JAVA BIO体系学习
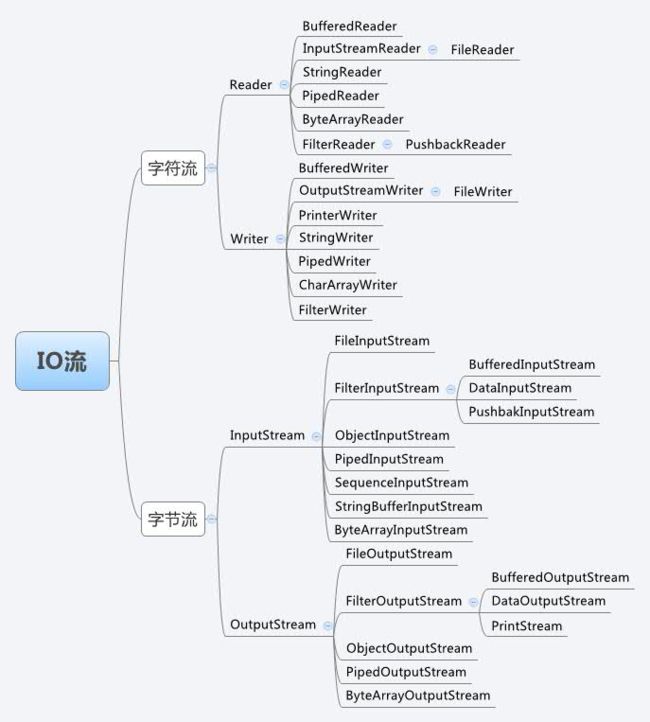
2. JAVA BIO总结
2.1 IO流的分类
按照不同的分类方式,可以将流分成不同的类型。常用的分类有三种。
- 按照流的流向:输出流和输入流;
- 按照操作单元:字节流和字符流;
- 按照角色划分:节点流和处理流;
2.1.1 按照流的流向,分为输入流和输出流
因为流是单向的,所以出现了输入流和输出流。
- 输入流:只能从流中
读取数据,而不能向流中写入数据。 - 输出流:只能向流中
写入数据,而不能从流中读取数据。
参考系不同,输入流和输出流概念容易混乱:首先我们是站在
JVM的角度的。
- 输入流:数据输入到
JVM中,JVM只能读取呀;- 输出流:数据要从
JVM输出,JVM只能写入呀;
如图15.1所示,数据从内存流入硬盘,通常被称为 输出流 。

如图15.2所示,数据从服务器通过网络流入客户端,这种情况下,服务器JVM将数据输出到网络中,即为输出流;客户端将数据从网络输入到JVM中,即为输入流;
在Java中,输入流主要是InputStream和Reader作为基类,而输出流则是由OutputStream和Writer作为基类。他们都是一些抽象基类,无法之间创建实例。
2.1.2 按照操作单元划分,分为字节流和字符流
字节流主要是由
InputStream和OutputStream作为基类,而字符流则主要有Reader和Writer作为基类。
字节流和字符流的用法几乎完全一样,区别就是字节流和字符流所操作的数据单元不同,字节流操作的单元是字节(占8bit),字符流操作的数据单元是字符(占16bit)。
2.1.3 按照流的角色划分,分为节点流和处理流。
向一个特定的IO设备(磁盘,网络)读/写数据的流,称为节点流。也称为低级流
处理流:则用于对一个已存在的流进行连接和封装,通过封装后的流来实现数据的读/写功能,如BufferedReader,处理流的构造方法总是要带一个其他流对象做参数。一个流对象经过其他流的多次包装,称为流的连接。
如图15.3所示,当使用节点流进行输入/输出时,程序直连到实际的数据源。
如图15.4所示,当使用处理流进行输/和输出时,程序不会直接连接到实际的数据源,处理流可以“嫁接”到任何已存在流的基础上。使用处理流的明细好处就是:程序可以使用完全相同的输入代码/输出代码来访问不同的数据源。

2.2 IO流原理分析以及分类
2.2.1 IO流的原理浅析
对于输入流InputStream和Reader而言,可以将输入设备抽象成一个”水管“,数据就像”水滴“,如图所示:

输入流就是将数据输入到JVM(内存)中。字节流和字符流就是处理单位不同,但是处理方式是类型的。
输入流使用“隐式”的记录指针来表示当前正准备从哪个“水滴”开始读取,每当程序从InputStream或Reader里面取出一个或多个“水滴”后,记录指针就向后移动。
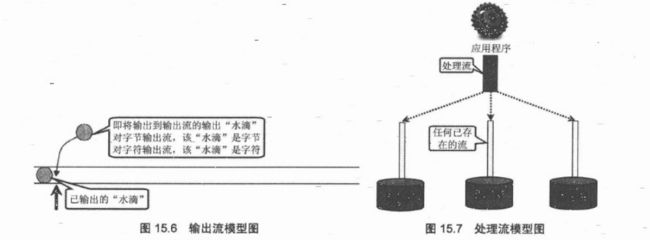
对于OutputStream和Writer而言,同样把输出设备抽象成一个“水管”,只是里面没有任何水滴。
图15.5和图15.6 显示了Java IO的基本概念模型。
处理流的功能主要体现在两个方面:
- 性能提高:主要是增加缓冲的方式来提高输入和输出效率。
- 操作便捷:处理流可以“嫁接”到任何已经存在的流的基础上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的数据流。
2.2.2 BIO常用流的分类表
JAVA BIO流共涉及40多个类,看上去很是繁杂,但是实际上都有规则,都是在如下4个抽象基类中派生出来的。
InputStream字节输入流,Reader字符输入流;OutputStream字节输出流,Writer字符输出流;
- 表中粗体类:表示节点流,必须和物理节点相连。
- 表中斜体类:表示抽象基类,无法直接创建实例。
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 访问管道 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 抽象基类 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
2.3 常用BIO的用法
2.3.1 BIO体系的基类
InputStream/Reader,OutputStream/Writer是输入/输出流的基类,虽然本身不能创建实例来执行输入,但是他们是BIO所有类的父类。
2.3.1.1. InputStream和Reader是所有输入流的基类
1. InputStream 读数据相关方法
从输入流读取数据的下一个字节。 值字节被返回作为int范围0至255 。
如果没有字节可用,因为已经到达流的末尾,则返回值-1 。
该方法阻塞直到输入数据可用,检测到流的结尾,或抛出异常。
public abstract int read() throws IOException
