本系列意在长期连载分享,内容上可能也会有所增删改减;
因此如果转载,请务必保留源地址,非常感谢!
知乎专栏:https://zhuanlan.zhihu.com/data-miner
博客园:http://www.cnblogs.com/data-miner(暂时公式显示有问题)
当我们在谈论kmeans:数据概述
引言
当希望快速了解或回顾某些算法的发展时,一般而言,大家都会选择阅读综述性文章,然后有选择性的阅读部分论文。而这种高效率的做法的负面,就是比较无趣的体验,毕竟一直都行走在别人规划好的思路中,总感觉少了点趣味性。
此系列文章一方面旨在借助数据分析,回顾一些算法的历史演变轨迹,以及挖掘一些有趣的信息;同时,尽量对算法进行较为全面的总结,加深对算法的认识。
作为热身,本文先从最基本的机器学习算法之一,K-means开始。
内容包括如下几个部分:
- 数据概述:抓取K-means论文相关数据,并进行初步分析
- 论文概述:阅读K-means相关论文,对其内容进行简要描述
- 其他聚类算法:阅读其他聚类算法论文,对其内容进行简要描述
- K-means总结:对K-means相关性质进行总结
数据准备
从IEEE上抓取“标题或摘要中含有kmeans或相关关键词的论文”的部分公开信息,对于现在已有的信息,我关注的主要是title、authors、keywords、abstract、publicationYear、isConference(是否是会议文章)。抓取到数据后,将数据存入mongodb,后续使用python+jupyter来分析。
受限于抓取难度,以及本人初步的爬虫水平,并没有抓reference,这对接下来的数据挖掘是一个遗憾。若有同学比较擅长爬虫,欢迎私信或留言交流!(IEEE的网站说明里声明禁止爬虫,因此政治正确上最好是不要去爬的,此处也不讨论具体的技术细节)
数据总览
论文数量
1969-2016年,每年IEEE收录关于kmeans的论文数量如下图。其中蓝色表示当年总文章数量,绿色表示当年期刊论文数量,红色表示当年会议文章数量。 
从图中可以得出以下几点结论:
1.1990年以前,kmeans相关文章很少,多的时候每年出版的总文章数量是1,少的时候则没有任何相关文章出版;90年代作为明显的过渡期,其之前与之后论文数量与趋势的变化是翻天覆地的;
2.会议文章占了总文章数量的绝大多数:在抓取的6000多篇文章中,会议文章总5476篇,而期刊数量540篇,只有会议文章的1/10;而每年的会议文章跟期刊文章的比值也差不多这个数;
3.kmeans相关会议文章数量在2005-2010和2013-2015几年间出现了爆炸性的增长;却在2010-2011以及2015-2016出现了大幅下跌;
4.kmeans期刊文章数量在1990-2012年增长较为平稳,而在2012-2016年出现了连续4年的高速增长。
论文数量的变化趋势-原因分析瞎猜
以上这些结果有的很好理解,有的却让人费解。以下给出部分结论原因的推测:
1.在1990年前,由于技术的限制(没有PC来提高写作效率,没有互联网来加快学术交流,文章审核等流程也会比较缓慢),每年kmeans论文数量比较少是比较正常的。
2.而在1990s,PC的普及直接缩短了论文创作的周期,极大提高了文章数量。由于期刊文章有质量上的硬性要求,因此虽然也有增加但是还不是很明显;相对的,会议文章作为交流的工具,明显的反映出了论文创作数量上的变化。而关于1990sPC的普及,这里引用wiki的1990s词条中一段话作为补充说明:
The 1990s were a revolutionary decade for digital technology. Between 1990 and 1997, individual personal computer ownership in the US rose from 15 to 35%….Only a few million people used online services in 1990, and the World Wide Web had only just been invented. The first web browser went online in 1993 and by 2001, more than 50% of some Western countries had Internet access, and more than 25% had cell phone access.
3.在接下来的2000s,世界迎来另一个史诗级技术的普及——互联网。这次不仅是加速了文章创作的过程,而是极大地降低了沟通成本,使会议文章数量喷涌式的上涨。再次引用wiki的2000s in science and technology词条中的句子作为补充说明:
There was a huge jump in broadband internet usage globally - for example, it comprised only 6% of U.S. internet users in June 2000 and one mid-decade study predicted 62% adoption by 2010. Yet, by February 2007, over 80% of US Internet users were connected via broadband and broadband internet became almost a required standard for quality internet browsing. There were 77.4 million broadband subscribers in the US in December 2008, with 264 million broadband subscribers alone in the top 30 countries at that time.
