
我们都知道redis集群下对于mget、mset、pipeline、事务的支持不太好。
当然对于mget和mset有这么几种方法:
1、串行遍历key依次执行(这种就是把批量拆开了)
2、使用hash_tag包装key,在计算key的slot时候,如果key包含{},就会使用第一个{}内部的字符串作为hash key,这样就可以保证拥有同样{}内部字符串的key就会拥有相同slot(这种方式其实就是把一次批量操作的key全部放到了集群的一个节点进行操作,屏蔽掉多节点的问题)。
3、自己手动进行批量的key做处理,通过CRC16算法对所有的key进行分组(相同slot的分成一组),然后不同的分组keys,使用不同的集群节点进行处理。
本文就是适用了第三种方式,通过 pipeline来操作批处理,减少网络请求次数,加快处理速度。
使用jedis封装的工具类,源码也是分析的jedis。
1、通过源码看下原理
对于jedis,集群的操作使用的JedisCluster类,看下它的继承实现关系图:

通过继承实现管理可以看到,JedisCluster继承自 BinaryJedisCluster ,以及实现了其他接口。我们再查看下 BinaryJedisCluster源码。

在图中我们注意到:JedisClusterConnectionHandler 这个类,字面意思redis集群连接处理器,同时这个connectionHandler变量在此类中还没有公共的获取方法。我们再往后看,我们进去到JedisClusterConnectionHandler 源码看下。
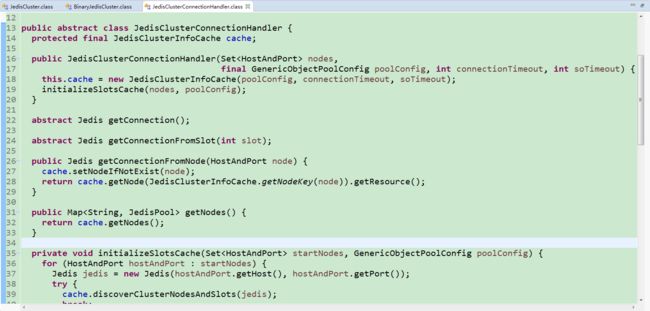
这个类中有一个内部变量JedisClusterInfoCache cache,看着字面意思是Redis集群信息缓存,但是JedisClusterConnectionHandler中没有获取cache的公共方法,往下看下JedisClusterConnectionHandler中的方法,initializeSlotsCache()
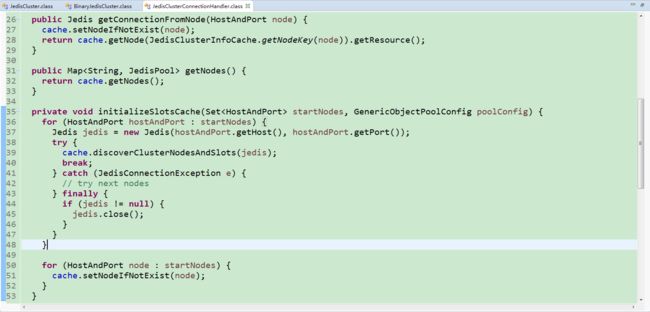
这个变量中存储了所有的redis集群节点信息(包含了host和端口),那这里面有没有集群的其他信息呢?比如slots哈希槽数据,我们再看下JedisClusterInfoCache的源码。

看到这里相信你已经明白了,就是这个cache存储了redis集群节点数据和哈希槽对应的节点关系数据,同时这俩变量还是私有的,往下看下源码有没有直接获取这俩变量的方法呢,答案是看下图。
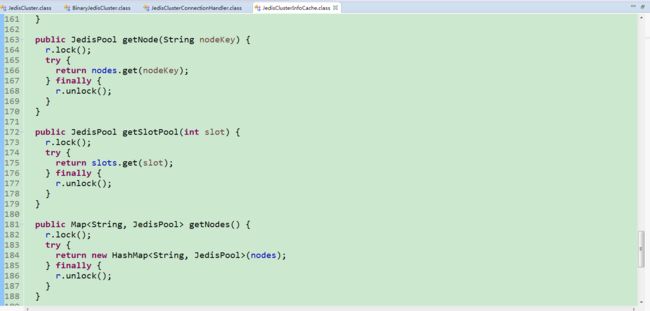
只有获取节点信息(host+ip对应的连接池数据集合)的方法,没有获取哈希槽对应的节点数据的方法。但是有通过slot获取节点连接池的方法,这个也是jedis中JedisCluster集群操作类可以处理集群操作的关键。我们通过getSlotPool(int slot)方法内部实现可以知道,slots集合中存储的关系就是slot对应redis集群节点连接池,这里就是我们后面实现集群下操作的关键,先记一下。
2、通过反射获取内部私有变量
反射的知识请自行百度下或者看下其他人的博客,简单说,它很强大,可以通过它获取这个类或对象中的任何东西,包含私有变量、方法。
直接看下代码实现:
String clusterNodes="172.16.16.90:16379,172.16.16.90:16380,172.16.16.91:16379,172.16.16.91:16380,172.16.16.92:16379,172.16.16.92:16380";
