01. ARM体系结构概述
1. 嵌入式系统的组成
1)硬件组成
A. 嵌入式微处理器
目前流行的体系结构:ARM、MIPS、PowerPC、MC68000等
B. 外围设备
主要用于完成存储、通信、调试、显示等功能,常见如下:
存储设备:如RAM、SRAM、Flash等
通信设备:如RS232接口、SPI接口、以太网接口等
显示设备:如显示屏等
2)软件组成
两种软件组成的区别在于是否包含嵌入式操作系统
补充:嵌入式系统软硬件构成图
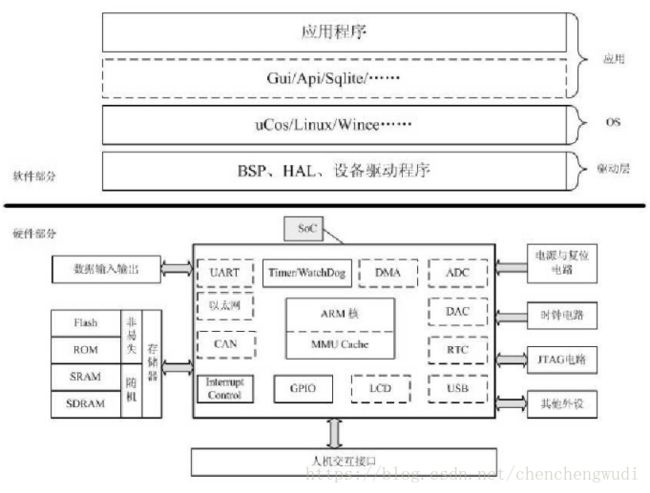
2. 交叉编译和交叉调试
1)交叉编译

交叉编译就是在一个平台上生成可以在另一个平台上执行的代码。需要注意的是,编译器本身也是程序,也要在与之对应的某一个CPU上运行。
目前的使用就是在X86体系的平台上编译出在ARM平台上运行的代码。
2)交叉调试
A. 通用调试与交叉调试
通用软件调试:
调试器和被调试的程序运行在同一台计算机上
,调试器是一个单独运行的进程,他通过操作系统提供的调试接口来控制被调试的进程。
交叉调试:
①
调试器和被调试进程运行在不同机器上
,调试器运行在PC(宿主机)上,被调试进程运行在开发板(目标机)上
② 调试器通过某种
通信方式
(串口、网络、JTAG等)控制被调试进程
③ 在
目标机
上一般会具备某种形式的
调试代理
,他负责与调试器共同配合完成对目标机上运行的进程的调试。这种调试代理可以是某些支持调试功能的硬件设备,也可能是某些专门的调试软件(如GDBServer)。
④ 目标机可以是某种形式的系统仿真器,通过在宿主机上运行目标机的仿真软件,整个调试过程可以在一台计算机上运行。此时物理上虽然只有一台计算机,但逻辑上仍然存在着宿主机和目标机的区别。
B. 软件交叉调试
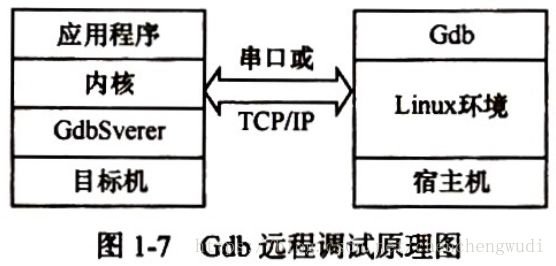
软件方式交叉调试主要通过
插入调试桩
的方式进行,调试桩方式通过在目标操作系统和调试器内分别加入某些功能模块,二者互通信息来进行调试。该方式最经典的调试器就是
GDB交叉调试器
。
GDB交叉调试器分为
GDBServer
和
GDBClient
,其中
GDBServe作为调试桩安装在目标板上
,GDBClient驻于本地的GDB调试器内,其
工作流程
如下:
① 建立调试器(本地GDB)与目标操作系统的通信连接,可通过串口、网卡等多种方式。
② 在目标机上启动GDBServer进程,并监听对应端口。
③ 在宿主机上运行GDB调试器,此时GDB会自动寻找远端的通信进程,也就是GDBServer所在进程。
④ 在宿主机上的GDB通过GDBServer请求对目标机上的程序发出控制命令,
GDBServer将此请求转化为对程序的地址空间或目标平台的某些寄存器的访问
。
⑤
GDBServer把目标操作系统的所有异常处理转向通信模块
,并告知宿主机上GDB当前的异常
⑥ 宿主机上的GDB向用户显示被调试程序产生了哪一类异常。
GDB交叉调试本质:
用软件接管目标机的全部异常处理及部分中断处理
,并在其中加入调试端口通信模块,与宿主机的调试器进行交互。
GDB交叉调试缺点:只能在目标机系统初始化完毕、调试通信端口初始化完成后才能起作用,因此
只能用于调试运行于目标操作系统之上的应用程序,而不宜用来调试操作系统内核代码及启动代码。
C. 硬件交叉调试
① ROM Monitor(ROM监视器)