4.以上是客观技术的影响,而随着算法本身的普及,相关文章数量上肯定也会有所增加。比如从1970-1990,就能看到文章数量是有所增加的。同时,随着机器学习在1990s跟2000s开始大放异彩,从1990s年被用于数据挖掘到2000s开始用在各种自适应算法中,而kmeans作为一种常见的分析、预处理手段,被更高频的引用也是理所当然的。这里能够看到简单的机器学习历史的简要介绍。
5.以上主要分析都是针对会议文章的。通过观察1970-2010年的kmeans相关会议文章向期刊文章的转化情况,可以发现IEEE基本不会让期刊文章有爆发式增长,审查还是比较严格的。但是在2012-2016年出现了期刊文章连续4年快速增长的情况。初期我推测是否是因为增加了额外的期刊导致论文数量的增加,如新增的China Communications Magazine Co. Ltd. IEEE Magazine。于是将1970年以来,主要期刊的论文数量变化趋势绘制出来(为了容易观看,数量太少的就不画出来了),如下图。可以看到,2012-2016年kmeans期刊文章连续增长的原因是Transaction和Journal中文章数量的增加。那么到底是碰巧这几年用到kmeans算法的文章水平都比较高,还是期刊要求在降低,或是别的原因,就不得而知了。 
6.除了以上这个未解之谜,还有为什么2010-2011以及2015-2016这几年会议文章的数量会大幅下降没有解决。理论上,会议文章能反映出该年的热点问题,所以初步猜测是碰巧那几年kmeans被关注的比较少,所以出现的偶然现象。
作者
一般论文作者不会只有一个,理论上会把对该文章有较重要贡献的人写上去;当然实际科研环境中也有很多别的规则,我们试试能不能从数据中看出来点什么。
这里把每个作者看作节点,两个节点间的连通性取决于是否合作创作过一篇文章,边的权重表示合作过多少次。于是,图里每个节点的度就是与他合作者的数量。节点度的数值与该值对应的频数的直方图如下。可以看出大部分作者在这些论文里的合作者在5个以内。

这里给出合作者数量最多的三个人:
| Rank | Author | Degree |
|---|---|---|
| 1 | Licheng Jiao | 30 |
| 2 | Jun Zhang | 26 |
| 3 | Wei Wang | 24 |
这几位也都是国内不同领域知名的专家了。但是看具体数据,如,Jiao 老师参与的kmeans相关论文共9篇,相关作者高达30个。通过查看具体数据,其中Jiao老师为一作的1篇,大部分都是最后一个作者,且相关文章的作者一般都是4~6人。对于Zhang老师跟Wang老师,基本也都是同样的情况。同时也能发现,这些老师也都是国内实验室的。
这其实也是国内科研界的缩影:国内科研人员在发表文章时,时常会将实验室同僚、还有大老板等相关人员带上,意在互相帮助。这也就说明了为什么这些大佬们的共同作者这么多,远超平均值。
除此之外别的有关作者的分析,总觉得数据量不足,难以证明结论,所以就不贴上来了。
关键词
每篇文章作者都会列出来几个关键词,接下来统计1969-2016年关键词出现的频数。以下给出总数量最多的5个关键词,这几个关键词能表明kmeans主要有哪些作用或跟那些领域相关。
| Rank | Key Word | Num |
|---|---|---|
| 1 | Clustering algorithms | 3358 |
| 2 | Algorithm design and analysis | 1070 |
| 3 | Data mining | 834 |
| 4 | Image segmentation | 785 |
| 5 | Feature extraction | 760 |
以下对这几个关键词简要说明:
Clustering algorithms:这个是kmeans算法的本质作用,所以次数毫无疑问是最多的
Algorithm design and analysis:有此关键字的文章,大多都属于对kmeans算法的分析、改进,或者提出新的算法并将kmeans作为其中一步,如
- Robust fuzzy clustering algorithms
- K-tree: a height balanced tree structured vector quantizer
- A modified version of the K-means algorithm with a distance based on cluster symmetry
Data mining:有此关键字的文章,更倾向于利用kmeans进行数据的预处理或者聚类,目的则是分析实际问题,如
- Experimental evaluation of structural features for a speaker-independent voice recognition system
- The application of agglomerative clustering in image classification systems
- Learning to extract temporal signal patterns from temporal signal sequence
Image segmentation:有此关键字的文章,则是利用kmeans进行图像分割,如
- Image coding based on segmentation using region growing
- Analysis of texture images using robust fractal description
Feature extraction:有此关键字的文章,则是利用kmeans提取特征,如
- Feature Extraction on Binary Patterns
- A World Wide Web region-based image search engine
我们可以将这几个关键词每年出现的次数画出来,如下图。 
从中可以看出:
1.通过Algorithm design and analysis关键词的增长趋势能分析出,对kmeans算法的改进或者引用数量,一直在增加;
