百万台服务器!双十一阿里巴巴电商业务的高效资源运营之道
讲师 | 杨仪 阿里系统软件事业部调度系统技术专家
编辑 | 黄晓轩
本文整理自杨仪在GOPS全球运维大会上的演讲,首发于公众号:高效运维
讲师简介
杨仪
2010年入职阿里从事监控系统运维研发
2012年调入运维团队,负责淘系核心交易系统运维
2016年负责系统软件事业部资源运营团队,负责阿里在线业务的资源运营。
负责过多年双11交易运维保障,在自动化运维、DevOps、资源运营方面有一定的实践经验。
前言
大家好,我是杨仪,今天我给大家带来一些关于资源运营方向的分享。我们今天讨论的主要内容有四部分:
资源运营的演变
规模化运维平台
降低资源成本
智能化运营
资源运营的演变

首先我想分享一下整个阿里在 Devops 的演进历程。
Devops 的概念这几年是很火,阿里的业务运维也是经历了这样一个阶段。
我刚进阿里的时候大部分运维相关操作,运维人员都是通过登机器、敲键盘去做的。逐步我们会有一些工具去操作、执行重复性的工作。
随着业务规模不断增大,团队发现不可能无限数量地招运维人员去做重复的事情,所以引入 Devops。
经过这两三年的发展,阿里在线运维基本上达到了初步自动化的状态,同时我们正在向智能化的方向摸索。
整体看下来我认为阿里在运维领域,容器化是 Devops 转型过程中最重要的里程碑阿里现在在线业务中大规模使用 docker 容器。

接下来我想讲一下阿里这十几年来在线业务的升级。
未来运维的方向是 Opsless。
传统运维能做的事情一定越来越少,最终有可能会做到 NoOps 的状态。
近三年来运维人员规模没有增长,甚至有些是下降的。
整体来看一开始是做面向单对象运维,配置文件、包等这个时代已经过去了。
接下来是面向容器运维,当下演进的状态,运维粒度扩大到image。第三个是面向Pod运维,业界流行,服务相关容器打包到Pod,进一步扩大运维粒度。第四是面向Box运维,阿里规模大,业态丰富,所以后面有可能到达第四个阶段。

运维做久了以后他的上升空间,比方说整天都在做些运维的事情,那未来发展的方向是什么呢?
在阿里运维他是有两个方向要突破:
第一方向是回归到业务,和业务去做深度融合,比如专注去做智能化监控、智能化故障定位等。第二方向是下沉到调度领域,下沉到内核这块。
我现在的团队相当于做的是下沉这块。所谓的资源运营就是指我们想要做超大体量的数据中心的资源管理策划,做这些最终是为了降低整个阿里生态体系的资源运行成本。
想做到这些我们有很多挑战:
建设统一调度的能力。阿里有很多业务,比如说淘宝、天猫、聚划算等等,各种各样的电商业务,我们对这些业务怎么去做资源的分配,这就需要我们有同步的调动器。
资源供需模式,需要的是集中式、扁平化的资源供需。把整个的在线资源调度能力作为中台输出。
提升资源利用率。大家知道在线业务要考虑容灾、异地部署的需求,有的数据中心,集群的利用率都不会很高,但阿里的资源利用率都在10%,整体来看提升空间非常非常大。

前面提到是资源运营本身的挑战,我们从运维团队转型做资源运维,面临更多的挑战是围绕着效率、成本、稳定性去解决双11资源使用问题。
传统运维运营向自动化运营的转型。每到双11大促,所有的业务都来和你说要加机器,以前都是人肉评估,人肉去运营的模式。我希望把这种运营模式转化成系统运营。
资源需求的集中爆发。在双11场景下,资源需求是集中爆发的,我们会有数十个BU,因为“双11”这么大的活动在阿里内部是整体协同的大作战,包括优酷、菜鸟、天猫都会参与到“双11”里面来,那这里面的需求量,很多很多系统都会来问我们要资源。
业务和成本之间寻求平衡。为了支持双11,怎么能够用最低的成本去满足最多的业务需求。
运维平台要有很高的可靠性。
规模化运维平台
基于前面的那些挑战,我们最核心的关键是要打造一个规模化的运维平台。阿里有两万多个工程师,每个工程师负责一个系统的话就有两万多个系统。

