Python 爬取爱奇艺 52432 条数据分析谁才是《奇葩说》的焦点人物?


作者 | 罗昭成
责编 | 唐小引
出品 | CSDN(ID:CSDNNews)
五年前,《奇葩说》在爱奇艺开始播出,第一次将辩论赛引入了综艺节目。虽然专业性很强,但他们努力去凸显自己与众不同的个性,展现出自己“奇葩”的一面。每一个辩题,最后结果并不表示官方的意见,而是希望大家在看到节目过后,能够让观众朋友们思考一些以前没有考虑过的问题,让观众朋友们看到世界的多元性,而笔者作为一个日常与代码为伍的程序员,在家中写代码之时也总喜欢一边播放着。
经过 5 年的发展,奇葩说已经更新到了第五季,这一季,节目内容还是很精彩。但是很多辩论的时候,“耍无赖”好像比讲道理更能赢得观众的喜爱。生活不止有眼前苟且,还有诗和远方。节目组应该没有去干扰比赛结果,但是笔者不喜欢“耍无赖”就这么赢得比赛,因为他对“老实人”不公平。在笔者的眼中,奇葩说变了,不再是我喜欢的那个奇葩说了(以上,仅为作者个人观点)。
不管如何,奇葩说还是很精彩,每一个辩题,都值得去深入思考。在奇葩说第五季即将完结之际,笔者突发奇想,作为程序员,是不是可以换一种角度来看奇葩说?在本文中,笔者以技术手段对奇葩说官方数据进行了分析,希望能够有一点帮助。

爬取数据
奇葩说是爱奇艺独播视频,所以这一次,笔者选取官方评论数据作为资源库,来进行数据分析。
使用 Chrome 查看源代码模式,在“奇葩说”播放页面往下面滑动,有一个 get_comments 的请求,经过分析,这个接口就是获取评论数据的接口。
看一下接口地址和请求参数:
接口地址:
http://sns-comment.iqiyi.com/v3/comment/get_comments.action
参数:
"types":"time"
"business_type":"17"
"agent_type":"119"
"agent_version":"9.9.0"
"authcookie":"cookie"
"last_id": ""
"content_id": ""其中 last_id 是用来进行分页的。
使用 Python 获取数据
上面的请求使用的 GET 方式,请求代码如下:
def saveMoveInfoToFile(movieId, movieName, lastId):
url = "http://sns-comment.iqiyi.com/v3/comment/get_comments.action?"
params = {
"types":"time",
"business_type":"17",
"agent_type":"119",
"agent_version":"9.9.0",
"authcookie":"authcookie"
}
if lastId != "":
params["last_id"] = lastId
for item in params:
url = url + item + "=" + params[item] + "&"
url = url + "content_id=" + movieId
responseTxt = getMoveinfo(url)
def getMoveinfo(url):
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0",
"Accept": "application/json",
"Referer": "http://m.iqiyi.com/v_19rqriflzg.html",
"Origin": "http://m.iqiyi.com",
"Host": "sns-comment.iqiyi.com",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
"Accept-Encoding": "gzip, deflate"
}
response = session.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
请求返回的数据是 JSON ,这里笔者就不贴返回数据,直接解析存储。本处,笔者使用 SQLite3 进行数据存储。
解析数据
def parseData(movieId, movieName, htmlContent):
data = json.loads(htmlContent)['data']['comments']
lastId = "-1"
if json.dumps(data) == "[]":
return lastId
lastId = "-1"
for item in data:
originalData = json.dumps(item)
saveOriginalDataToDatabase(item["id"], movieId, movieName, originalData)
lastId = item['id']
return lastId
为了更方便后续进行数据分析,所以将拉下来的评论数据全部进行存储,防止多次去爬取数据。
数据存储在数据库中非常简单,一个简单的 insert 语句就可以搞定。代码如下:
def saveOriginalDataToDatabase(msgId, movieId, movieName, originalData):
conn = sqlite3.connect('i_can_i_bb.db')
conn.text_factory = str
cursor = conn.cursor()
ins="insert into originalData values (?,?,?,?)"
v = (movieId+ "_" + msgId, movieId, originalData, movieName)
cursor.execute(ins, v)
cursor.close()
conn.commit()
conn.close()
本次总共从爱奇艺抓取了 52432 条评论数据。