调试方式:在目标机上运行ROM Monitor和被调试程序,宿主机上的调试器与目标机上的ROM监视器通过远程调试协议
建立通信连接
。ROM监视器可以是一段运行在目标机ROM上的可执行程序,也可以是一个专门的硬件调试设备。在使用这种调试方式时,被调试程序首先通过ROM监视器下载到目标机,然后在ROM监视器的监视下完成调试。
优点:ROM监视器功能强大,能够完成设置断点、单步执行、查看寄存器、修改内存空间等各项调试功能。
缺点:和软件调试一样,使用ROM监视器,目标机和宿主机必须建立通信连接,也就是说目标机也必须先完成环境初始化及通信端口初始化。
② ROM Emulator(ROM仿真器)

调试方式:采用ROM Emulator方式进行交叉调试需要使用ROM仿真器,并且他常常被插入到目标机的ROM插槽中,专门用于
仿真目标机上的ROM芯片
。在使用这种调试方式时,被调试程序首先下载到ROM仿真器中,因此
等效于下载到目标机的ROM芯片中
,然后在ROM仿真器中完成对目标程序的调试。
优点:可以避免每次修改程序后,重新烧写到目标机的ROM中。
缺点:ROM仿真器本身比较昂贵,功能又单一,只适用于某些特定场合。
③ In-Circuit Emulator(ICE)

调试方式:使用ICE调试需要使用在线仿真器,他是目前最为有效的嵌入式系统调试手段。他是仿照目标机上的CPU而专门设计的硬件,
可以完全仿真处理器的行为
。仿真器与目标板可以通过仿真接头连接,与宿主机可以通过串口、网线、USB等方式连接。
仿真器自成体系,因此调试时既可以连接目标板,也可以不连接目标板
。
优点:功能强大,软硬件都可做到完全实时在线调试
缺点:价格昂贵
④ In-Circuit Debugger(ICD)

