避免神经网络过拟合的5种技术(附链接) | CSDN博文精选

作者 | Abhinav Sagar
翻译 | 陈超
校对 | 王琦
来源 | 数据派THU(ID:DatapiTHU)
(*点击阅读原文,查看作者更多精彩文章)
本文介绍了5种在训练神经网络中避免过拟合的技术。
最近一年我一直致力于深度学习领域。这段时间里,我使用过很多神经网络,比如卷积神经网络、循环神经网络、自编码器等等。我遇到的最常见的一个问题就是在训练时,深度神经网络会过拟合。
当模型试着预测噪声较多的数据的趋势时,由于模型参数过多、过于复杂,就会导致过拟合。过拟合的模型通常是不精确的,因为这样的预测趋势并不会反映数据的真实情况。我们可以通过模型在已知的数据(训练集)中有好的预测结果,但在未知的数据(测试集)中较差的表现来判断是否存在过拟合。机器学习模型的目的是从训练集到该问题领域的任何数据集上均有泛化的较好表现,因为我们希望模型能够预测未知的数据。
在本文中,我将展示5种在训练神经网络时避免过拟合的技术。
一、简化模型
处理过拟合的第一步就是降低模型复杂度。为了降低复杂度,我们可以简单地移除层或者减少神经元的数量使得网络规模变小。与此同时,计算神经网络中不同层的输入和输出维度也十分重要。虽然移除层的数量或神经网络的规模并无通用的规定,但如果你的神经网络发生了过拟合,就尝试缩小它的规模。
二、早停
在使用迭代的方法(例如梯度下降)来训练模型时,早停是一种正则化的形式。因为所有的神经网络都是通过梯度下降的方法来学习的,所以早停是一种适用于所有问题的通用技术。使用这种方法来更新模型以便其在每次迭代时能更好地适应训练集。在一定程度上,这种方法可以改善模型在测试集上的表现。但是除此之外,改善模型对训练集的拟合会增加泛化误差。早停规则指定了模型在过拟合之前可以迭代的次数。