数据清洗与整理
从爱奇艺抓取的数据,并不是所有的数据我们都需要,这里,只需将我们想要的数据提取出来。
提取数据
此处将用户的个人信息、评论、评论时间、性别等数据提取出来,存储到另一张表中。后续数据分析就从新的表中拿取就可以了,处理逻辑如下:
def saveRealItem(id, originalData):
user = json.loads(originalData)
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
cursor = conn.cursor()
ins="insert into realData values (?,?,?,?,?,?,?,?)"
content = ""
if user.has_key("content"):
content = user["content"]
v = (id, content, user["userInfo"]["gender"], user["addTime"], user["userInfo"]["uname"], user["userInfo"]["uid"], user["id"], user["userInfo"]["uidType"])
cursor.execute(ins, v)
cursor.close()
conn.commit()
conn.close()
## 转换数据
if __name__ == '__main__':
conn = sqlite3.connect('i_can_i_bb.db')
conn.text_factory = str
cursor = conn.cursor()
cursor.execute("select * from originalData")
values = cursor.fetchall()
for item in values:
saveRealItem(item[0], item[2])
cursor.close()
conn.commit()
conn.close()
分析数据
在海量的数据中,我们可以分析出我们想看到的结果。为了更好的数据处理和可视化展示,笔者使用了 Pandas 和 Pyecharts 这两个库,很好用。
因爱奇艺用户数据维度有限,所以只能简单地分析性别。来综合看一下,奇葩说用户的男女比例。话不多说,先放代码:
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
data = pd.read_sql("select * from realData", conn)
genderData = data.groupby(['gender'])
rateDataCount = genderData["id"].agg([ "count"])
rateDataCount.reset_index(inplace=True)
print rateDataCount
attr = ["女", "男"]
v1 = [rateDataCount["count"][i] for i in range(0, rateDataCount.shape[0])]
pie = Pie("性别比例")
pie.add("", attr, v1, is_label_show=True)
pie.render("html/gender.html")
conn.commit()
conn.close()
使用 Pyecharts 画了一个简单的饼图:
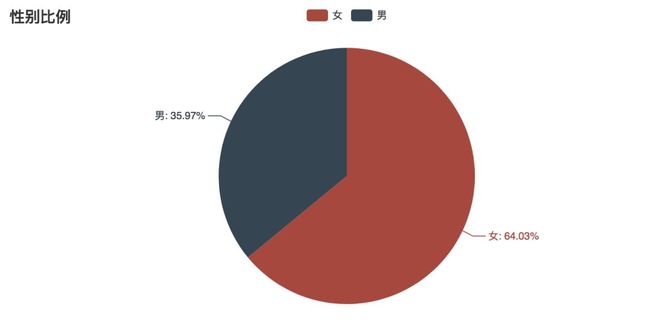
男女比例图
从图中可以看出来,男女比例差不多到 1:2,看奇葩说的女性用户,比男性用户要多很多。也许,这也是这一季奇葩说情感话题比较多的一大原因。
接下来,我们再来看一下,每一期的评论数量,看是否能够得出一些不一样的数据。
还是先上代码:
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
data = pd.read_sql("select * from realData", conn)
movieIdData = data.groupby(['movieId'])
commentDataCount = movieIdData["movieId"].agg([ "count"])
commentDataCount.reset_index(inplace=True)
print commentDataCount
movies = {
"1629260900":u"第 22 期",
"1629256800":u"第 21 期",
## 后面的数据,这里不列出来
}
attr = [movies[commentDataCount["movieId"][i]] for i in range(0, commentDataCount.shape[0])]
v1 = [commentDataCount["count"][i] for i in range(0, commentDataCount.shape[0])]
bar = Bar("评论数量")
bar.add("数量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True,is_label_show=True)
bar.render("html/comment_count.html")
conn.commit()
conn.close()
跑出来的数据如下:
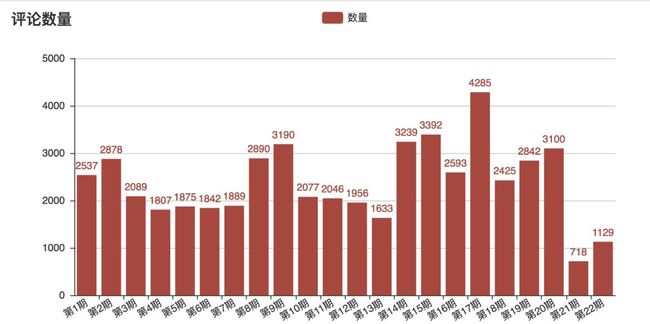
每期评论数量
从图中的数据我们可以看到,评论数量并不会因为更新早而变得更多。所以可以看出,奇葩说的用户群体是相对稳定的。不仅如此,我们也可以看出,在第 17 期评论数量比其他都要多,很有可能是这一期节目的话题更让用户关注。
分析了上面的两个数据,下面再分析一下评论时间分布,本次分析是按照星期来分析的,所以,还需要对数据进行一定的处理。将每一条评论所在星期更新到数据库中,代码如下:
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
cursor = conn.cursor()
cursor.execute("select * from realData")
values = cursor.fetchall()
cursor.close()
for item in values:
realTime = time.localtime(float(item[3]))
realTime = time.strftime("%A",realTime)
sql = "UPDATE `realData` SET `week`=\"" + realTime + "\" WHERE `id`=\"" + item[0] + "\""
cc = conn.cursor()
cc.execute(sql)
cc.close()
conn.commit()
conn.close()
time.localtime()
使用折线图分析如下:
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
data = pd.read_sql("select * from realData", conn)
movieIdData = data.groupby(['week'])
commentDataCount = movieIdData["week"].agg([ "count"])
commentDataCount.reset_index(inplace=True)
print commentDataCount
weekInfo = {
"Monday":u"周一",
"Tuesday":u"周二",
"Wednesday":u"周三",
"Thursday":u"周四",
"Friday":u"周五",
"Saturday":u"周六",
"Sunday":u"周日"
}
weeks = [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday","Sunday"
]
attr = []
v1 = []
week_temp = [commentDataCount["week"][i] for i in range(0, commentDataCount.shape[0])]
for item in weeks:
attr.append(weekInfo[item])
index = week_temp.index(item)
v1.append(commentDataCount["count"][index])
bar = Line("天评论数量")
bar.add("数量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True,is_label_show=True)
bar.render("html/comment_week_count.html")