调试方式:使用ICD调试需要使用在线调试器。由于ICE仿真器的价格非常昂贵,并且每种CPU都需要一种与之对应的ICE,使得开发成本非常高。一个比较好的解决方法是
让CPU可以直接在其内部实现调试功能,并通过开发板上引出的调试端口发送调试命令和接受调试信息,完成调试过程
,ARM处理器的JTAG端口就是由此而诞生的。
JTAG标准
采用的技术为边界扫描技术,其基本思想是在靠近芯片的输入输出管脚上增加一个移位寄存器单元。当芯片处于调试状态时,这些边界扫描寄存器单元可以将芯片和外围的输入输出隔离开来,通过这些边界扫描寄存器单元,可以实现对芯片输入输出信号的观察和控制。
优点:连接简单,成本低
缺点:特性受制于芯片厂商
补充:目前使用
JLink + Eclipse构建的Pangu调试环境
就属于ICD硬件调试环境
JLinkGDBServer:运行在目标机(实际是Jlink上),作为调试Server
arm-linux-gdb:运行在宿主机,作为调试Client
Jlink硬件:连接在开发板与宿主机之间
调试过程中,arm-linux-gdb发出调试命令,JLinkGDBServer将其转换为符合JLink标准的电平信号,并通过JLink硬件发送到CPU的边界扫描寄存器,实现调试功能。
3. ARM体系结构的技术特征及发展
1)ARM技术特征
A. 体积小、低功耗、低成本、高性能
B. 支持Thumb(16位)/ ARM(32位)双指令集,能很好地兼容8位/16位器件
C.
大量使用寄存器,指令执行速度更快
D. 大多数数据操作都在寄存器中完成
E.
寻址方式灵活简单
,执行效率高
F.
指令长度固定
ARM作为RISC微处理器与CISC微处理器技术对比如下:
|
指标
|
RISC
|
CISC
|
|
指令集
|
①指令定长
②指令单周期执行
③无复杂指令,通过简单指令的
组合实现复杂操作
⑤指令译码采用硬布线逻辑
|
①指令变长
②执行需要多个周期
③有复杂指令,一条指令完成
复杂操作
④采用微程序译码
|
|
流水线
|
易于实现流水线执行,流水线每周期前进一步
|
不易于实现流水线执行,指令的执行需要调用微代码的一个微程序
|
|
寄存器
|
更多通用寄存器
|
用于特定目的的专用寄存器
|
|
Load/Store结构
|
独立的Load和Store指令完成数据在寄存器和外部存储器之间的传输
|
处理器能够直接处理存储器中的数据
|
|
编译器优化
|
对编译器要求高,需要编译器对代码做更多优化
|
对编译器要求低
|
说明:为了使ARM指令集能更好地满足嵌入式应用的需求,
ARM指令集和单纯的RISC定义有如下区别
:
① 一些特定指令的周期数可变
比如多寄存器的Load/Store指令的周期数就不确定,必须根据被传递的寄存器个数而定。
②
内嵌桶形移位器
产生更复杂的指令
内嵌桶形移位器是一个硬件部件,在一个输入寄存器被一条指令使用之前,内嵌桶形移位器就可以处理该寄存器中的数据(实际就是
产生第二操作数/shift operand
)。他扩展了许多指令的功能,改善了内核的性能,提高了代码密度。
③ 引入Thumb指令集提高代码密度,并且可以在ARM指令集和Thumb指令集之间切换,以实现代码密度和性能的平衡。(若使用Thumb 2指令集,则无需切换)
④条件执行
⑤引入DSP指令到标准的ARM指令中
2)ARM体系结构的发展
A. 什么是体系结构?
体系结构定义了
指令集(Instruction-Set Architecture,ISA)
和基于这一体系结构下处理器的
编程模型
。基于同种体系结构可以有多种处理器(比如V5架构下有ARM9E、ARM10E等处理器),每个处理器性能不同,应用领域不同,但都遵循这一体系结构。
B. ARM有几种体系结构?
到目前为止,ARM共有V1~V8,这八种体系结构,Cortex-A8就是基于ARMv7架构的第一种内核。在使用中,只要处理器采用相同的体系结构,那么基于他们的应用软件应该是兼容的。
3)ARM微处理器结构特征
A. 大量的寄存器,他们都可以用于多种用途
B. Load/Store体系结构
C. 每条指令都条件执行
D. 多寄存器的Load/Store指令
E. 能够在单时钟周期执行的单条指令内完成一项普通的移位操作和一项普通的ALU操作
F. 通过协处理器指令集来扩展ARM指令集,包括在编程模式中增加了新的寄存器和数据类型
G. 如果把Thumb指令集当做ARM体系结构的一部分,那么还可以在Thumb体系结构中以高密度16位压缩形式表示指令集
4. Cortex-A8存储系统
1)统一编址 & 独立编址
A. 内存与IO
① 内存是程序的运行场所,内存和CPU之间通过
总线连接
,CPU通过地址访问内存单元
② IO是输入输出接口,是CPU和其他外部设备(e.g. 串口)交互的通道。一般的,IO就是指CPU的各种外设。具体编程时,就是操作这些外设的寄存器。
B. 内存的访问方式
① 内存通过CPU的
地址总线来寻址
,然后通过
数据总线来读写
② CPU的地址总线的位数是CPU设计时确定的,因此一款CPU的寻址范围是一定的。而内存是需要占用CPU寻址空间的。
注:由于
CPU的寻址空间是一种有限的资源
,在设计CPU时不会将所有寻址空间都给外接的内存。对于S5PV210芯片,最大支持1.5G内存(具体可参考芯片的memory map)。
③ 内存与CPU的这种总线式连接方式是一种直接连接,优点是效率高访问快;缺点是资源有限,扩展性差。
C. IO的访问方式
CPU访问各种外设有2种方式:
① IO与内存统一编址
将外设的寄存器地址当作一个内存地址来读写,从而以访问内存的方式来控制外设
注意:此处只是软件编程时访问的方式一样,但内部实现是不一样的
优点:编程简单
缺点:IO需要占用CPU的寻址空间,而CPU的寻址空间资源是有限的
② IO独立编址
外设寄存器单独编址,使用专用的CPU指令来访问特定外设
优点:不占用CPU地址空间
缺点:编程模式复杂,本质上是CPU设计更复杂
说明:一般CISC架构使用独立编址(e.g. X86),RISC架构使用统一编址
2)冯诺依曼结构 & 哈佛结构
A. 冯诺依曼结构

更正:图中的地址总线应该是从CPU到RAM单向的(后续图片也有该问题)
① 程序和数据都放在内存中,且
彼此不分离
② Intel的CPU均采用冯诺依曼结构
优点:处理简单
缺点:由于程序和数据不区分,存在安全性和稳定性问题
B. 哈佛结构

