CVPR 2020 三篇有趣的论文解读

©PaperWeekly 原创 · 作者|文永亮
学校|哈尔滨工业大学(深圳)硕士生
研究方向|视频预测、时空序列预测

在深度学习中我们真的需要乘法?

论文标题:AdderNet: Do We Really Need Multiplications in Deep Learning?
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/1912.13200
代码链接:https://github.com/huawei-noah/AdderNet

这篇论文是北大、诺亚、鹏城、悉大的论文,观点比较有趣,在喜提 CVPR 2020 之前也比较火了,下面我可以介绍一下。
论文指出我们可以定义如下公式,首先我们定义核大小为 d,输入通道为 ,输出通道为 的滤波器 ,长宽为 H, W 的输入特征为 。

其中 为相似度计算方法,如果设 ,这就是卷积的一种定义方法了。那么论文就引出加法网络的基本算子如何定义的:
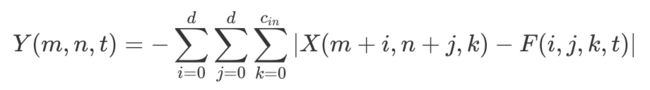
如上定义只用了加法的 距离,可以有效地计算滤波器和特征之间的相似度。
在 CIFAR-10 和 CIFAR-100 以及 ImageNet 的实验结果:


可以看到在把卷积替换成加法之后好像也没有太多精度的丢失,正如标题说的,我们真的需要这么多乘法吗?

Deep Snake:用于实例分割

论文标题:Deep Snake for Real-Time Instance Segmentation
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2001.01629
代码链接:https://github.com/zju3dv/snake

这篇工作是来自浙江大学 Deepwise AI Lab 的,我起初看到感觉十分有趣,这篇论文的实例分割并不是每个像素的去分,而是用轮廓围住了实例。代码已经开源,有兴趣的同学可以去看看。

基本思想是给实例一个初始轮廓,用循环卷积(Circular Convolution)方法学习更新轮廓,最后得到 offsets。
我在下面介绍一下 Circular Convolution:


我们定义特征为蓝色部分的圆圈,那么它可以表达为 ,*是标准的卷积操作,整个循环卷积就是每一个蓝色的特征与黄色的 kernel 相乘得到对应高亮的绿色输出,一圈下来就得到完整的输出,kernel 也是共享的。

我们可以通过图 (b) 看到整个算法的 pipeline,首先输入图片,实验中使用了 CenterNet 作为目标检测器,Center Net 将检测任务重新定义为关键点检测问题,这样得到一个初始的 box。
然后取每边的中点连接作为初始的 Diamond contour(实际实验中作者说他 upsample 成了 40 个点),再通过变形操作使点回归到实例的边界点,然后通过边界点一半向外拓展 1/4 的边长得到一个Octagon contour(八边形轮廓),再做变形操作最终回归到目标的形状边界。
作者在三个数据集上做了实验,分别是 Cityscapes,Kins,Sbd。可以看到在 Kins 上的数据集的 AP 值比 Mask RCNN 好一些。

其分割的效果也不错且有点有趣:

可以看到确实挺快的,Sbd 数据集的 512 × 512 的图片,在 Intel i7 3.7GHz,GTX 1080 Ti GPU 达到 32.3 fps。


BIN:模糊视频插帧

论文标题:Blurry Video Frame Interpolation
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2002.12259
代码链接:https://github.com/laomao0/BIN

这篇 paper 是上海交通大学的翟广涛教授组的模糊视频插帧技术,主要是为了提高视频质量并且达到插帧的效果,我觉得这篇论文十分优秀,只可惜代码还在重构中,repo 说 6.14 公布,这也有点久啊。
这篇论文设计的很精巧,模型构建中分为两块:
金字塔模块
金字塔间的递归模块
如下图所示:

其实这网络结构很容易理解, 都是输入,当我们取 Scale 2 的时候,输入取 ,我们可通过 得到中间插帧 ,同理可得 ,最后通过 和 插帧得到 。
数学表达如下:
但是 Scale 3 和 4 的时候就不一样了,我举例 Scale 3 的时候,Scale 4 同理:
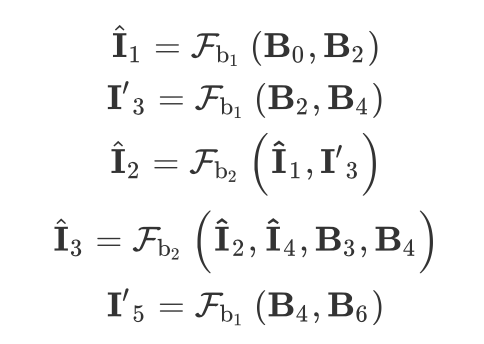
这样通过 就会得到中间 1,3,5 的插帧,或许有人疑惑为什么会有 和 ,这两个有什么区别,这里主要就是因为作者做了一个 Cycle Consistency 的 loss,主要是保证中间产生的帧与金字塔最后产生的帧保持空间上的一致性。

▲ 金字塔模块的构建有(a)Backbone (b)Residual Dense Block 两种
其中金字塔模块具有可调节的空间感受域和时间范围,可以从图中看到,作者采用了三种 scale,随着 scale 的增加,网络将会拓展的更深,因此具有更大的空间感受域,同时在时间范围内输入的数量会需要更多,所以说时间范围也正是如此,从而控制计算复杂度和复原能力。
金字塔模块使用普通的卷积神经网络搭建而成,其中同一级的共享权重,这其实节省了很多参数空间,但是这样是否就缺乏了时间上的信息呢?
如果采用 Scale 2 的时候,我们可以分析金字塔之间如何传递信息的,如图中 (b) 部分:

ConvLSTM 构成的 Inter-Pyramid Recurrent Module 实际上就是为了传递时空上的信息,这里 Time Step 为 2, 与 实际上是同一张输入,但是进入了两个不同的模块,整体 step 前进了一步,其中的 ConvLSTM 就是为了传递 C 和 H 的,其公式如下:
损失函数非常的简单,这里不做过多的说明,分为了重构误差 (Pixel Reconstruction) 和一致性误差 (Cycle Consistency) :
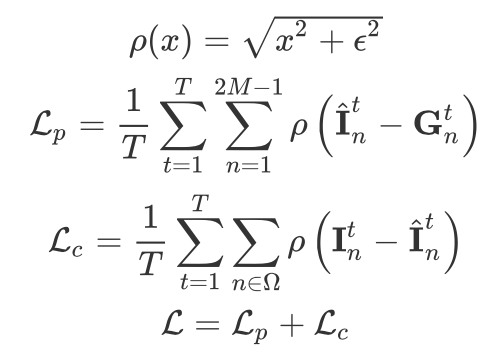
数据集用的是:Adobe240 和 YouTube240,可以看到论文的效果取了 Scale=4 的时候跟 GT 已经看不出太大的区别了。

而且 Scale 越大图片质量就越好:


点击以下标题查看更多往期内容:
图自编码器的起源和应用
图神经网络三剑客:GCN、GAT与GraphSAGE
如何快速理解马尔科夫链蒙特卡洛法?
深度学习预训练模型可解释性概览
ICLR 2020 | 隐空间的图神经网络
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