早停
上图展示了这种技术。正如我们看到的,在几次迭代后,即使训练误差仍然在减少,但测验误差已经开始增加了。
三、使用数据增强
在神经网络中,数据增强只意味着增加数据规模,也就是增加数据集里中图像的数量。一些热门的图像增强技术有翻转、平移、旋转、缩放、改变亮度、添加噪声等等。获取更全面的参考,可访问:
Albumentations:
https://github.com/albumentations-team/albumentations
Imgaug:
https://github.com/aleju/imgaug
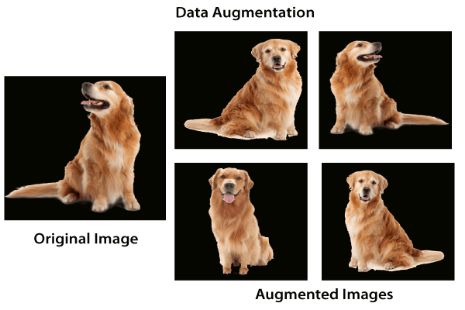
数据增强
如上图所示,使用数据增强可以生成多幅相似图像。这可以帮助我们增加数据集规模从而减少过拟合。因为随着数据量的增加,模型无法过拟合所有样本,因此不得不进行泛化。
四、使用正则化
正则化是一种降低模型复杂度的方式。它是通过在损失函数中添加一个惩罚项来实现正则化。最常见的技术是L1和L2正则化:
L1惩罚项的目的是使权重绝对值最小化。公式如下:
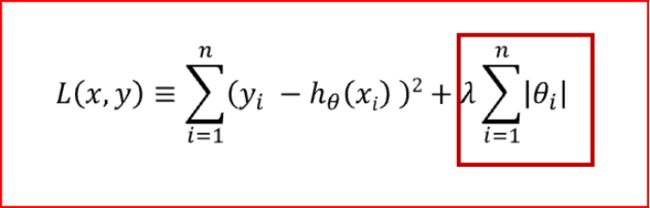 L1正则化
L1正则化
L2惩罚项的目的是使权重的平方最小化。公式如下:
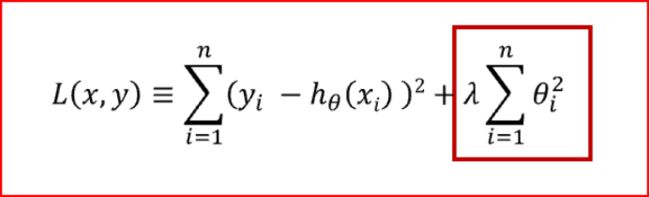
L2正则化
以下表格对两种正则化方法进行了对比。
L1正则化 |
L2正则化 |
1. L1惩罚权重绝对值的总和 |
1. L2惩罚权重平方和的总和 |
2. L1生成简单、可解释的模型 |
2. L2正则化能够学习复杂数据模式 |
3. L1受极端值影响较小 |
3. L2受极端值影响较大 |
L1正则化vs L2正则化
那么哪一种方式更有利于避免过拟合呢?答案是——看情况。如果数据过于复杂以至于无法准确地建模,那么L2是更好的选择,因为它能够学习数据中呈现的内在模式。而当数据足够简单,可以精确建模的话,L1更合适。对于我遇到的大多数计算机视觉问题,L2正则化几乎总是可以给出更好的结果。然而L1不容易受到离群值的影响。所以正确的正则化选项取决于我们想要解决的问题。
五、使用丢弃法(Dropouts)
丢弃法是一种避免神经网络过拟合的正则化技术。像L1和L2这样的正则化技术通过修改代价函数来减少过拟合。而丢弃法修改神经网络本身。它在训练的每一次迭代过程中随机地丢弃神经网络中的神经元。当我们丢弃不同神经元集合的时候,就等同于训练不同的神经网络。不同的神经网络会以不同的方式发生过拟合,所以丢弃的净效应将会减少过拟合的发生。
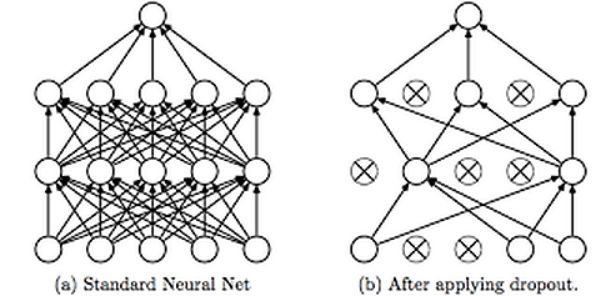
使用丢弃法
如上图所示,丢弃法被用于在训练神经网络的过程中随机丢弃神经网络中的神经元。这种技术被证明可以减少很多问题的过拟合,这些问题包括图像分类、图像切割、词嵌入、语义匹配等问题。
结论
简单回顾下上述内容,我解释了什么是过拟合以及为什么它是神经网络当中常见的问题。接下来我又给出了五种最常见的在训练神经网络过程中避免过拟合的方法——简化模型、早停、数据增强、正则化以及丢弃法。
编辑:黄继彦
校对:林亦霖
技术的道路一个人走着极为艰难?
一身的本领得不施展?
优质的文章得不到曝光?
别担心,
即刻起,CSDN 将为你带来创新创造创变展现的大舞台,
扫描下方二维码,欢迎加入 CSDN 「原力计划」!

◆
精彩公开课
◆

推荐阅读
滴滴开源在2019:十大重点项目盘点,DoKit客户端研发助手首破1万Star
你的 App 在 iOS 13 上被卡死了吗
Hinton、吴恩达们也“吹牛”炒作?媒体和研究人员共谋,AI圈误导信息泛滥
通向人工智能产业落地化的道路在哪?
为什么我们最终抛弃 Chromium 选择了 Firefox ?
如何用Redis实现微博关注关系?
扎心了!互联网公司福利缩水指南
“对不起,我们只招有出色背景的技术人员!”
不用失去控制权和所有权,也能在区块链中通过数据共享获得奖励?

你点的每个“在看”,我都认真当成了AI