① 程序和数据分开独立放在不同的内存块中,
彼此完全分离
(
需要有独立的指令总线和数据总线
)
② 大部分单片机均采用哈佛结构
优点:哈佛结构中程序(一般放在ROM/Flash中)和数据(一般放在RAM中)独立分开存放,稳定性和安全性高
缺点:软件处理复杂(
需要统一规划链接地址
等)
C. 混合式结构
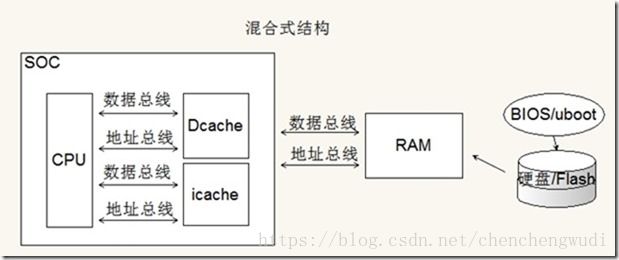
① 芯片内部使用哈佛结构,通过Dcache和Icache分别缓存数据和指令,提高了CPU的访问速度
② 芯片外部使用冯诺依曼结构,使得数据和指令共享一个存储器空间。节省了外部的PCB走线资源(节省了一套数据 & 地址总线)。
注意:S5PV210实际上使用的就是这种混合式结构
参考资料:
http://www.cnblogs.com/douzi2/p/4876551.html?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
3)CPU与外部存储器的连接方式
A. 常用外部存储器
① Flash类(电子式)
a. NorFlash
总线式访问,可接在S5PV210的SROM Bank,一般用于启动
补充:目前也有SPI接口的NorFlash
b. NandFlash系列(本质上均为NandFlash)
NandFlash
分为SLC和MLC。SLC容量小/稳定性高;MLC容量大/价格低/稳定性差
SD卡/TF卡/MMC卡
相当于
NandFlash + controller
,具备自动管理坏块等功能,可以减轻CPU负担
eMMC/iNand/moviNand
eMMC即embedded MMC,本身是一种标准。iNand是Sandisk公司生成的eMMC;moviNand是三星公司生产的eMMC
oneNand
三星公司生产的一种NandFlash,使用面较窄
eSSD
即embedded SSD,嵌入式固态硬盘
② 硬盘类(机械式)
SATA硬盘
B. 连接方式
① 根据S5PV210 memory map,ONENAND / NAND区域只有256M,远小于NAND的大小。这是因为
NAND不通过CPU地址总线访问
,所以不占用地址空间。此处的NAND区域为相关controller & SFR的访问空间。
② 通过CPU的外部存储器controller连接
③ 对外存的访问时序也比内存复杂
4)存储器层次结构