评论周期
可以看出,奇葩说的忠实用户基本是在更新当天就看,并且周五、周六、周日的评论数量远大于其他天。其实我们还可以分析,更新当天的 4 个小时内评论量有多大,感兴趣的读者可以尝试去跑一下数据。
而作为一名程序员,笔者平时基本是不写评论的,在这里,我们特地分析了一下评论字数的分布,不看不知道,一看吓一跳。先上代码:
# 先获取评论长度,并更新到数据库中
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
cursor = conn.cursor()
cursor.execute("select * from realData")
values = cursor.fetchall()
cursor.close()
for item in values:
content = item[1]
length = 0
if len(content) <= 20:
length = 0
elif len(content) > 20 and len(content) <= 50:
length = 1
elif len(content) > 50 and len(content) <= 100:
length = 2
else:
length = 3
sql = "UPDATE `realData` SET `length`=\"" + str(length) + "\" WHERE `id`=\"" + item[0] + "\""
cc = conn.cursor()
cc.execute(sql)
cc.close()
conn.commit()
conn.close()
time.localtime()
# 获取数量并展示
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
data = pd.read_sql("select * from realData", conn)
lengthData = data.groupby(['length'])
lengthDataCount = lengthData["movieId"].agg([ "count"])
lengthDataCount.reset_index(inplace=True)
print lengthDataCount
attr = ["20 字以内", "20~50 字", "50~100 字", "100 字以上"]
v1 = [lengthDataCount["count"][i] for i in range(0, lengthDataCount.shape[0])]
bar = Line("评论字数")
bar.add("数量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=True,is_label_show=True)
bar.render("html/comment_word_count.html")
conn.commit()
conn.close()
分析结果如下:
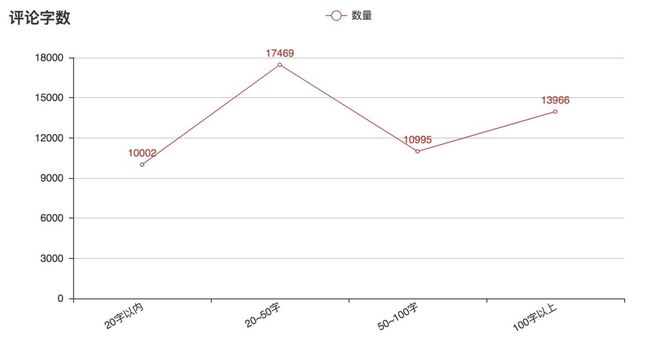
评论字数分析
实在是没有想到,100 字以上的评论居然有 1/4,在这个移动端已成视频播放主要平台的时代,用户还能够花费较多精力写下评论,笔者还是比较震惊的。
最后,笔者将通过 jieba 把评论进行分词,然后再以 wordcloud 制作词云来看看,观众朋友的整体评价:
conn = sqlite3.connect('deal_data.db')
conn.text_factory = str
data = pd.read_sql("select * from realData", conn)
jieba.add_word("马薇薇", freq = 20000, tag = None)
comment = jieba.cut(str(data["content"]),cut_all=False)
wl_space_split = " ".join(comment)
backgroudImage = np.array(Image.open(r"./qipashuo.jpg"))
stopword = STOPWORDS.copy()
wc = WordCloud(width=1920,height=1080,background_color='white',
mask=backgroudImage,
font_path="/Users/zhaocheng/Documents/Deng.ttf",
stopwords=stopword,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
plt.imshow(wc)
plt.axis("off")
wc.to_file('html/word_cloud.png')
conn.commit()
conn.close()
词云图:

词云
通过上面的词云可以很明显地看出,李诞、(薛)教授、(詹)青云、马薇薇、(傅)首尔等人物名称高频地出现在了评论里面,他们才是这部综艺的焦点人物。
本文为作者原创投稿,版权归 CSDN 所有。

微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!

CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
推荐阅读:
GitHub 的“封神”之路!
程序员如何处理被 “吃” 掉的异常?
@Python 程序员,如何实现狂拽酷炫的 3D 编程技术?
前途未卜的智能音箱,语音助手还差一个杀手级应用
程序员婚恋现状大调查:有人三十岁没谈过恋爱,有人丁克万岁
AWS Lambda重大更新,跨越编程语言差异之门?
40k~65k, 区块链架构师技能包一览: 多语言、多平台、多算法...别慌, 先投简历再说
牛!程序员女友4招拯救了我发际线!