从输入流读取一些字节数,并将它们存储到缓冲区b 。
实际读取的字节数作为整数返回。
该方法阻塞直到输入数据可用,检测到文件结束(返回-1)或抛出异常。
public int read(byte[] b) throws IOException
从输入流读取len字节的数据到一个字节数组。
尝试读取多达len个字节,但可以读取较小的数字。
实际读取的字节数作为整数返回。文件末尾返回-1
public int read(byte[] b,int off,int len) throws IOException
2. Reader 中读数据相关方法
方法基本和InputStream相同,只是读取是一个字符。
public int read() throws IOException
public int read(char[] cbuf) throws IOException
public abstract int read(char[] cbuf, int off,int len) throws IOException
3. InputStream和Reader提供了一些指针移动的方法
标记此输入流中的当前位置。对reset方法的后续调用会将
该流重新定位在最后一个标记的位置,以便后续读取重新读取相同的字节。
readlimit - 标记位置无效之前可以读取的最大字节数。
public void mark(int readlimit)
测试这个输入流是否支持mark和reset方法。
public boolean markSupported()
将此流重新定位到上次在此输入流上调用mark方法时的位置。
public void reset() throws IOException
跳过并丢弃来自此输入流的n字节数据。
public long skip(long n) throws IOException
2.3.1.2. OutputStream和Writer是所有输出流的基类
OutputStream和Writer用法也非常相似。对于输出数据。提供了下面这三个方法。
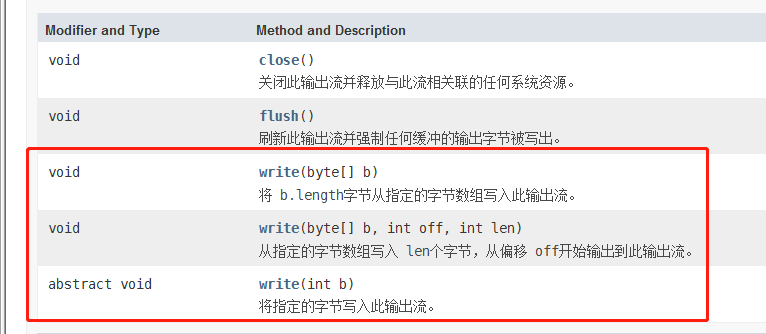
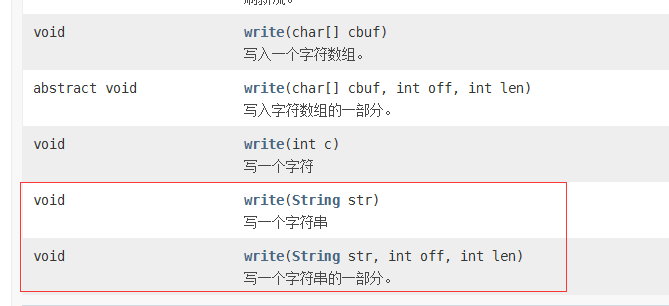
需要注意的是,因为字符流是直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组。即String类型作为参数输出。
2.3.2 BIO体系的文件流的使用
前面谈过,
InputStream/Reader、OutputStream/Writer都是抽象类,本是是不能创建实例的,但是它们分别有一个用于读取文件的输入(出)流FileInputStream/FileReader、FileOutputStream/FileWriter,他们都是节点流——直接会和指定文件关联。
使用InputStream将数据读取到JVM中。
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("D:\\11\\BIO.txt");
byte[] b = new byte[1024];
int hasRead = 0; //fis.read(byte[])返回的数组字节长度
while ((hasRead = fis.read(b)) > 0) { //将字节读取到Byte中
System.out.println("hasRead:"+hasRead);
System.out.println(new String(b, 0, hasRead));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
使用FileReader读取数据到JVM中:
public static void main(String[] args) throws IOException {
//使用FileReader读取文件
FileReader fileReader = null;
//使用节点流直接读取物理设备上的数据
try {
fileReader = new FileReader(new File("D://11/BIO.txt"));
char[] chars = new char[40];
//最后一个次数组的长度
int charRead = 0;
while ((charRead = fileReader.read(chars)) > 0) {
System.out.println(new String(chars, 0, charRead));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
fileReader.close();
}
}
上面的程序最后使用了
close()方法显示的关闭了文件输入流。Java7改写了所有的IO资源库,他们都实现了AntoCloseable接口,因此都可以通过自动关闭的try语句关闭这些IO流。AntoCloseable接口——我们不需要在finally块手动释放资源,无论成功执行还是抛出异常,try中都会关闭资源。
