失败。
解决办法:
1. 将克隆之后的虚拟机的每个网卡都改变名称,这样比较繁琐,每台机器都要修改。建议使用方法2
2. 在克隆之前就修改好网卡名称,或者把克隆的副本虚拟机都删掉(删除要在对应的磁盘文件夹中进行,删除之后最好使用360或者其他垃圾清理软件清除一下),在被克隆虚拟机上修改好网卡名称再进行克隆(我之前是先修改好网卡名称再克隆的(装过好几次),所以没有出现这种网卡名称变更的情况。这次克隆出现这个网卡名称变更,我就把克隆的副本都删除了,修改好了网卡名称再重新克隆了)。
3. 通过ip addr命令查看网络信息,可以找到网卡名称,如下: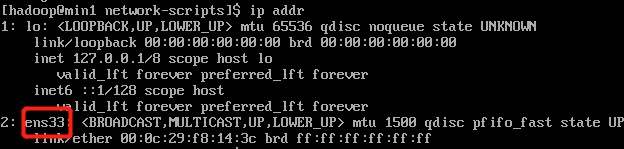
然后修改ifcfg-eno16777736文件中的DEVICE值,把刚刚查看到的网卡名称ens33设置为DEVICE的值,如下:
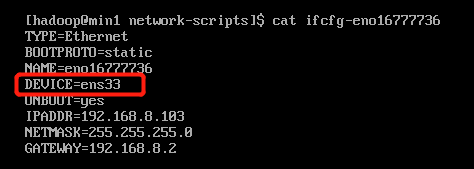
重启网络,ok了。但是这种情况会不会有其他潜在的问题,这个就不得而知,所以建议还是使用方法2来解决。
ssh免密登录
原理:通过加密算法在本地生成一对密钥,自己保留私钥,把公钥放到需要连接的机器上,在使用ssh通信的时候,会带着密钥一起发送到目标机器上,目标机器通过自己拥有的公钥去解解密发送过来的密钥,如果目标机器上存在这个私钥的公钥,那就能解密成功,可以进行通信,如果目标机器没有这个私钥对应的公钥,那就无法解密,连接会失败。
生成一队公私钥,命令:ssh-keygen -t rsa
注意:这里使用的是rsa加密算法。每执行一次这个命令会生成一对新的公私钥,每次都要将新生成的公钥放到目标机器上,否则无法解密成功。
输入ssh-keygen -t rsa命令后,只要按enter键进行下一步:(默认在 ~/.ssh目录生成两个文件:)
[hadoop@min1 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
ec:8e:92:64:4a:04:1b:a9:1f:e2:ef:b0:2e:22:09:f2 hadoop@min1
The key's randomart image is:
+--[ RSA 2048]----+
| . |
|+ |
|.+ |
|+ o . |
|.+ . S |
|o.o o . |
|o=.+ . . |
|= E.o o |
|=o.. .. . |
+-----------------+
[hadoop@min1 ~]$ cd .ssh/
[hadoop@min1 .ssh]$ ll
总用量 8
-rw-------. 1 hadoop hadoop 1675 9月 28 16:23 id_rsa
-rw-r--r--. 1 hadoop hadoop 393 9月 28 16:23 id_rsa.pub
拷贝一份公钥:cp
[hadoop@min1 .ssh]$ cp id_rsa.pub id_rsa_min1.pub
注意:在不对公钥授权的时候,自己连接自己,也是需要输入密码才能连接的。如下,在没有给公钥授权的时候执行:
[hadoop@min1 .ssh]$ ssh min1
The authenticity of host 'min1 (192.168.109.100)' can't be established.
ECDSA key fingerprint is 0c:e8:db:3a:86:47:28:3c:6d:62:b6:55:99:c0:0f:38.
Are you sure you want to continue connecting (yes/no)? yes #这个要输入这个yes是因为是该机器第一次连接主机。每台机器第一次连接的时候都会有这个出现。
Warning: Permanently added 'min1,192.168.109.100' (ECDSA) to the list of known hosts.
hadoop@min1's password: #这行就是要求输入密码,因为没有对公钥授权。授权之后就不会出现了
Last login: Sat Sep 28 16:20:22 2019
授权:cat ~/.ssh/id_rsa_min1.pub >> ~/.ssh/authorized_keys
注意:
- 这里你用id_rsa.pub或者id_rsa_min1.pub都可以,因为本来就是同一个公钥。
- 本来.ssh/文件夹下是没有authorized_keys文件的,这个文件是我们自己创的,至于能不能使用其他的名字,没有试过,你有兴趣可以自己试一试。不过我怀疑这是ssh的某种规范要求使用这个名字吧。
修改.ssh/和authorized_keys权限:700和600。我第一次安装的时候就是没有修改权限,连了好久都要输入密码,一直以为是我安装的时候哪里出问题了,反复弄了好几次,后来发现必须将.ssh/和authorized_keys权限设置成700和600才行。
[hadoop@min1 ~]$ sudo chmod 700 .ssh
[hadoop@min1 ~]$ sudo chmod 600 .ssh/authorized_keys
再连接min1:
[hadoop@min1 ~]$ ssh min1
Last login: Sat Sep 28 16:41:42 2019 from min1
本地连接成功!
将min2~min5依次重复上述的操作。
以min1和min2位例,将min1的公钥拷贝到min2并授权,命令如下:
[hadoop@min1 ~]$ scp .ssh/id_rsa_min1.pub min2:~/.ssh/
[hadoop@min1 .ssh]$ cat id_rsa_min1.pub >> authorized_keys
在min1机器上测试:
[hadoop@min1 ~]$ ssh min2
Last login: Sat Sep 28 09:32:41 2019 from min5
[hadoop@min2 ~]$ #主机名称变成min2了,连接成功!
同样地,将min2的公钥拷贝到min1上,然后在min1上授权,这样,min2就能免密登录min1了。
其他的机器,像min1和min2这样操作,就能实现互连了。