2.通过Image segmentation和Feature extraction这两个关键词的高频,能看出kmeans大量被用在了图像分割与提取各种特征上;
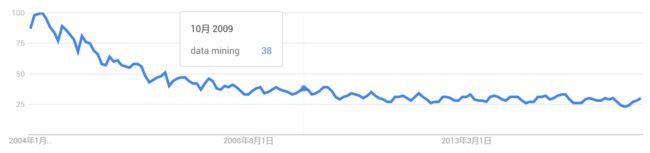
3.其中data mining的变化趋势比较诡异,在2009年达到峰值,后又快速下降;我分析了这些论文的标题、摘要等,也并没有看出内在原因是什么;同时也排除是因为data mining在2009年的火爆,导致论文数量的增多,因为从Google trends中能看到data mining作为一个成熟学科,热度一直在下降,并基本稳定,如下图;初步猜测可能是2008或2009年有某个改进的kmeans算法被提出来,导致被大量的借鉴;不过由于缺少reference信息,难以定量分析。
每年的关键词
除了分析关键词的总体情况,我们还能够从每一年热门关键词的变化中看出kmeans使用领域的改变。由于1995年以前文章数量较少,以下给出1995以后每年热门关键词top3。
| Rank | 1995 | 1996 | 1997 | 1998 |
|---|---|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms | Clustering algorithms | Clustering algorithms |
| 2 | Image segmentation | Neural networks | Image segmentation | Vector quantization |
| 3 | Neural networks | Partitioning algorithms | Partitioning algorithms | Neural networks |
| Rank | 1999 | 2000 | 2001 | 2002 |
|---|---|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms | Clustering algorithms | Clustering algorithms |
| 2 | Image segmentation | Neural networks | Data mining | Data mining |
| 3 | Neural networks | Partitioning algorithms | Image segmentation | Image segmentation |
| Rank | 2003 | 2004 | 2005 | 2006 |
|---|---|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms | Clustering algorithms | Clustering algorithms |
| 2 | Computer science | Image segmentation | Data mining | Data mining |
| 3 | Data mining | Data mining | Clustering methods | Partitioning algorithms |
| Rank | 2007 | 2008 | 2009 | 2010 |
|---|---|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms | Clustering algorithms | Clustering algorithms |
| 2 | Partitioning algorithms | Data mining | Data mining | Algorithm design and analysis |
| 3 | Data mining | Partitioning algorithms | Partitioning algorithms | Data mining |
| Rank | 2011 | 2012 | 2013 | 2014 |
|---|---|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms | Clustering algorithms | Clustering algorithms |
| 2 | Algorithm design and analysis | Algorithm design and analysis | Algorithm design and analysis | Algorithm design and analysis |
| 3 | Feature extraction | Vectors | Vectors | Accuracy |
| Rank | 2015 | 2016 |
|---|---|---|
| 1 | Clustering algorithms | Clustering algorithms |
| 2 | Algorithm design and analysis | Feature extraction |
| 3 | Feature extraction | Algorithm design and analysis |
稍微观察一下以上每年的热门关键词,就能发现kmeans的应用领域就这么几个;只是随着时间变化,热门程度上有所改变而已。同时,也能看出热点这种东西总是不断地在循环,感觉跟潮流时尚什么的一个样子,过时的东西放个几年可能又成了潮流的引领者。
对每年的abstract提取关键词
望通能自动提取每篇文章abstract的关键词,我可以根据关键词只查看感兴趣的文章,进行后续分析。
先对所有非期刊的文章提取abstract。对每个abstract去除停用词并tokenize。因为只是想简单分析,并没有stemming和过滤非单词等操作。
对单词列表计算TF-IDF,并提取每个abstract的TF-IDF最大的5个单词。
结果发现这样提取的词语,并不能推测出abstract的含义,效果不好。
最终还是得自己去把相关的文章abstract都过一遍。