今天在使用python爬虫时遇到一个奇怪的问题,使用的是自带的urllib库,在解析网页时获取到的为b'\x1f\x8b\x08\x00\x00\x00\x00...等十六进制数字,尝试使用chardet来检查编码格式时发现encoding为None,因为以前一直用的是requests库,所以没有仔细注意过这个问题,经过详细搜索后分析如下(下面代码是修改后加入gzip的):
转载注明http://www.cnblogs.com/RainLa/p/8057367.html

一.HTTP 内容协商
有时候,同一个 URL 可以提供多份不同的文档,这就要求服务端和客户端之间有一个选择最合适版本的机制,这就是内容协商
HTTP 的内容协商的其中一种方式:服务端根据客户端发送的请求头中某些字段自动发送最合适的版本。可以用于这个机制的请求头字段又分两种:内容协商专用字段(Accept 字段)、其他字段
字段情况,详见下表:
| 请求头字段 | 说明 | 响应头字段 |
|---|---|---|
| Accept | 告知服务器发送何种媒体类型 | Content-Type |
| Accept-Language | 告知服务器发送何种语言 | Content-Language |
| Accept-Charset | 告知服务器发送何种字符集 | Content-Type |
| Accept-Encoding | 告知服务器采用何种压缩方式 | Content-Encoding |
例如客户端发送以下请求头:
Accept-Encoding:gzip,deflate,br表示支持采用 gzip、deflate 或 br 压缩过的资源
浏览器的响应头可能是这样的:
Content-Encoding: gzip二.服务器返回response-header中Content-Encoding:gzip
可以发现是服务器使用了压缩算法,而且压缩算法为gzip,而且gzip压缩算法的特点是以1f8b开头,具体字节顺序分析为(下面解释摘抄自http://blog.csdn.net/jison_r_wang/article/details/52068962,本人实际测试过,都对应的上,不过原作者解释的很好,所以直接摘抄过来)

0000 0000h, 0~1,开始的两个字节是标识符1F8B;
0000 0000h, 2,CM (Compression Method),压缩方式,08表示deflate算法;
0000 0000h, 3,FLG (FLaGs),标志位,十六进制08,即二进制0000 1000,从右往左分别是bit0~bit7,现在bit3置位,对应FNAME,即该gzip头后面的扩展部分是带着原始文件名的;
0000 0000h,4~7,这四个字节是时间,分别是十六进制“38 DA 71 57”,这是存储的顺序,我们转换成人们正常读取的顺序“57 71 DA 38”,将其转换成时间,先把5771DA38转换成十进制即1467079224,转换为时间为2016/6/28 10:0:24
0000 0000h, 8,XFL (eXtra FLags),十六进制02,这个地方我也有点糊涂,但我估计应该是用的XFL = 4 - compressorused fastest algorithm;
0000 0000h, 9,00,即0 - FAT filesystem (MS-DOS, OS/2,NT/Win32),我用的是win7,也是对应的。
0000 0000h, a~00000010h, 1,共8个字节,存储的是原始文件的文件名“abc.txt”,末尾还有个'\0'表示结束,从这里可以看出,这个文件名只是个文件名,没携带路径信息。从这里往后,就是实际的压缩数据信息了;
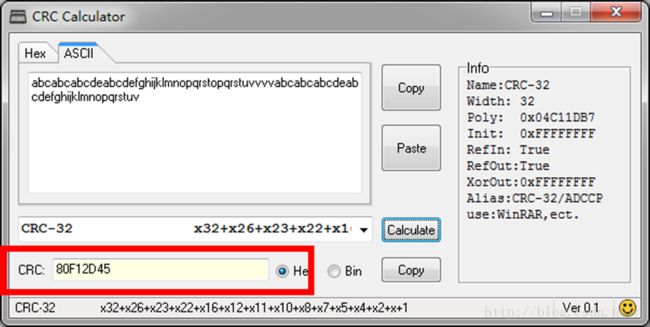
0000 0030h, b~e,这四个字节是CRC32校验码,分别是十六进制“45 2D F1 80”,这是存储的顺序,我们转换成人们正常读取的顺序“80 F1 2D 45”,原文件内容为“abcabcabcdeabcdefghijklmnopqrstopqrstuvvvvabcabcabcdeabcdefghijklmnopqrstuv”,使用CRC计算器算得结果如下图所示
0000 0030h, f~0000 0040h, 2,这四个字节是原始文件的大小,分别是十六进制“4B 00 00 00”,这是存储的顺序,我们转换成人们正常读取的顺序“00 00 00 4B”,即十进制的75,原始文件大小75字节,这也与文件信息对应。
三.在观察request-header中Accept-Encoding:gzip, deflate, sdch, br发现了四种不同的压缩算法,现总结如下:
1.gzip是一种数据格式,默认且目前仅使用deflate算法压缩data部分;deflate是一种压缩算法,是huffman编码的一种加强。在nginx中gzip默认的使用deflate压缩,apache中因为历史原因分为mod_deflate 和mod_gzip 两个模块,不管使用mod_gzip 还是mod_deflate,此处返回的信息都一样。因为它们都是实现的gzip压缩方式。Apache 1.x系列没有内建网页压缩技术,所以才去用额外的第三方mod_gzip 模块来执行压缩。而Apache 2.x官方在开发的时候,就把网页压缩考虑进去,内建了mod_deflate 这个模块,用以取代mod_gzip。虽然两者都是使用的Gzip压缩算法,它们的运作原理是类似的。其他区别见http://www.webkaka.com/tutorial/server/2015/021013/
2.sdch是Shared Dictionary Compression over HTTP的缩写,即通过字典压缩算法对各个页面中相同的内容进行压缩,减少相同的内容的传输。如:一个网站中一般都是共同的头部和尾部,甚至一些侧边栏也是共同的。之前的方式每个页面打开的时候这些共同的信息都要重新加载,但使用SDCH压缩方式的话,那些共同的内容只用传输一次就可以了。sdch主要分为3个部分:首次请求,下载字典,之后的请求。
3.br就是 Brotli(摘抄自https://segmentfault.com/a/1190000009383543)
Brotli is a generic-purpose lossless compression algorithm that compresses data using a combination of a modern variant of the LZ77 algorithm, Huffman coding and 2nd order context modeling, with a compression ratio comparable to the best currently available general-purpose compression methods. It is similar in speed with deflate but offers more dense compression.
