Federated Machine Learning学习笔记(一):综述:概念与模型
开始将mobile与AI进行靠拢了,RL,FL,DL一网打尽,先多看看survey再说。本文主要来自于Federated Machine Learning: Concept and Applications,主要介绍了使用Federated Machine Learning的原因,常用的一些概念,以及目前存在的一些应用。为了鼓励自己好好学习,决定提炼核心思想,以备不时之需。
文章结构
- 一、Why we need Federated Learning?
- 二、Overview-具体引文见paper
- 三、Federated Learning的定义
- 四、Federated Learning的私有性
- 1.常用工具
- 2.非直接信息泄露
- 五、Federated Learning的分类-根据数据分布
- 1.水平联合学习
- 2.垂直联合学习
- 3.迁移联合学习
- 六、FL系统架构
- 1.水平联合学习
- 2.垂直联合学习
- 3.迁移联合学习
- 4.激励机制
- 七、应用
一、Why we need Federated Learning?
大数据推动着AI的发展,AlphaGo使用了300000场游戏作为训练参数,才打败了人类。随着AlphaGo的胜出,人们都开始希望大数据驱动的AI技术快速的渗透到各行各业。但是真实的情况令人失望,在一些场景下,我们我们只有有限的数据或者低质量的数据,这样要训练AI模型将会很难。那我们能否跨组织传输数据,将它们集中起来进行训练,如果可以的话就可以满足大多数AI模型的需求。比如在一个AI商品推荐的模型里,商家只有用户是否购买和商品的信息,但是没有可以描述用户支付行为习惯,购买习惯的信息,在大多数行业里,信息像孤岛一样被个人所拥有,而且出于商业竞争、信息隐私等方面的考虑,我们很难主观的把这些信息收集起来。
同时,当下信息安全与隐私受到了前所未有的关注。欧盟发布了General Data Protection Regulation (GDPR) 专门用来保护用户的信息安全。中美也先后出台了相应的政策,对于AI而言,这并不是一件好事,数据的搜集又增加了新的挑战。
传统的数据处理模型由三部分组成,第一部分收集数据并将数据传输到第二部分。第二部分清洗并组合数据,最后,第三部分使用完整的数据进行模型的训练,这个模型通常是最后用来使用的服务。传统的模型因为当下的情况受到了严峻的挑战–数据都在一个个孤岛上,但是我们被禁止去采集和传送数据。如何合法的解决数据碎片化和数据之间的隔离是一个主要的挑战。
federated learning是一个可能的解决方案。同时federated learning的兴起,显示了这一批科学家的希望:将AI发展的重心从改善模型表现到发现新的数据集成方法,真正解决AI本质的需求。
二、Overview-具体引文见paper
Federated Learning的概念最先源自于Google,他们最先提出了在分布式的数据集上建立机器学习框架,同时保证信息不会泄露。后来开始专注于克服数据在统计上的挑战,并提升FL的安全性。到目前为止,大量的工作与mobile-user有关,聚焦于减少数据通信的花费和提高服务的质量,因为这些数据分布很散,不平衡。
三、Federated Learning的定义

四、Federated Learning的私有性
私有性是联合学习的重要属性,这要求我们必须提供安全的模型和对私有性保证的理论分析。简单介绍并比较几种常用的保证私有性的工具,和一些防止信息间接泄露的方法。
1.常用工具
(1)Secure Multiparty Computation(SMC)
SMC模型很多参与者,并且提供扎实的理论证明,可以保证信息零泄漏。但是信息零泄漏的代价就是需要很多复杂的协议,计算效率很高。而算力是宝贵的资源,因此大量的工作会在信息泄露和计算效率上做一个折中。
(2)Differential Privacy
给数据加噪音,或者使用一般的方法给敏感数据加密直到第三方无法识别,恢复这些数据。但是这方法的根本还是在于干扰数据传输的过程,只要数据会传输,一般都要在隐私和计算效率上做一个折中。
(3)Homomorphic Encryption.
