SQLSERVER聚集索引与非聚集索引的再次研究(下)
上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了。
这篇文章只是作为参考,里面的观点不一定正确
上篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(上)
下篇主要说非聚集索引
先上非聚集索引的结构图

先创建Department8表
1 --非聚集索引 2 USE [pratice] 3 GO 4 5 CREATE TABLE Department8( 6 DepartmentID int IDENTITY(1,1) NOT NULL , 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 14 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department8](Name,[GroupName]) 15 16 DECLARE @i INT 17 SET @i=1 18 WHILE @i < 100 19 BEGIN 20 INSERT INTO Department8 ( name, [Company], groupname ) 21 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 22 SET @i = @i + 1 23 END 24 25 SELECT * FROM [dbo].[Department8] 26 27 --TRUNCATE TABLE [dbo].[DBCCResult] 28 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department8,-1) ') 29 30 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
先说明一下:
PageType 分页类型: 1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID: 0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 ,大于250就是text或image字段


每个数据页的IndexID都是0,说明数据页不属于非聚集索引的一部分,如果你有看到本系列的上篇,你会看到聚集索引表里数据页的IndexID都是1
说明数据页属于聚集索引的一部分,这里非聚集索引表的数据页的IndexID不是2而是0

-------------------------------------------------华丽的分割线--------------------------------------------------
下面看一下非聚集索引的索引页
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE([pratice],1,14499,3) 4 GO




聚集索引跟非聚集索引不同,聚集索引页里的一行表示一个数据页,而且标记了这个数据页索引字段的范围值
而非聚集索引跟数据表的记录一一对应,非聚集索引页里的一行记录表示数据表的一行记录,而且记录了指向实际记录的指针
其实非聚集索引的所有索引页合并在一起就是数据表的一个缩小版(表中只有非聚集索引),索引页中只包含创建非聚集索引时的字段,
所以当数据量少的时候,会使用全表扫描而不用索引扫描,因为堆中的数据页包含了表的全部字段 而索引页只包含了索引的字段,当select的时候
无论你是select * 还是select 某个字段 ,在效率上会差不多但是可以select出来的数据就会多很多
------------------------------------------------华丽的分割线--------------------------------------------------------------
那么非聚集索引是怎麽查找记录的?
这里分两种情况:(1)非聚集索引查找(2)非聚集索引扫描
这一次我就非聚集索引查找和非聚集索引扫描一起讲了,不像《SQLSERVER聚集索引与非聚集索引的再次研究(上)》里那样
查找和扫描分开来讲
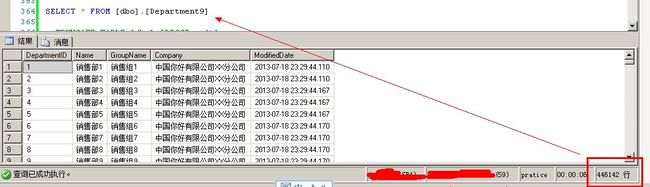
这里创建Department9表,由于Department8表只有99行记录,数据量少的话SQLSERVER会直接走全表扫描,看不出效果


1 --非聚集索引 2 USE [pratice] 3 GO 4 5 CREATE TABLE Department9( 6 DepartmentID int IDENTITY(1,1) NOT NULL , 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 14 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department9](Name,[GroupName]) 15 16 DECLARE @i INT 17 SET @i=1 18 WHILE @i < 1000000 19 BEGIN 20 INSERT INTO Department9 ( name, [Company], groupname ) 21 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 22 SET @i = @i + 1 23 END 24 25 SELECT * FROM [dbo].[Department9] 26 27 --TRUNCATE TABLE [dbo].[DBCCResult] 28 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department9,-1) ') 29 30 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
可以看到Department9表有446142行记录,因为insert插入的时间太久了,SQLSERVER没有执行完我就停止执行了,我的本本不给力啊!!
1 SELECT [GroupName] FROM [dbo].[Department9] WHERE name= '销售部1' --索引查找 2 SELECT [GroupName] FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --索引扫描 3 SELECT [GroupName] FROM [dbo].[Department9] WHERE [DepartmentID]=66 --全表扫描 4 SELECT [DepartmentID],[ModifiedDate] FROM [dbo].[Department9] WHERE name= '销售部8' --RID查找 索引查找 5 SELECT * FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --RID查找 索引扫描