说明:紧耦合存储器TCM是为弥补cache访问的不确定性增加的存储器,他是一种SDRAM,速度快、紧挨内核,并且保证取指和数据操作的时钟周期数,这对要求确定行为的实时算法很重要。
TCM位于存储器地址映射中,可作为快速存储器访问
。
5)存储系统技术
A. 使用
cache
,缩小处理器和存储系统速度差别,从而提高系统整体性能。
B. 使用
内存映射技术
实现虚拟空间到物理空间的映射。
C. 引入
存储保护机制
,增强系统的安全性。
D. 引入一些机制保证将I/O操作映射成内存操作后,各种I/O操作能够得到正确的结果。而当系统引入cache和write buffer后,就需要一些特别的措施。
6)协处理器
A. ARM处理器最多支持16个协处理器(但
一般仅实现CP15
),在程序执行过程中,每个协处理器忽略属于ARM处理器和其他协处理器的指令。当一个协处理器硬件不能执行属于他的协处理器指令时(比如没有需要的协处理器),将产生一个未定义指令异常中断,在该异常中断处理程序中,可以通过软件模拟该硬件操作。
B. CP15
① 在ARM系统中,要实现对存储系统的管理通常是使用协处理器C15,他通常被称为系统控制协处理器(System Control Coprocessor)。
② CP15包含16个32位寄存器(编号0~15),
实际上对于某些编号的寄存器可能对应多个物理寄存器,在指令中指定特定的标志位来区分这些物理寄存器
。
7)存储管理单元MMU
MMU提供了一些资源以允许使用虚拟存储器(将系统物理存储器重新编址,可将其看成一个独立于系统物理存储器的存储空间),
MMU作为转换器,将程序和数据的虚拟地址(编译时的链接地址)转换成实际的物理地址
。这个转换过程中允许运行的多个程序使用相同的虚拟地址,而各自存储在物理存储器的不同位置。
注:在使用MMU后就有两种类型的地址
① 虚拟地址:由
链接器
在定位程序时分配
② 物理地址:用来访问实际的主存储器硬件
8)高速缓冲存储器(cache)和写缓冲器(write buffer)
① cache是一个容量小但存取速度非常快的存储器,他保存最近用到的存储器数据副本。
②write buffer是一个非常小的FIFO存储器,位于处理器核与主存之间。当CPU向主存储器做写入操作时,他先将数据写入到write buffer中,然后write buffer在CPU空闲时以较低的速度将数据写入到主存储器中。
注意:通过引入cache和write buffer,存储性能得到很大提高,但同时也带来一些问题。例如,由于数据存在于系统中不同的物理位置,
可能造成数据的不一致性
;由于write buffer的优化作用,可能有些写操作的执行顺序不是用户期望的顺序,从而造成操作错误。
5. 流水线
说明:流水线的级数及设计与CPU架构相关
1)ARM 7流水线
ARM 7采用冯诺依曼结构 + 3级流水线
A. ARM 7体系结构
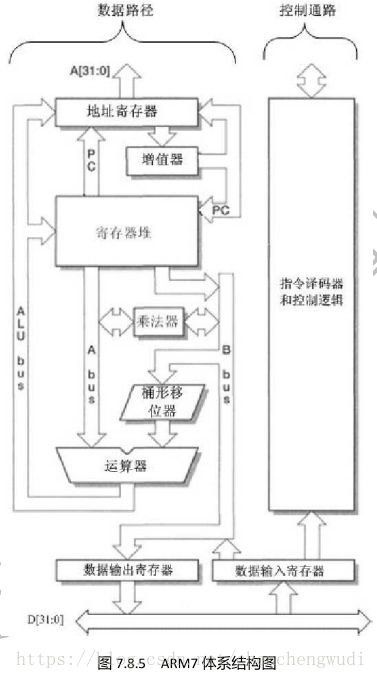
①处理器寄存器堆(Register Bank)
包括状态寄存器和通用寄存器,主要用来保存处理器的状态和处理器操作需要的数据。
a. 他有
两个读端口
和
一个写端口
,每个端口都可以访问任意寄存器。
b. 还有
附加的可以访问PC的一个读端口和一个写端口
,PC附加写端口可以在取指地址增加后更新PC;读端口可以在数据地址发出之后重新开始取指。
②桶形移位器(Barrel Shifter)
他可以把指令中的第二操作数移位或循环移位
③运算器(ALU)
完成指令集要求的算术或逻辑功能
④地址寄存器(Address Register)和增值器(Incrementer)
可选择和保存所用的存储器地址并在需要时通过地址增值器产生顺序地址
⑤数据输出寄存器(date-out register)和数据输入寄存器(data-in register)
用于保存传输到存储器和从存储器读出的数据
⑥指令译码器和相关控制逻辑(instruction decode and control)
完成指令译码和相关的控制逻辑
B. ARM 3级流水线
①流水线分级及简单指令执行

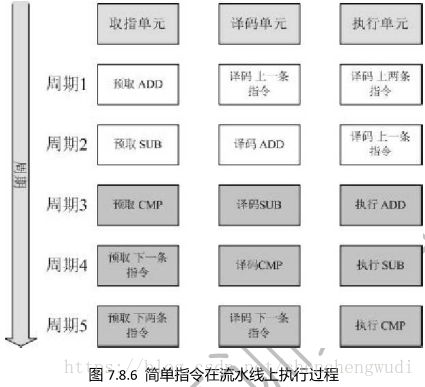
取指(fetch):从存储器中读取指令
译码(decode):分析指令并为先一个周期准备数据路径需要的控制信号。在这一级,指令占用译码逻辑,不占用数据通路。
执行(execute):完成指令要求的操作,并根据需要将结果写回寄存器。指令占用数据路径,寄存器堆被读取,操作数在桶形移位器中被移位。运算器产生运算结果并回写到目的寄存器中,运算器根据指令需求和运算结果更改状态寄存器的条件标志位。
重要结论:ARM处理器中PC的值是取指令的地址,所以PC的值是当前正在执行指令的地址 + 8 字节(32位ARM指令)
②多周期指令会打乱流水线
由于冯.诺依曼结构中指令和数据都存储在相同的存储器中,各个单元不能同时占用存储器端口。因此在ARM7 指令流水线上必须等LDR指令执行完毕后才能恢复正常流水线。
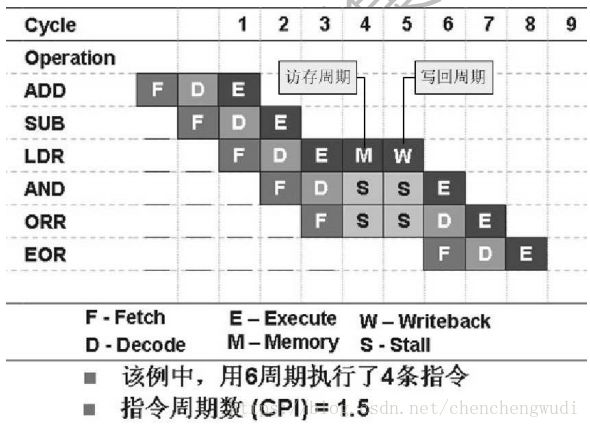
分析:由于LDR要求从存储器中取数据,在周期3执行LDR后,处理器按照LDR指令的要求访问存储器(包括给出地址和将数据写回寄存器),所以占用了处理器内部的数据路径。由于访问存储器要花费更多的时钟周期,所以RISC体系结构要求更多寄存器。
2)ARM 9流水线
ARM 9采用片内哈佛结构 + 5级流水线
A. ARM9体系结构