俗称同态加密,在机器学习期间通过加密机制下的参数交换来保护用户数据隐私。与之相对的概念是differential privacy protection,差异隐私保护,与差异隐私保护不统,在同态加密中,数据和模型根本不会被被发送,并且不能从其他部分数据中预测另一人的数据。这样原始的数据很难发生泄漏,
2.非直接信息泄露
所谓非直接的信息泄露,不是在数据传输时发生的。而是在类似于参数更新时发生的,比如随机梯度下降的过程中,如果数据被人恶意接受,那么你的数据,数据结构等很可能会一并泄露。该类的工作一般都在研究或者发现模型训练时一些不安全的漏洞,并对此做出优化。
五、Federated Learning的分类-根据数据分布
数据主体的特征空间和样本空间可能并不相同,我们根据特征和样本空间中各方之间的数据分配方式,将联合学习分为水平联合学习,垂直联合学习和联合转移学习。
1.水平联合学习
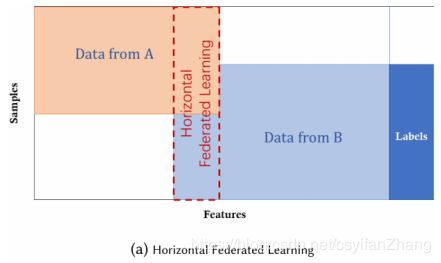
又称为基于采样的联合学习,图中可以看出数据集共享特征空间但是样本空间不同。以银行为例,两个银行的用户群体可能差异很大,他们的交集很小,但是他们的工作非常的类似,也就是特征空间类似。最有名的是google在2017年提出的面向Android系统参数更新的水平联合学习,使用Android手机的单个用户会在本地更新模型参数,并将参数上传到Android云,从而与其他数据所有者一起共同训练集中式模型。
水平联合学习一般都会假设参与者和服务端都是诚实的,但是服务端对数据比较好奇,也就是说只有服务端会造成信息的泄露。他在保证数据安全的情况下,聚合不同的样本进行训练。
2.垂直联合学习
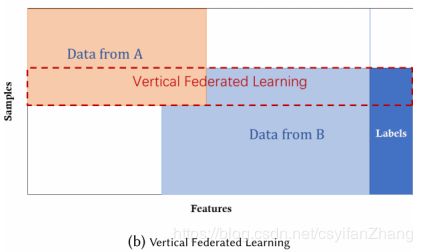
也叫作基于特征的联合学习,样本空间重叠,但是特征空间不同。比如一个城市中的两个公司,一个商业公司一个银行,商业公司的用户大多有银行卡,二者的用户空间十分重叠,但是二者记录的用户特征是不一样的,商业公司存储的大多是用户的消费习惯,消费记录。而银行对用户的存款,年利率等信息比较了解。他们的特征空间差距非常大,而我们希望即考虑用户的自己能力和消费历史来对用户进行推荐,此时就需要使用垂直联合学习。
垂直联合学习是聚合这些不同特征并以保护隐私的方式计算训练损失和梯度的过程,以使用双方的数据共同构建模型。
3.迁移联合学习

如果数据的样本空间,特征空间全部都不一样,那么就需要迁移学习了。比如一个中国的银行和一个外国的电商公司,无论是用户还是拥有的数据类型,二者都是差异极大的。使用有限的公共样本集学习两个特征空间之间的公共表示,然后将其应用于获得仅具有一侧特征的样本的预测。 FTL是现有联合学习系统的重要扩展,因为它处理的问题超出了现有联合学习算法的范围
六、FL系统架构
横向纵向联合学习的架构是完全不同的。
1.水平联合学习
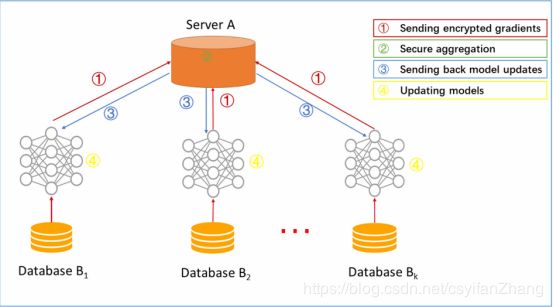
k个数据结构完全相同的用户(特征空间基本相同)参数或云服务器的帮助下共同学习了机器学习模型。 一个典型的假设是,参与者是诚实的,而服务器是诚实但好奇的。 因此,不允许任何参与者向服务器泄漏信息。 这种系统的训练过程通常包括图中四个步骤。