我们通过规模化运维平台来提升资源运营的效率。
资源调度系统。提到了Sigma调度器,一站式资源交付。他可以很简单的点几下按纽,就可以把需要的资源交付给他。
资源管理的过程中引入了预算和额度管理机制。年初的时候希望每个团队都向资源运维团队提供未来一年资源需求的规划。我们基于这个规划会统一的看阿里巴巴集团未来资源的需求,然后会制定相应的资源交付计划。
弹性伸缩。解决海量应用的容量备容效率问题。
解决规模化执行问题。
比如说双11的时候要扩容几十万个容器上去,这对我们规模化执行的效率要求就很高。还有点现在都用的是容器,容器就会涉及到容器级别的偏袒,一台物理机要怎么样部署,要有哪些组合才能让这台物理机上的资源运用好。
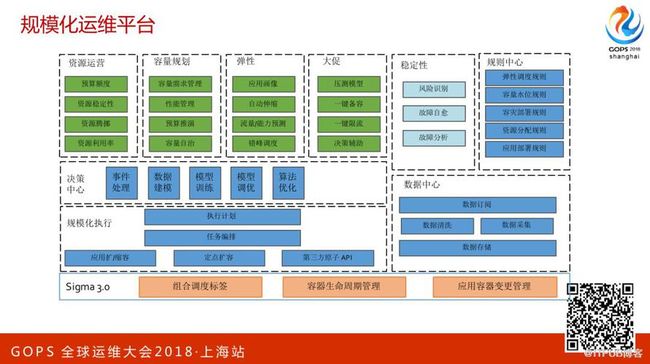
这是规模化运维平台整体的架构。规模化运维的目标是做批量大规模的,不会去对单个应用做传统的运维支撑,所以规模化运维是用很少的运维人员投入解决万级别的系统交付。
首先在资源运营这块有预算额度和整个的管理系统,比方说业务他要提交他的预算,整个系统会根据他的预算决定在哪个时间点交付多少资源。
第二是容量规划,根据业务平时的表现可能会去推算未来阿里巴巴在明年的业务增长。
第三是弹性伸缩,我们会对所有的线上系统做实时的分析,在平时的时候通过弹性来做自动的容量管理。其实还有一系列的架构在里面,比方说决策中心。
整个规模化的操作都会在决策中心做数据处理,比方说执行大规模的销毁容器的动作,那可能就会由决策中心预判。上面是资源运营的体系,最下面是调度器。基于上面这套对最底层的容器去做一整套的管理。
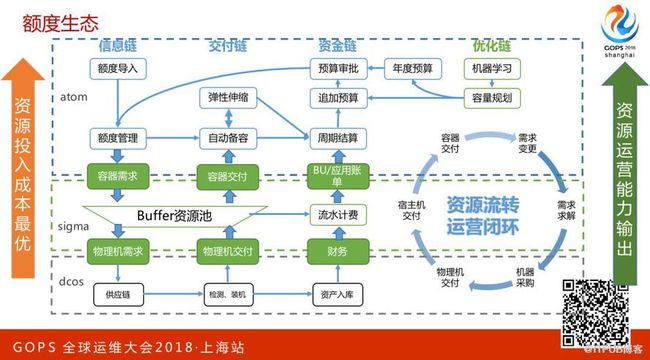
这是额度生态。在阿里巴巴内部所有的系统使用资源都会有上限,就是在某一个时期你能用的最大资源数量。这个数量我们是把他细化,你能用多少核的CPU,能用多大的磁盘空间,基于这套额度系统会整个形成系统化的闭环。
降低资源成本

其实我们做的这些系统归根到底是为了解决资源成本的压力。阿里在2014年做下一年的财政预算的时候就预见到阿里巴巴未来在基础设施的投入是非常非常难,第一年做预算的时候发现下一年要采购的机器数翻倍,这对于整个的投入是非常非常难。
这块主要挑战来自两块,一是像“双11”的场景,很多人买买买,我们要提供几十万的峰值交易能力。
还有一块是离线任务计算,也是有非常大的资源需求。像刚才提到“双11”是很麻烦的事情,在“双11”之前可能买了很多机器,“双11”用完之后大量机器就闲置,那闲置成本对于阿里来说也非常非常高昂。

基于这些我们就想说怎么样才能用最少的成本去支撑“双11”。首先想到用阿里云,比方说去年30万笔交易,我们有很大一部分都用的阿里云的资源,因为阿里云有这么大的体量。
这里面的技术难点主要是阿里集团要和阿里云体系打通,怎么样才能快速的把电商业务部署到云上去,基本上只用十几二十天撑过“双11”就可以,这样成本会大幅度下降。