改进之处:
在冯.诺依曼结构中,访问数据存储器操作时,不得不停止取指操作,从而使性能受到影响。较高性能的ARM核使用5级流水线,而且具有分开的指令和数据Cache。
B. ARM 5级流水线
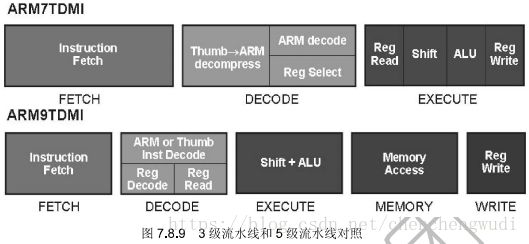
取指(fetch):从存储器中取出指令,并将其放入指令流水线
译码(decode):指令被译码,从寄存器堆中读取寄存器操作数。在寄存器堆中有3个操作数读端口,因此大多数ARM指令能在1个周期内读取其操作数
执行(execute):将其中一个操作数移位,并在ALU中产生结果。如果指令是Load或Store,则在ALU中计算存储器地址
缓冲/数据(buffer/data):如果需要则访问数据存储器,否则ALU只是简单地缓冲一个时钟周期,以便所有的指令具有同样的流水线流程
回写(write-back):将指令结果回写到寄存器堆,包括任何从寄存器读出的数据。
特别注意:在程序执行过程中,PC值是基于3级流水线操作特性的,完全仿真3级流水线的行为,这保证了软件的兼容性。
3)影响流水线性能的因素
A. 互锁
即一条指令的结果被用作下一条指令的操作数,如:
LDR r0, [r0, #0]
ADD r0, r0, r1
B. 跳转指令
跳转指令会导致已经被预取进入流水线的指令被丢弃。
改进:尽可能使用条件执行指令代替跳转指令
6. S5PV210 memory map
1)什么是memory map
① S5PV210属于Cortex-A8架构,地址线 & 数据线宽度均为32位
② 32位地址线决定了地址空间为4G,
memory map就是分配这4G的地址空间如何使用
2)S5PV210地址映射分析


说明1:从0x0000000开始的Boot area是一段用于映射的区域,根据启动模式的不同,会将对这段地址的访问映射到相应区域。
在映射到IROM的情况下,S5PV210会从IROM的BL0开始运行
补充:在S5PV210中,其实无论采用哪种启动方式,目前都是先运行BL0,即将iROM映射到memory map的零地址处
说明2:IROM&IRAM空间有限,而BL1需要拷贝到IRAM中运行,所以要么限制BL1的大小;要么在BL1中初始化内存,并将BL1拷贝到内存继续运行(uboot的做法)。
说明3:S5PV210支持最大1.5G内存(Bank 0:512M,Bank 1:1024M)
3)Internal Memory Map

说明1:所谓Internal Memory就是集成在SoC内部的存储设备,S5PV210中包括IROM/IRAM/DMZ ROM
说明2:关于Secure area
被配置为Secure area的部分会受到CPU数据校验的保护,以防止数据拷贝过程中发生错误。在S5PV210中,IROM均为Secure area;IRAM的Secure area范围由寄存器TZPCR0SIZE配置,可配置为full/0KB/4KB/64KB
7. S5PV210启动过程详解
1)启动介质
作为嵌入式系统的启动介质,需要满足以下2个条件,
① CPU可通过地址总线访问
② 上电后CPU可直接使用,无需初始化
这是因为ARM在启动后,会将PC置为0,并开始取指运行。
2)启动过程中涉及的存储设备
A. 内存
① SRAM
容量小/价格高;但不需要初始化,上电后可直接使用
② DRAM
容量大/价格低;但上电后不能直接使用,需要软件进行初始化
B. 外存
① NorFlash类
容量小/价格高;但是和CPU总线式连接,上电后CPU可直接读取
补充:目前也有其他接口的NorFlash,比如SPI NorFlash,以此节省引脚
② NandFlash类
类似硬盘,容量大/价格低;但是不能总线式访问,即上电后CPU无法直接读取,需要先对其初始化然后通过时序接口读写。
补充:NandFlash只能将1写为0,不能将0写为1。因此在NandFlash编程之前,必须将对应的块擦除,而擦除的过程就是把所有位都写为1的过程
说明1:根据对启动介质的描述,
SRAM和NorFlash可以作为启动介质
说明2:存储设备的使用场景
单片机:内存需求量小,而且希望开发尽量简单,适合全部使用SRAM(e.g. 51单片机)。
PC机:内存需求量大,而且软件复杂,不在乎DRAM的初始化开销,适合全部使用DRAM。由BIOS(一般为NorFlash)作为启动介质。
嵌入式系统:内存需求量大,而且出于成本考虑,目前的嵌入式系统大多没有NorFlash等可启动介质。通常使用NandFlash + DRAM,但二者均不能作为启动介质,所以需要SoC内置启动介质。
S5PV210就是采用iROM + iRAM作为启动介质
说明3:为了与
启动介质
区分,下文中在分析S5PV210启动过程中会采用“启动设备”一词。根据OM拨码管脚选择的
启动设备
,其实只是用于运行BL1,真正起始的BL0是在启动介质中运行完成。
3)启动设备选择
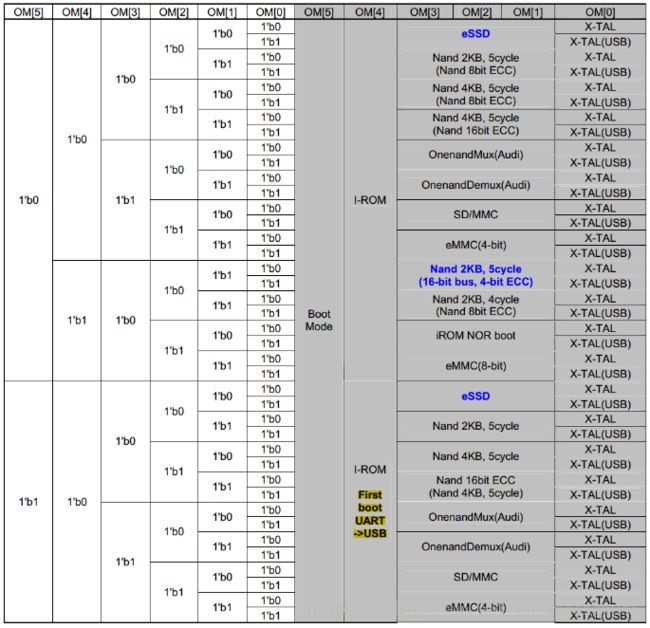
说明1:S5PV210通过OM拨码开关选择启动设备,我们可以以OK210的启动方式来验证。OK210启动拨码设置如下,

OK210将OM[5]焊接连接低电平,不支持从UART/USB启动。
OM[4 : 1] = 0010对应Nand 4KB,5Cycle
OM[4 : 1] = 0110对应SD/MMC
注意:这里的SD/MMC正常启动必须使用MMC channel 0,如果MMC channel 0已被占用,则实际是使用MMC channel 2实现2nd boot(OK210 & X210的SD卡均使用了channel 2,即均作为second boot使用)
说明2:当OM[5] = 1时,会首先从UART/USB启动,X210就使用这种拨码方式 + dnw进行裸机代码的调试。
4)iROM(BL0)启动流程
注:该流程为三星的推荐流程,Uboot等bootloader并不一定完全遵循


说明1:BL0初始化只涉及SoC的内部资源有2个原因
① 使用S5PV210芯片的板载资源千差万别,BL0只能初始化SoC内部资源
② BL0的目的是加载BL1并运行,所以只需要初始化会使用到的设备
说明2:BL0初始化后的iRAM内存布局

注意上图中的Header Info,后文会详细说明
说明3:BL1的下载地址和运行地址
在非UART/USB启动模式下,BL0会从存储设备中拷贝
16KB
数据到
0xD0020000
处,然后进行校验。校验成功后,从
0xD0020010
处运行。
也就是说从0xD0020000处开始的16B为校验数据,
如果从UART/USB启动,因为无需校验数据,所以直接下载到0xD0020010处运行即可
。
说明4:关于Block Device Copy Function

性质:由三星提供,相当于硬件附带的库函数
用途:用于从块设备上拷贝数据到内存(e.g. 将BL1 / BL2从eMMC拷贝到内存)
使用方法:直接对函数对应的地址进行类型转换

说明5:BL0初始化后的系统时钟

5)完整启动流程框图

说明1:BL1/BL2大小限制
BL1最大16KB
BL2最大80KB
说明2:BL1的Header Info

根据整体启动流程,BL0会检查BL1的checksum。
注意检查checksum与Secure Boot是两回事
,Secure Boot会使用到signature区域。而且BL1加载BL2后不会检查checksum。