①参与者本地计算梯度,使用加密,差分隐私或秘密共享技术掩盖梯度的选择; 并将屏蔽的结果发送到服务器。
②服务器执行安全聚合,而无需学习有关任何参与者的信息。
③服务器将汇总结果返回给单个用户
④参与者使用解密的梯度更新它们各自的模型。
显然训练结束后,所有的参与者共享模型参数。
2.垂直联合学习
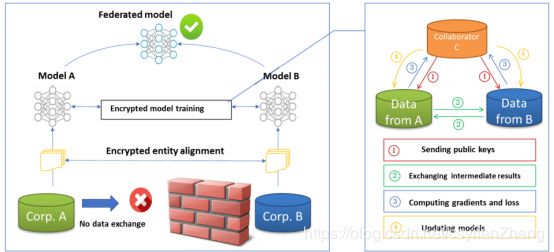
假设公司A和B想联合训练一个机器学习模型,并且他们的业务系统各有自己的数据。此外,公司B也有模型需要预测的标签数据。出于数据隐私和安全原因,甲乙双方不能直接交换数据。为了在培训过程中确保数据的机密性,需要一个第三方合作者C。在这里,我们假设合作者丙是诚实的,没有与甲或乙串通,但甲和乙是诚实的,但彼此好奇。可信的第三方C是一个合理的假设,因为C方可以由政府之类的权威机构扮演,也可以由安全计算节点取代。联合学习系统由两部分组成。
Part 1(Encrypted entity alignment):由于是要聚合不同的特征,因此先要使用加密的用户ID在保证用户信息不泄露的情况下,对齐用户的数据,也就是公共用户的部分。
Part 2(Encrypted model training):确认了公共实体之后,我们使用这些公共实体的数据对模型进行训练。
① 合作者C创建加密对并将公钥发送给A和B。
② A和B加密并交换中间结果以进行梯度和损耗计算。
③ A和B分别计算加密的梯度并添加额外的掩码。B还计算加密损失。A和B向C发送加密值。
④ C将加密的梯度和损失解密并发送回A和B。A和B取消梯度的屏蔽并相应地更新模型参数
3.迁移联合学习
迁移联合学习和垂直联合学习的架构大致不差,但是在A,B交换中间结果的细节方面有所改变。具体而言,迁移学习通常涉及学习甲乙双方特征之间的共同表示。
4.激励机制
类似于这种需要大量人或者公司贡献数据的地方,都可以称之为群智感知,crowdsourcing(别问我为啥我就是搞这个的),在平台里我们必须有足够的奖励给到公司,才能够激励越来越多的公司贡献数据,所有激励方式的设计尤为重要。
七、应用
以智能零售为例。其目的是使用机器学习技术为客户提供个性化服务,主要包括产品推荐和销售服务。智能零售业务涉及的数据特征主要包括用户购买力,用户个人喜好和产品特征。在实际应用中,这三个数据特征可能分散在三个不同的部门或企业中。例如,可以从用户的银行储蓄中推断出用户的购买力,并可以从用户的社交网络中分析个人喜好,而产品的特征则由电子商店记录。在这种情况下,我们面临两个问题。首先,为了保护数据隐私和数据安全,很难打破银行,社交网站和电子购物网站之间的数据障碍。结果,数据不能直接聚合以训练模型。其次,三方存储的数据通常是异类的,传统的机器学习模型不能直接在异类数据上工作。目前,这些问题尚未通过传统的机器学习方法得到有效解决,这阻碍了AI在更多领域的普及和应用。
联合学习和迁移学习是解决这些问题的关键。首先,通过利用联合学习的特征,我们可以为三方建立机器学习模型而无需导出企业数据,这不仅可以充分保护数据隐私和数据安全,还可以为客户提供个性化和针对性的服务,从而实现互惠互利。同时,我们可以利用转移学习来解决数据异质性问题,并突破传统AI技术的局限性。因此,联合学习为我们为大数据和AI建立跨企业,跨数据和跨域生态圈提供了良好的技术支持