FileOutputStream和FileWriter是IO的文件输出流,将JVM上的数据输出到文件上
JVM写到文件上:
public static void main(String[] args) throws IOException {
//使用FileReader读取文件
FileReader fileReader = null;
FileWriter fileWriter = null;
try {
fileReader = new FileReader(new File("D://11/BIO.txt"));
fileWriter = new FileWriter("BIO.txt");
char[] chars = new char[40];
//最后一个次数组的长度
int charRead = 0;
while ((charRead = fileReader.read(chars)) > 0) {
//JVM写到硬件上
fileWriter.write(chars, 0, charRead);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
fileReader.close();
fileWriter.close();
}
}
需要注意的是
close()方法不仅可以保证流的物理资源被回收外,还可以将缓冲区中的数据flush到物理节点中。(因为在执行close()方法前,自动执行输出流的flush()方法)。
2.3.3 BIO体系的处理流Buffered流的使用
处理流中的缓冲流
BufferedInputStream/BufferedReader、BufferedOutputStream/BufferedWriter作为处理流中的缓冲流。
小胖:上面的
read(byte[] bufBytes);就是缓冲区呀,BufferedInputStream也是缓冲区。他们之间有什么区别。
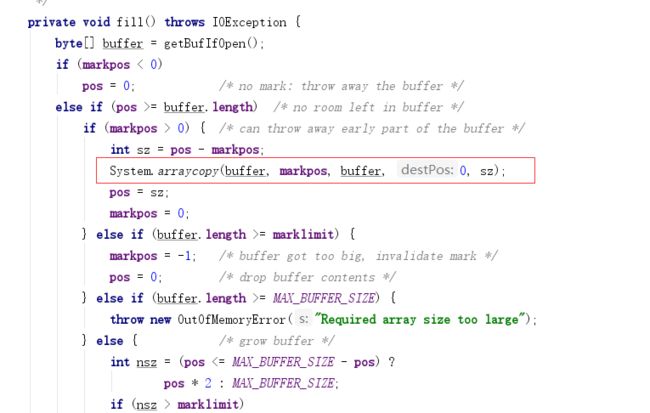
进行系统调用是耗时操作,但是无论读取多少数据,每次读取消耗的时间都几乎相等,所以读取等量数据时,使用缓冲区可以减少系统调用的次数,从而减少调用时间。
而BufferedInputStream中执行了
System.arraycopy()方法,将自定义的bye[]数组数据(自定义大小:1KB)复制到Buffer区(默认大小:8KB)。每次系统交互读取Buffered区的数据。
使用处理流BufferedXXX处理数据:
public static void main(String[] args) throws IOException {
//使用FileReader读取文件
BufferedReader fileReader = null;
// BufferedInputStream
BufferedWriter fileWriter = null;
try {
fileReader = new BufferedReader(new FileReader(new File("D://11/BIO.txt")));
fileWriter = new BufferedWriter(new FileWriter("BIO.txt"));
char[] chars = new char[40];
//最后一个次数组的长度
int charRead = 0;
while ((charRead = fileReader.read(chars)) > 0) {
//JVM写到硬件上
fileWriter.write(chars, 0, charRead);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
fileReader.close();
fileWriter.close();
}
}
需要注意的是:在上面的代码中,我们使用了
缓存流和文件流。处理流在套接到节点流上使用的时候,只需要关闭最上层的处理即可。JAVA会自动帮我们关闭下层的节点流。
2.3.4 BIO体系的转换流的使用
首先
转换流(InputStreamReader/OutputStreamReader)是处理流,可以将字节流转换字符流。

public static void main(String[] args) throws IOException {
// public final static InputStream in = null;
InputStream in = System.in;
//InputStream 转换为 Reader子类对象
InputStreamReader reader = new InputStreamReader(System.in);
//包装Buffered对象
BufferedReader bufferedReader = new BufferedReader(reader);