第二我们想到怎么把手头机器用好。在线服务,他的CPU利用率是跑的比较低的,刚才说到只有10%,但离线计算CPU用的比较高,就想这两种服务能不能够同时去跑。比方说把离线、实时计算、在线同时跑就可以达到很高的CPU使用率。
阿里大概从2015年开始就做这块的尝试,把不同的业务做混合部署。在阿里我们基本上是这么做的,在线业务都是物理机,那离线直接在物理机上,像在日常情况下可以用在线的服务器去满足离线资源。这个技术给阿里带来了极大的成本节省,现在CPU利用率已经能够跑到很高的水位了,包括平时在线集群上只有离线任务在跑,并且离线任务对在线的影响可以控制在10%以内。
智能化运营

混部技术,平时离线可能占用大部分的资源,那需要的时候可以快速把离线任务降下去,使在线跑起来。
在线调度器与离线调度器的协同,比方说在线业务突然有流量高峰的时候,我们可能就会把离线的第一优先级任务除掉。
因为在线任务的优先级相对来说是更高的,比如说用户下单,要是超时可能就会产生投诉。另外在资源隔离这块,怎么样让在线业务他的资源有保障,因为离线任务的特点跑起来的话CPU会跑的很高,内存也会用的很快。

最后一个技术是在虚拟化做的尝试。
应用画像技术,这也是内核本身就有的,可能现在很多厂商还没有大规模的用,但阿里已经大规模的用这套技术了,就是Cpushare。
传统的容器化,如果说一个容器生成了4核的CPU,8G内存,60G的磁盘,那他的资源就是固定的,容器把资源预留住了,这些资源只能他用。这样就会造成一些应用平时的业务量没有那么大,但依然占容器,就会导致整体利用率不高。
那基于CPU下的这种模式具体说来我们把CPU拆成很多细碎的时间片,这个时间片比方说有个业务判断出他对CPU的消耗量很低,那可能只分配0.1个核给他。就会出现比方说像右边那种场景。
某个业务他可能部署的时候需要3.2个核,CPU核数用小数点来衡量,不会像现在这样全部是整数。
还有个优点我们可以给容器设置他使用资源的上限,会保证最小能够用多少资源,同时当你的系统提高时可以给更多的CPU资源,这样灵活性就会很高。
我可以做到同一台物理机上部署了两个应用,可能都是同样的规格,但有一个应用对资源的消耗很高的情况下,就可以把另外一个虚拟机分配的资源给拿过来用,这对业务的判断、识别要求非常非常高。
现在在 Cpushare 会主要做的是对应用画像。你这个系统或者业务的资源是不是能够被别人抢占的,可能你是高中低三种优先级,可能高优先级的系统就可以抢占低优先级系统的资源。前面提到的混部、CPU的技术,都是为了“双11”的时候阿里巴巴能够尽可能少的采购机器。
我的分享就到这里,谢谢大家。
问答环节
提问1:我想问一下你前面提到了节省资源,以前做运维比如说一个服务器会控制一些资源,那听说你们好像浪费率在10%以下,这时候如果一旦出现系统资源紧张,这是怎么样的?
答:首先纠正一下,前面10%这是不到10%的利用率,你的问题是说出现突发需求怎么办。
我想说的是以前运维模式是说每个BU的运维负责人手里都留了一份buffer,以备不时之需,那在我们这里也会留buffer,但这只是一个数字。
我们做了一个事情,把全集团所有的buffer全集中起来了,每个BU手里有的buffer相当于一张支票,因为所有的buffer聚集在一起他的体量是足够庞大的。在“双11”这种场景稍微有点特殊,很多人都拿着支票来说取现兑现,就像银行被挤兑一样,这种情况下我们的压力是会大一点。
提问2:杨老师您好,像资源池这块负责运维的时候,负责的界线你们是怎么确定的?就比如说像操作系统还有中间件、数据库的维护是怎么样的?
答:其实我发现今天演讲把这部分漏掉了,在阿里是这样的。我们做容器化以后会发现运维的生活质量大幅提升。
我们以前传统的运维,在做容器化之前要应对各种各样的需求,比如说今天要改个case,明天要调个什么东西,容器化以后发现他全部可以做了。
那阿里现在这几万个应用绝大部分日常的运维工作全部交给了开发,我们想说的是运维的减赋不一定是通过DevOps来实现。阿里有两万多名工程师,那每人做一点可能运维团队就非常轻松。
像你刚才提到的,比方说研发自己的系统,现在我们还是有些基础的组建,比如说像中间件、分布式存储,这部分还是有独立的团队在支持,这块的运维量远没有应用运维那么大。阿里现在相当于在用这套模式做DevOps落地。
我们的这个是从整体来看,运维转型以后做的更多是研发工作,比方说开发弹性伸缩系统。![]()

来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31555606/viewspace-2217880/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31555606/viewspace-2217880/