int redirects=3;
int timeOut=2000;
String[] serverArray = clusterNodes.split(",");
Set nodes = new HashSet();
for (String ipPort : serverArray) {
String[] ipPortPair = ipPort.split(":");
nodes.add(new HostAndPort(ipPortPair[0].trim(), Integer.valueOf(ipPortPair[1].trim())));
}
JedisCluster cluster=new JedisCluster(nodes, timeOut, redirects);
Field hfield = cluster.getClass().getDeclaredField("connectionHandler");//获的变量名为connectionHandler的变量
hfield.setAccessible(true);//打开访问权限
JedisClusterConnectionHandler connectionHandler = (JedisClusterConnectionHandler)hfield.get(cluster);
Field cfield = connectionHandler.getClass().getDeclaredField("cache");//获的变量名为cache的变量
cfield.setAccessible(true);//打开访问权限
JedisClusterInfoCache cache = (JedisClusterInfoCache)cfield.get(connectionHandler);
//获取ip+port对应的连接池
Map nodes2 = cache.getNodes();//这个我们没怎么用到
Field field = cache.getClass().getDeclaredField("slots");//获的变量名为slots的变量
field.setAccessible(true);//打开访问权限
//获取slot对应的连接池
Map slots=(Map)field.get(cache); 可能有人要问:connectionHandler不是属于BinaryJedisCluster,因为JedisCluster继承自BinaryJedisCluster,所以同样可以获取到它的内部变量。
如果你的项目框架用的spring(spring boot)+mybatis的话,那更简单,直接使用mybatis封装的反射工具操作更方便。
//前面跟上面一样的,就省略了
//通过Mybatis的反射工具实现
MetaObject metaObject = SystemMetaObject.forObject(cluster);
JedisClusterInfoCache cache = (JedisClusterInfoCache) metaObject.getValue("connectionHandler.cache");
//获取ip+port对应的连接池
Map nodes2 = cache.getNodes();
//通过反射获取JedisClusterInfoCache中的slots
MetaObject meta = SystemMetaObject.forObject(cache);
//获取slot对应的连接池
Map slots=(Map)meta.getValue("slots"); 是不是省了很多的代码?