//将数据读入到String中
String str = null;
while ((str = bufferedReader.readLine()) != null) {
System.exit(1);
}
System.out.println("输入内容:"+str);
}
}
上面将
InputStream转换成Reader,然后在使用BufferedReader进行包装。BufferedReader具有缓存的功能,它可以一次读取一行文本,以换行符为标志。运行上面程序可以发现这个特征,当我们在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
2.3.4 BIO体系的对象流的使用
对象流(
ObjectInputStream/ObjectOutputStream)用于实现Serializable接口对象的序列化和反序列化。注意,也是一个处理流。
将内存中对象输出到文本:
public static void main(String[] args) throws IOException {
User user = new User();
user.setDate(LocalDate.now());
user.setName("tom");
//对象持久化到文本
FileOutputStream fileOutputStream = null;
BufferedOutputStream bufferedOutputStream = null;
ObjectOutputStream objectOutputStream = null;
try {
fileOutputStream = new FileOutputStream("user.txt");
bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
//使用ObjectOutputStream包装
objectOutputStream = new ObjectOutputStream(bufferedOutputStream);
objectOutputStream.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
} finally {
objectOutputStream.close();
}
}
将文件中对象输入到内存:
public static void main(String[] args) {
//将文件读入到内存中
try {
InputStream inputStream = new FileInputStream("user.txt");
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
ObjectInputStream objectInputStream = new ObjectInputStream(bufferedInputStream);
User readObject = (User)objectInputStream.readObject();
System.out.println(readObject);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
2.3.5 ByteArrayInputStream和ByteArrayOutputStream的作用
对于要创建临时性文件的程序以及网络数据的传输,数据压缩后的传输等可以提高运行的效率,可以不用访问磁盘。
流的来源或者目的地不一定是文件,也可以是内存中的一块空间,例如一个字节数组。
java.io.ByteArrayInputStream和java.io.ByteArrayOutputStream就是将字节数组当做流输入来源、输出目的地的类。
例如:
有时候我们需要对同一个InputStream对象使用多次。比如,客户端从服务器获取数据,利用HttpURLConnection的getInputStream()方法获取Stream对象,这时即要把数据显示到前台(第一次读取),又要把数据写进文件缓存到本地(第二次读取)。
但是第一次读取InputStream对象后,第二次读取时可能已经到了Stream的结尾(EOFException)或者Stream已经close掉了。
关键是我不想再次访问持久化后磁盘,获取数据。
解决:
而InputStream对象本身不能复制,因为它没有实现Cloneable接口。此时,可以先把InputStream转化成ByteArrayOutputStream,后来要使用InputStream对象时,再从ByteArrayOutputStream转化回来即可。
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5 * 1000);
//通过输入流获取图片信息
InputStream is = conn.getInputStream();
//将字节数组当做输出的目的地
ByteArrayOutputStream os = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) > -1) {
os.write(buffer, 0, len);
}
os.flush();
byte[] bytes = os.toByteArray();
//显示到前台
ByteArrayInputStream stream1 = new ByteArrayInputStream(bytes);
//TODO
//保存到内存
ByteArrayInputStream stream2 = new ByteArrayInputStream(bytes);
//TODO
BufferedOutputStream 和 ByteArrayOutputStream的区别
1. BufferedOutputStream是一个缓冲数据输出接口
BufferedOutputStream会首先创建一个默认的容器量,capacity=8192=8KB,每次在写的时候都会去比对capacity是否够用,如果不够用的时候,就flushBuffer(),把buf中的数据写入对应的outputStream中,然后将buf清空,一直这样等到把内容写完。在这个过程中主要起到了一个缓冲的功能。
BufferedOutputStream源码:
1 public synchronized void write(byte b[], int off, int len) throws IOException {
2 // 在这判断需要写的数据长度是否已经超出容器的长度了,如果超出则直接写到相应的outputStream中,并清空缓冲区
3 if (len >= buf.length) {
4 flushBuffer();
5 out.write(b, off, len);
6 return;
7 }
8 // 判断缓冲区剩余的容量是否还够写入当前len的内容,如果不够则清空缓冲区
9 if (len > buf.length - count) {
10 flushBuffer();
11 }
12 // 将要写的数据先放入内存中,等待数据达到了缓冲区的长度后,再写到相应的outputStream中
13 System.arraycopy(b, off, buf, count, len);
14 count += len;
15 }
flushBuffer()方法源码:
private void flushBuffer() throws IOException {
if (count > 0) {
// 把写入内存中的数据写到构造方法里传入的OutputStream句柄里, 并把容量大小清楚
out.write(buf, 0, count);
count = 0;
}
}
于是将Buffered里面的数据写入到目标地址中。这样不仅会减少系统交互时间,并且可以节省大量内存。因为使用的是一个Buffered区。
2. ByteArrayOutputStream则是字节数组输出接口。
普通的OutputStream,例如ByteArrayOutputStream也会首先创建一个默认的容器量,capacity=32=32b,每次在写的时候都会比对capacity是否还够用,如果不够用的时候,就重写创建buf的容量,一直到内容写完为止。这些内容都会一直处于内存中。
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
// 不断对自己的容量进行相加
int newcount = count + len;
// 如果新的容量大小已经超过了现有的大小时,则重新开辟新的内存区域来保存当前的数据
if (newcount > buf.length) {
buf = Arrays.copyOf(buf, Math.max(buf.length << 1, newcount));
}
System.arraycopy(b, off, buf, count, len);
//数据扩容
count = newcount;
}
当你资源不足够用时,选择BufferedOutputStream是最佳的选择, 当你选择快速完成一个作业时,可以选择ByteArrayOutputStream之类的输出流。
3. 如何在开发中使用BIO
- 如果操作二进制文件,那么就使用字节流,若是是操作文本文件,那么使用字符流。
- 尽可能使用处理流,这样会使得代码更加灵活,复用性更好。
JavaIO流原理之常用字节流和字符流详解以及Buffered高效的原理
Linux 内核空间与用户空间实现与分析
java IO体系的学习总结
ByteArrayInputStream的作用,和BufferedOutputStream 的区别
相关文章
IO学习(1)Java-BIO体系学习
IO学习(2)-各种IO模型
IO学习(3)— IO和NIO的区别
IO学习(4)— select、poll、epoll的区别