因为有了16B的Header Info,BL1代码的实际起始地址为0xd0020010
说明3:checksum的计算方式

说明4:在启动的各个阶段,都会判断系统是启动过程还是从睡眠中被唤醒。如果是从睡眠中被唤醒,将跳过本阶段直接跳转到下个阶段。
6)S5PV210加头文件说明
mkv210_image.c核心步骤如下:

① 分配16KB的buffer
② 将源文件(e.g. led.bin)读到buffer的第16B开始处
③ 计算校验和并将校验和保存在buffer的8 ~ 11B处
④ 将16KB的buffer拷贝到目标文件(e.g. 210.bin)
说明1:BL1的长度不能超过16KB - 16B,如果超出将被截断
说明2:虽然读取到Buf中的BL1可能不足16KB - 16B,但是计算checksum时是按照16KB -16B进行计算,计算的素材就是Buf中的内容。而且
在构造Header info时也只写入了checksum字段,并没有设置BL1 size字段
。

由此可以推断,S5PV210在启动阶段加载BL1时,默认就是加载16KB。
7)关于Second Boot support

说明1:
S5PV210为所有启动设备都提供了2nd boot device,该设备指定为SD/MMC channel 2 with 4-bit data
说明2:何时进入2nd boot
只在
BL1 checksum校验失败时进入
说明3:x210 SD卡启动说明
x210开发板板载inand使用SD/MMC channel 0启动,所以要想从SD卡启动需要满足2个条件,
① SD卡接在SD/MMC channel 2
② SD/MMC channel 0上的inand中的BL1必须被破坏,使其checksum校验不通过

说明4:SD卡启动的通常用途
SD卡启动一般用于开发板的出厂烧写eMMC。此时板载eMMC为空,通过从SD卡启动(实际时通过SD/MMC channel 2启动)可以实现对eMMC的烧写。
8)关于UART/USB启动
说明1:启动的先后顺序
当OM[5] = 1时,S5PV210会从UART/USB启动,但这是有先后顺序的。S5PV210会先尝试从UART启动,当UART启动超时时,才会从USB启动。
说明2:
无需Header Info
从UART/USB启动时,无需Header Info
特别注意:使用dnw下载裸机代码时,地址为0xD0020010,且代码无需加头
实际测试:USB/UART启动时程序直接从0xD0020010开始运行;使用其他存储设备启动时其实也是从0xD0020010运行,只不过运行前需要先对0xD0020000起始的16B进行校验。
也就是说x210使用的dnw工具的行为是,可下载到指定地址,但均从0xD0020010开始运行
已上机验证,下面记录验证过程(该验证基于Linux版本dnw):
step 1:点灯原始代码测试
点灯原始代码如下,

① 当程序下载到0xD0020010时,可以将LED点亮
② 当程序下载到0xD0020000时,LED无法点亮
解释:程序下载到0xD0020000,但运行从0xD0020010开始(到此步骤,仍为假说~~)所以会越过4条ARM指令,即不会对GPJ进行设置。而这些管脚的默认值为Input模式,所以无法点亮LED。
step 2:点灯修改代码测试
点灯修改代码如下,
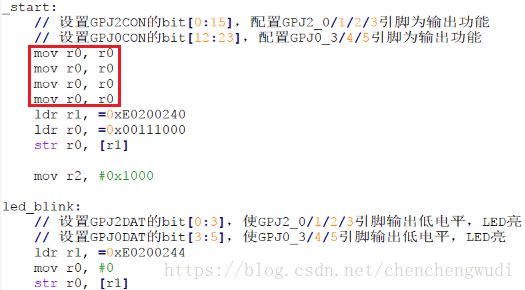
① 当程序下载到0xD0020000时,LED可以点亮
解释:人为在GPIO配置代码前添加4条ARM指令,正好16B。所以从0xD0020010开始运行时,可以执行到GPIO配置代码。
实验结果说明,
USB/UART启动并不需要checksum,而且直接从0xD0020010开始运行
。
9)启动设备布局要求

可见当启动设备为SD/MMC/eSSD时只能从第1个扇区开始烧写BL1;而Nand和eMMC可以直接使用第0个扇区。
补充:SD卡启动时烧写程序命令说明
sudo dd iflag=dsync oflag=dsync if=210.bin of=/dev/sdb seek=1
① dsync是指定读写文件时采用同步方式,不使用缓存/缓冲
② /dev/sdb就是SD卡的设备文件名
③ seek=1是指SD卡的第一个扇区
SD卡的起始扇区为0,一个扇区的大小为512B。从SD卡启动时,iROM中固化的代码会从扇区1开始拷贝16KB数据到iRAM中并校验运行。