Brotli 是基于LZ77算法的一个现代变体、霍夫曼编码和二阶上下文建模。Google软件工程师在2015年9月发布了包含通用无损数据压缩的Brotli增强版本,特别侧重于HTTP压缩。其中的编码器被部分改写以提高压缩比,编码器和解码器都提高了速度,流式API已被改进,增加更多压缩质量级别。
与常见的通用压缩算法不同,Brotli使用一个预定义的120千字节字典。该字典包含超过13000个常用单词、短语和其他子字符串,这些来自一个文本和HTML文档的大型语料库。预定义的算法可以提升较小文件的压缩密度。
使用Brotli替换Deflate来对文本文件压缩通常可以增加20%的压缩密度,而压缩与解压缩速度则大致不变。
四.nginx使用br
安装与配置过程
安装需要用到开发工具
CentOS,如下
yum groupinstall 'Development Tools'Ubuntu,如下
sudo apt-get install autoconf libtool automake这次的教程实践环境是CentOS 7,已经在linpx.com上实现了
下面开始正式的教程
安装libbrotli
cd /usr/local/src/
git clone https://github.com/bagder/libbrotli
cd libbrotli
./autogen.sh ./configure make && make install安装ngx_brotli
cd /usr/local/src/
git clone https://github.com/google/ngx_brotli
cd ngx_brotli && git submodule update --init下载Nginx
这里使用 nginx-1.10.3
cd /usr/local/src
wget http://nginx.org/download/nginx-1.10.3.tar.gz
tar -xvzf nginx-1.10.3.tar.gz && rm -rf nginx-1.10.3.tar.gz获取Nginx Arguments
nginx -V整理新的Arguments
根据获取到的configure arguments和上面软件的位置,重新整理configure arguments
然后再加上 --add-module=/usr/local/src/ngx_brotli
开始安装和编译
cd /usr/local/src/nginx-1.10.3
./configure [这里是你的原Arguments] --add-module=/usr/local/src/ngx_brotli make && make install检查是否安装正常
nginx -V
nginx -t找到Nginx的全局配置文件
如果检测安装正常的话,可以开始配置,该配置文件一般为 nginx.conf
在合适的位置插入下面代码
#Brotli Compression
brotli on;
brotli_comp_level 6;
brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml;再次检测是否正常
nginx -t重启Nginx
如果正常的话,恭喜你,你已经配置完成了,重启一下Nginx即可
CentOS 6.x:
service nginx restartCentOS 7.x:
systemctl restart nginx检查是否生效
打开你的网页,用chrome开发者工具调试,在Network那,发现有content-encoding:br
可能的报错
如果在测试或者重载时, Nginx 报错如下:
nginx: error while loading shared libraries: libbrotlienc.so.1: cannot open shared object file: No such fileor directory解决方法是把对应的库文件在 /lib(64) 或者 /usr/lib(64) 中做上软链接:
$ ln -s /usr/local/lib/libbrotlienc.so.1 /lib64 # 32 位系统 $ ln -s /usr/local/lib/libbrotlienc.so.1 /lib
解决:
需要重新对nginx编译安装:
|
1
|
[root@localhost ~]
# tar zxvf nginx-1.8.1.tar.gz
|
进入nginx目录,修改src/http/ngx_http_header_filter_module.c:
|
1
|
[root@localhost nginx
-
1.8
.
1
]
# vim src/http/ngx_http_header_filter_module.c
|
修改:
|
1
2
3
4
5
6
7
|
内容:
static char ngx_http_server_string[]
=
"Server: nginx"
CRLF;
static char ngx_http_server_full_string[]
=
"Server: "
NGINX_VER CRLF;
更改为:
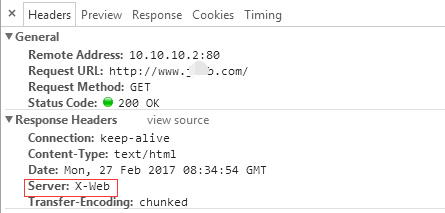
static char ngx_http_server_string[]
=
"Server: X-Web"
CRLF;
static char ngx_http_server_full_string[]
=
"Server:X-Web "
CRLF;
|
编译安装:
|
1
2
|
[root@localhost nginx
-
1.8
.
1
]
# ./configure --prefix=/data/nginx --with-http_stub_status_module
[root@localhost nginx
-
1.8
.
1
]
# make && make install
|
重启nginx:
|
1
|
[root@localhost sbin]
# service nginx restart
|
验证: