从近年CVPR看域自适应立体匹配

©PaperWeekly 原创 · 作者|张承灏
单位|中科院自动化所硕士生
研究方向|深度估计
深度立体匹配(deep stereo matching)算法能够取得较好的性能,一是来源于卷积神经网络强大的特征提取能力,二是得益于大规模双目仿真数据集。
例如:Sceneflow [1] 是一个包含三万多对双目图像的带标签的合成数据集,Carla [2] 是一个开放的城市驾驶模拟器,可以用来生成大规模城市双目仿真数据。这些合成数据集使得深度模型能够得到充分地训练。
然而,由于合成数据和真实数据存在很大的领域偏差(domain gap),在合成数据上预训练的模型在真实数据上泛化性能较差。
另一方面,真实场景下的数据往往难以获得密集且准确的标注信息。比如 LiDAR 等设备价格高昂,体型笨重,而且只能收集稀疏的深度信息;基于结构光的设备在室外场景难以捕捉准确的深度信息。
近年来,更多的研究关注域自适应立体匹配(domain adaptation stereo matching)。希望在不获取,或者少获取真实场景标注信息的情况下,实现深度模型从仿真场景到真实场景的自适应。
本文主要梳理了近两年 CVPR 上关于域自适应立体匹配的研究工作。

ZOLE

论文标题:Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
论文来源:CVPR 2018
论文链接:https://arxiv.org/abs/1803.06641
代码链接:https://github.com/Artifineuro/zole
1.1 Motivation
这篇论文希望通过无监督域自适应,将合成数据上训练的模型泛化到新的真实场景中,比如手机拍摄的生活环境,或者自动驾驶的城市街景。作者观察到两个现象:
泛化故障:合成图像上预训练的模型在真实图像上性能不好,原因在于视差图的边缘很模糊,并且在病态区域的视差估计是错误的;
尺度多样化:如果将一对双目图像上采样一定比例,再输入到预训练的模型中,那么预测出来的视差具有更丰富的细节信息,例如更锐化的目标边缘,更高频的场景信息。
第一点观察是存在的问题,作者借鉴图论的知识,对视差图做图拉普拉斯正则化约束,采用迭代优化的策略在真实场景上进行自适应。而第二点是优势,这种精细化的视差图可以作为原尺度输入图像的视差标签,从而实现自监督学习。
这实际上一种放大学习(zoom and learn),因此本文的方法被称为 ZOLE。
1.2 Method
给定一个由深度网络预测的视差图 D,图拉普拉斯正则化定义为:令视差图上的图像块(patch)为 ,s 相对于一个具有m个顶点的图 G 是光滑的,设 为图 G 的拉普拉斯矩阵,那么图拉普帕斯正则化就是 的值。
这个得到的值经过求和,成为图拉普拉斯正则化损失函数来训练深度模型。
那么如何从视差图上构造出这个图 G 呢?作者将视差图划分为 M 个正方形小块,并将其切片,这样每个小块 s 对应一个长度为m的向量。连接像素 和像素 的边权重 定义为:
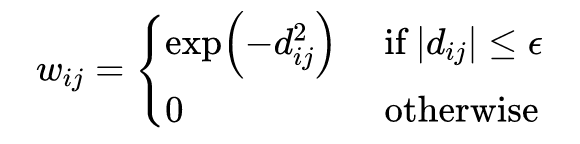
其中 是一个阈值, 是像素 和像素 的距离度量。因此,构造的图 G 是一个 - 邻接图。距离度量函数定义如下:
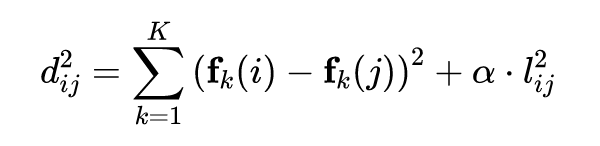
其中 和 分别是 的第 项和第 项, 实际上是所有图像块的集合 。距离度量的前一项是 K 维空间的距离,而后一项是像素空间的距离, 取 0.2。
假设共有 N 对双目图像,即 , 。前 对是真实图像,后面 是合成图像。那么对于深度立体匹配模型 ,令 是视差标签 ,其迭代优化的目标为:
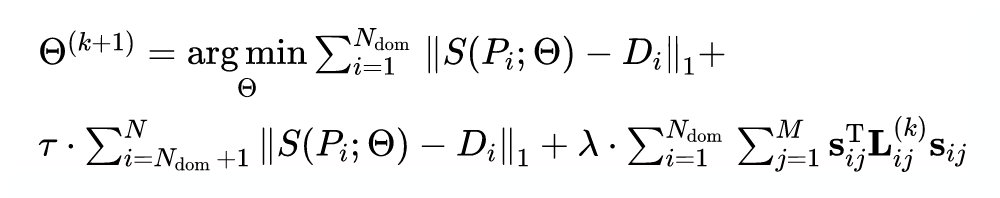
目标函数的前两项可看作数据项,第三项是图拉普拉斯正则化损失,可看作平滑项。其中第一项对应真实数据, 是原始图像上采样后经过模型预测,再缩放回原尺度的伪标签;第二项对应合成数据, 是合成数据的视差标签。
作者认为在真实场景下能够估计视差的模型,应该在仿真场景下仍然具有视差估计的能力,因此合成数据和真实数据是混合训练的, 和 是各个损失函数的权重。
自适应迭代优化的算法如下,是对上述目标函数的具体化阐述。

1.3 Experiments
作者首先在智能手机拍摄的日常生活场景下进行实验。由下图可以看出,ZOLE 模型在真实场景下的视差图更加平滑,但是能够保持锐化的边缘细节。

作者也在自动驾驶的城市街景场景下进行了实验,即 KITTI 数据集。由下图可以看出,ZOLE 模型同样可以产生准确且精细化的视差图,这得益于图拉普拉斯正则化的约束。


L2A

论文标题:Learning to Adapt for Stereo
论文来源:CVPR 2019
论文链接:https://arxiv.org/abs/1904.02957
代码链接:https://github.com/CVLAB-Unibo/Learning2AdaptForStereo
2.1 Motivation
无监督域自适应算法的一种简单实现是先在合成数据上采用有监督的预训练,这可以看作是一种更好的参数初始化,之后在真实数据上采用无监督损失函数进行微调。这种自适应方法简单粗暴,微调时容易崩溃,并且准确率不高。
这篇论文从元学习的方法出发,将自适应的过程纳入到学习的目标中,由此可以得到一组更适合自适应学习的参数。
模型不可知元学习(Model Agnostic Meta Learning,MAML)[3] 是few-shot learning中一种常用的元学习算法。给定一个训练集 ,令和任务相关的训练集和验证集分别是 和 ,其中 。
假设内循环只有一次梯度下降,则整个 MAML 的目标可以写为:

其中 是自适应的学习率。这个目标函数表明,在每次迭代优化中,内循环从公共基本模型 开始对每个任务执行梯度下降更新(适应步骤)。
之后,外循环对公共基本模型执行一次梯度更新,更新的梯度是内循环中特定任务的梯度的总和。作者将 MAML 的自适应思想应用到立体匹配中。
2.2 Method

上图是论文的训练框架图,作者采用合成图像的视频帧进行在线自适应学习,因此这里可以使用有监督损失 进行评估。在真实场景中适应时,只有无监督损失 可以用。
因此,这是一个将自适应过程加入到学习环节的学习自适应(learn-to-adapt,L2A)方法。
具体来说,对于每一个 batch,含有 个视频序列。由于视频序列较长,并且有很多冗余部分,因此仅随机采样 帧视频。
图中蓝色箭头代表的是模拟自适应阶段,对应 MAML 中的内循环。对于第一个采样帧 ,先使用无监督损失函数 对当前视频序列的模型进行梯度更新,这是模拟在真实场景下的无监督学习。
之后每次不仅采用无监督损失更新,还采用有监督损失 评估当前模型的准确率。当采样的视频帧通过之后,将每个视频序列的有监督评估损失求和,作为整个立体匹配模型的梯度进行更新。这对应图中的橙色箭头,即 MAML 中的外循环梯度更新。
为了更清晰地理解自适应的过程,可以看下面的算法流程:

算法的核心是第 9 步采用无监督损失对当前任务的模型 进行梯度更新,模拟真实场景下的自适应;第 10 步采用有监督损失进行评估,并进行梯度累加;第 11 步采用累加的梯度对整体模型 进行梯度更新。
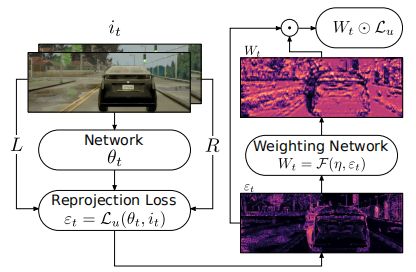
除此之外,为了减少无监督损失中错误的视差估计对训练的影响,作者还设计了一个置信度函数,用来作为无监督损失函数中每个像素点贡献的权重。由于这种置信度是没有显式的监督信息的,因此直接让置信度网络自动地估计噪声点所在的位置。
这种置信度可看作是无监督损失的加权,具体的结构如下图所示:
2.3 Experiments
作者主要比较了有监督训练和无监督域自适应,以及是否采用置信度函数的性能。
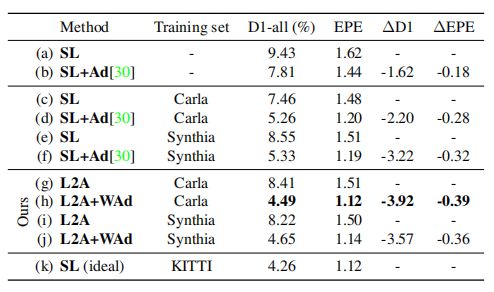
从上图可以看出,比较直接的域自适应是先监督预训练,再无监督 finetune,即 SL+Ad;而采用 L2A+WAd(即 L2A 自适应+置信度函数)的性能要优于这种简单的自适应方法,并且几乎和理想的有监督 finetune 性能相匹配。

MADNet

论文标题:Real-time self-adaptive deep stereo
论文来源:CVPR 2019 Oral
论文地址:https://arxiv.org/abs/1810.05424
代码链接:https://github.com/CVLAB-Unibo/Real-time-self-adaptive-deep-stereo
3.1 Motivation
ZOLE 和 L2A 这两种方法都是从自适应的准确率上来考虑的,并没有关注模型的速度。然而,在实际的自动驾驶场景中,我们需要的是实时的深度估计模型。
因此作者在这篇论文中提出了第一个实时域自适应立体匹配网络 MADNet(Modularly ADaptive Network)。
前面介绍过,一种简单的完全自适应(full adaptation)方法是采用无监督损失进行 finetune,但是这种训练方法在每次反向传播时需要贯穿整个网络。
尽管将网络设计的更轻便简单可以提升一些速度,但是反向传播仍然需要较大的计算量,这样使得达到实时的速度变得很困难。
作者认为自适应的时候可以只针对某些特定的模块进行反向传播,而不需要对整个网络进行一遍,这样既可以保证网络具有一定的体量来满足准确性的要求,又能在自适应的阶段进行在线学习,提升速度。
网络自始至终都是处于训练的状态,只要真实场景的视频足够长,那么网络就能适应的越来越好。
3.1 Method
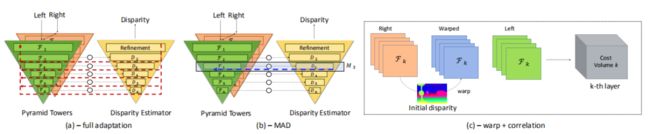
上图是 MADNet 的整体结构。作者设计了一个轻量级的 encoder-decoder 结构,编码和解码部分都是一个金字塔结构。
编码部分的 F1 到 F6 分别是 1/2 到 1/64 的分辨率,解码部分的 D2 到 D6 是对应于 F2 到 F6 分辨率的视差估计模块,每个 D 模块都输出该分辨率大小的预测视差图。编码和解码中间的圆圈代表经过 warp 操作构造 cost volume(如上图 c)。
上图中(a)表示的是完全自适应的方法,采用无监督损失,对整个网络进行反向传播,这种方法计算量比较大。
图中(b)是作者提出的调制自适应算法(Modular ADaptation,MAD),将相同分辨率的编码和解码模块看做是一个合并的调制模块 M。比如 F3 和 D3 组成 M3 调制模块,在每次计算完损失之后,只选择一个模块进行反向传播,这样就可以大大提升在线自适应的速度。
那么在计算完损失之后,如何选择需要进行反向传播的模块呢?是按顺序选择还是随机选择?作者提出了一个启发式的奖励-惩罚机制来动态地选择每次更新的模块。下面是该算法的流程:

算法中 H 是一个包含了 p 个 bins 的直方图,每一个 bin 对应于一个调制模块 M。第 7 行,每次从直方图 H 的 softmax 分布中采样概率最高的模块 M,在第 9 行进行梯度更新。接下来是一种启发式的奖励-惩罚机制,用来调整直方图中每个 bin 的大小。
第 13 行的 是一种带有噪声的损失。第 14 行的 可以看做是用来衡量模块有效性的度量。如果某个模块有效,那么当前的 就会比较低,使得 ,那么在第 16 行更新直方图时概率就会增大。反之,模块效率比较低, 就会大,使得 ,在更新时就是负权重。
3.2 Experiments
作者采用的 KITTI raw 数据集,它包含 Campus,City,Residential,Road 四种类型的视频帧。
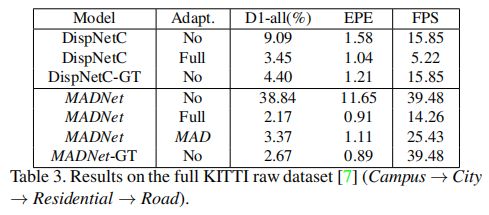
上表是 MADNet 在四种类型的数据集上先后自适应的实验结果,可以看到如果不加自适应,可以达到接近 40FPS 的速度。
如果采用无监督完全自适应,可以达到 15FPS;而采用了 MAD 调制模块后,速度可以提升到 25FPS,精度降低也不多,这是因为当适应到足够多的视频帧时,MAD 可以具有与完全自适应同等的性能。
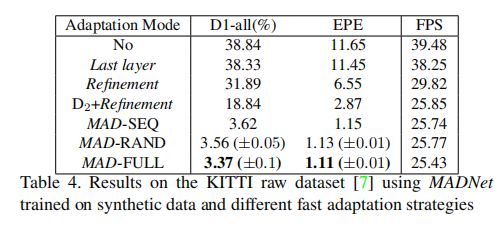
上表比较了不同自适应方法的性能和速度。可以看到,不采用自适应时速度最快,但是精度最低。只调整最后一层,Refinement 层或者 D2+Refinement,速度会有所降低,EPE 大幅降低,但是 D1-all 还是比较高。
相比于按顺序的选择调制模块(SEQ)或者随机选择调制模块(RAND),采用启发式的惩罚-奖励机制达到的性能最高。

Guided Stereo Matching

论文标题:Guided Stereo Matching
论文来源:CVPR 2019
论文链接:https://arxiv.org/abs/1905.10107
代码链接:https://github.com/mattpoggi/guided-stereo
4.1 Motivation
和上面介绍的三种方法不同的是,这篇论文探讨的是一种弱监督的引导域自适应立体匹配。尽管现有设备很难获取密集而准确的深度信息,但是只获取十分稀疏的深度信息是比较容易办到的。
如何只根据这些稀疏的标签就能完成从合成数据到真实数据的自适应呢?作者在这篇论文中假设只采用 5% 真实数据标签,提出一种引导匹配的域自适应机制。
4.2 Method
在深度立体匹配网络中,用来计算匹配代价的是 cost volume,根据计算方式不同有两种形式,一是基于相关性的,其 cost volume 的大小是 H×W×(2D+1);另一种是基于 3D 卷积的,其 cost volume 的大小是 H×W×D×2F。
这里 H 和 W 是图像的高和宽,D 是特征通道数,F 是考虑的最大视差值。
作者希望通过真实数据的稀疏标签来增强其第 k 个通道的输出。具体来说,引入了两个大小均是 H×W 的输入:系数矩阵 G 和二进制掩码 V,V中每个量表示 G 中元素是否有效。
对于坐标是 (i, j) 的像素,如果 ,那么就根据真实视差 来改变其特征。之后再利用深度神经网络自身的能力来应用这些真实的稀疏标签。
之前的一些方法是采用置信图来改变 cost volume,比如当预测的视差 ,就将其置为 0。但是考虑到真实图像的标签是十分稀疏的(5%)。
因此这样做就会使得特征图变成一个大部分是零的特征图,只有零星的非零值,这是不利于深度网络学习的。因此,一种替代的方式是采用以 为中心的高斯分布,其表达式如下:
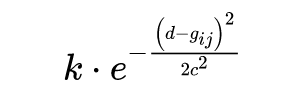
其中 c 代表高斯分布的宽度,k 代表峰值的最大值,应当大于等于 1。因此,根据有效性 V,可以将高斯分布与整个 cost volume 相乘来得到新的特征 :
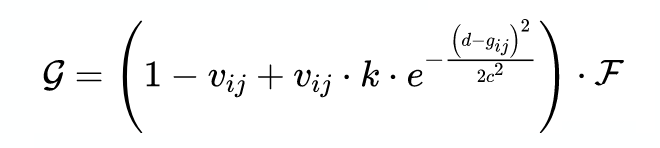
以上就是引导立体匹配的核心公式。
4.3 Experiments
作者分别采用两种不同代表的深度立体匹配网络来进行实验,iResNet [4] 和 PSMNet [5],并且在三种公开数据集(KITTI,Middlebury,ETH3D)上取得了更加优越的性能。甚至对于传统的 SGM 算法也有效。
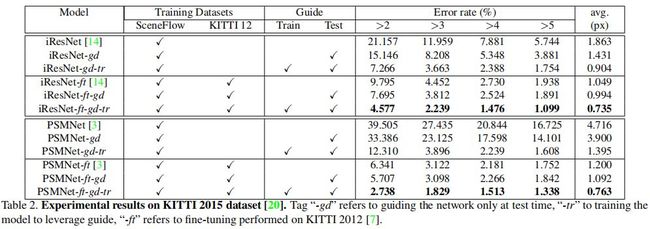
上图是在 KITTI 2015 数据集上的性能比较。可以看到,无论 iResNet 还是 PSMNet,只在合成数据上预训练再在真实数据上测试都会有很大的性能丢失。而加入稀疏标签的引导后,仅仅测试就能降低错误率。
如果在训练时也加入引导,则更能进一步降低错误率。在其他几个数据集上的结果也有类似的结论,大家可以下载论文看更详细的结果。

总结
从近两年 CVPR 的域自适应立体匹配的发展来看,有以下几个特点:
研究关注点从离线自适应转向在线自适应,后者更加贴近实际应用场景;
从努力提升算法精度,到开始关注模型效率,推理速度,迈向实时的域自适应算法;
在合成数据和真实数据不变的情况下,探索更有效的训练算法是实现域自适应的突破口,可以从其他领域的进展来借鉴;
仅有稀疏的真实标签就能够大幅提升域自适应的性能。
参考文献
[1] Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: CVPR 2016.
[2] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. arXiv preprint arXiv:1711.03938, 2017.
[3] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model agnostic meta-learning for fast adaptation of deep networks. In PMLR 2017.
[4] Zhengfa Liang, Yiliu Feng, Yulan Guo, Hengzhu Liu, Wei Chen, Linbo Qiao, Li Zhou, and Jianfeng Zhang. Learning for disparity estimation through feature constancy. In CVPR 2017.
[5] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In CVPR 2018.

点击以下标题查看更多往期内容:
联合检测和跟踪的多目标跟踪算法解析
CVPR 2020 | 旷视研究院提出双边分支网络BBN
浅谈多目标跟踪中的相机运动
双目深度估计中的自监督学习概览
CVPR 2020 三篇有趣的论文解读
ICLR 2020 | GAN是否真的判断出了数据的真假?
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