3、关于spring框架内获取JedisCluster对象
答案在spring的JedisConnectionFactory类中。

spring下配置redis集群是肯定要使用JedisConnectionFactory的,那么可以通过这个连接工厂类获得JedisCluster,但是我们看到,它又是私有的,同时这个类中的公共方法也没有直接获取的。那只能又得通过反射方式获取了。
@Configuration
@EnableCaching
public class RedisCacheConfig extends CachingConfigurerSupport{
protected final static Logger log = LoggerFactory.getLogger(RedisCacheConfig.class);
private volatile JedisConnectionFactory jedisConnectionFactory;
private volatile RedisTemplate redisTemplate;
private volatile RedisCacheManager cacheManager;
public RedisCacheConfig() {
super();
}
public RedisCacheConfig(JedisConnectionFactory jedisConnectionFactory, RedisTemplate redisTemplate, RedisCacheManager cacheManager) {
super();
this.jedisConnectionFactory = jedisConnectionFactory;
this.redisTemplate = redisTemplate;
this.cacheManager = cacheManager;
}
public JedisConnectionFactory redisConnectionFactory() {
return jedisConnectionFactory;
}
public RedisTemplate redisTemplate(RedisConnectionFactory jedisConnectionFactory) {
return redisTemplate;
}
public CacheManager cacheManager(RedisTemplate redisTemplate) {
return cacheManager;
}
//通过反射获取spring管理的JedisCluster对象
@Bean
public JedisCluster jedisCluster(){
MetaObject metaObject = SystemMetaObject.forObject(redisConnectionFactory());
return (JedisCluster)metaObject.getValue("cluster");
}
@Bean
public KeyGenerator keyGenerator() {
return new KeyGenerator() {
@Override
public Object generate(Object target, Method method,
Object... params) {
//规定 本类名+方法名+参数名 为key
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName()+":");
sb.append(method.getName()+":");
for (Object obj : params) {
sb.append(obj.toString()+",");
}
sb.deleteCharAt(sb.length() - 1);
return sb.toString();
}
};
}
} 我们可以直接通过设置一个@Configuration配置类,在这里面注入jedisConnectionFactory对象,再通过它获得JedisCluster,并设置一个bean供后面使用。像这样:
@Configuration
public class RedisConfig {
@Autowired
private JedisConnectionFactory jedisConnectionFactory;
//通过反射获取spring管理的JedisCluster对象
@Bean
public JedisCluster jedisCluster(){
MetaObject metaObject = SystemMetaObject.forObject(jedisConnectionFactory);
return (JedisCluster)metaObject.getValue("cluster");
}
}4、通过JedisCluster实现集群操作
获取到了JedisCluster对象,下面就可以直接进行集群下pipeline实现各种集群无法实现的mget、mset等等。
再次说下原理:通过CRC16算法求出所有需要操作的key对应的slot,再通过slot获取到对应的节点连接池,以连接池进行slot分组,进而对相同连接池的key划分到一个组中,然后只需要对相同连接池的key集合进行批量操作就可以了,相当于一个节点下批量操作,同时又使用了pipeline减少了请求,合并了多次请求,加快了处理速度。
@Component
public class JedisClusterUtil implements InitializingBean{
@Autowired
private JedisCluster jedisCluster;
//存放每个节点对应的连接池
private Map nodes ;
//存放每个哈希槽(slot)对应的连接池
private Map slots ;
@Override
public void afterPropertiesSet() throws Exception {
// TODO 属性赋值之后执行
//从而获取slot和JedisPool直接的映射,通过Ibatis的反射工具实现
MetaObject metaObject = SystemMetaObject.forObject(jedisCluster);
//获取到JedisClusterInfoCache 对象后,在进行批量操作时,就可以根据key计算其slot值,得到对应的JedisPool,对key进行分类,然后以pipeline的方式获取值。
JedisClusterInfoCache cache = (JedisClusterInfoCache) metaObject.getValue("connectionHandler.cache");
nodes=cache.getNodes();
//通过反射获取JedisClusterInfoCache中的slots
MetaObject meta = SystemMetaObject.forObject(cache);
slots=(Map)meta.getValue("slots");
}
/**
*
*
* @Title: mget
* @Description: 批量获取
* @param @param keys
* @param @return 设定文件
* @return List 定义一个spring组件,实现InitializingBean接口,重写afterPropertiesSet()方法,这样做的目的就是,在bean初始化后,属性赋值之后执行slots的赋值,这样可以全局使用此集合。相信看代码可以明白细节。
留下两个问题:
1、如果redis集群节点出现增加或者删除,或者主从节点的变动该如何处理呢?
2、spring-data-redis的RedisTemplate在集群下操作单个key时可以直接使用,但是如果用RedisTemplate添加一条数据,用jedis的JedisCluster读取一条数据,肯能会存在序列化和反序列化问题,这个该如何处理呢?
可以思考下。
redis集群操作:https://www.cnblogs.com/tony-zt/p/10185660.html
jedis cluster源码学习:https://blog.csdn.net/sinat_36553913/article/details/90342053
https://blog.csdn.net/sinat_36553913/article/details/90551403
https://segmentfault.com/a/1190000013535955
https://www.jianshu.com/p/5ca98b5a336b