大家可以用《SQLSERVER聚集索引与非聚集索引的再次研究(上)》中用到的脚本来看SQLSERVER查找记录的过程中申请了什么锁来推测
查找的过程
1 USE [pratice] 2 GO 3 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ 4 GO 5 6 BEGIN TRAN 7 SELECT [GroupName] FROM [dbo].[Department9] WHERE name= '销售部1' ----替换相应的SQL语句 8 9 --COMMIT TRAN--当看到结果之后要commit tran,不然锁不会释放 10 11 USE [pratice] --要查询申请锁的数据库 12 GO 13 SELECT 14 [request_session_id], 15 c.[program_name], 16 DB_NAME(c.[dbid]) AS dbname, 17 [resource_type], 18 [request_status], 19 [request_mode], 20 [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, 21 p.[index_id] 22 FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p 23 ON a.[resource_associated_entity_id]=p.[hobt_id] 24 LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] 25 WHERE c.[dbid]=DB_ID('pratice') AND a.[request_session_id]=@@SPID ----要查询申请锁的数据库 26 ORDER BY [request_session_id],[resource_type]
因为聚集索引页的每一行记录只记录了聚集索引字段在数据页的范围
但是这里有一个问题:为什麽非聚集索引扫描没有到堆中的数据页里去扫描呢?而在索引页里扫描?
既然在索引页里扫描和在数据页里扫描大家都是漫无目的地去扫描,那么到堆中的数据页里去扫描不是更好??因为堆中的数据页包含了
记录的所有字段,而索引页只包含了创建非聚集索引时所包含的字段
因为非聚集索引扫描的前提是:where 后面要查找的字段不是建立索引时的第一个字段(不是索引查找),但是要查找的字段是包含创建非聚集索引时
的字段列中,这个字段已经保存在非聚集索引的索引页里,例子里就是GroupName列
CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department9](Name,[GroupName])
又因为在一个表中索引页一般会等于或者小于数据页,所以在非聚集索引页里扫描会比堆里的数据页里
扫描的时间快,扫描的次数少(当数据量很多的时候)
-----------------------------------------------------------------------------------------------------------------------------------
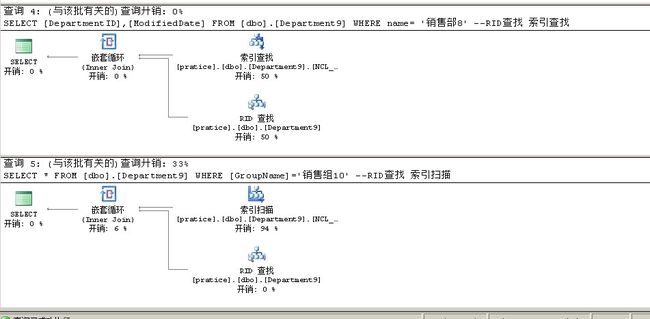
SELECT [GroupName] FROM [dbo].[Department9] WHERE name= '销售部1' --索引查找

为什麽上面这条语句是索引查找,而没有RID查找?因为索引建立在GroupName和NAME上
1 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department9](Name,[GroupName])
再看一下刚才给出的非聚集索引页结构
SELECT [GroupName] FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --索引扫描
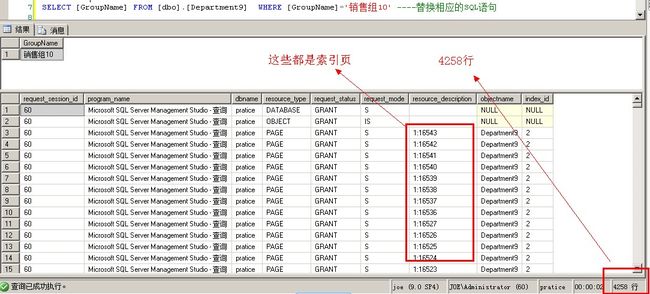
也是根据《SQLSERVER聚集索引与非聚集索引的再次研究(上)》里提到的
因为GroupName不是非聚集索引的第一个字段,所以只能用索引扫描
因为不知道key,所以SQLSERVER只能扫描所有索引页直到找到[GroupName]='销售组10',但是因为[GroupName]就存储在
索引页,所以没有RID查找
SELECT [GroupName] FROM [dbo].[Department9] WHERE [DepartmentID]=66 --全表扫描

因为DepartmentID不在非聚集索引里,所以SQLSERVER只能全表扫描
SELECT [DepartmentID],[ModifiedDate] FROM [dbo].[Department9] WHERE name= '销售部8' --RID查找 索引查找


因为非聚集索引不包括[DepartmentID],[ModifiedDate]这两个字段,所以SQLSERVER先索引查找,在索引页里找出name= '销售部8'的那条记录
然后根据name= '销售部8'的那条记录存储的HEAP RID(key) 值,在数据页里找到name= '销售部8' 这条记录,然后把其他字段读出来
实际上HEAP RID(key) 存储的就是指向数据页的指针,直接指向数据页里name= '销售部8' 这条记录
SELECT * FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --RID查找 索引扫描

其实这条语句的前半部分查找过程跟SELECT [GroupName] FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --索引扫描
这条语句是一样的,因为其他字段不在非聚集索引的索引页里,所以需要利用HEAP RID(key) 值找到记录所在的数据页然后把其他字段的值读出来
补充实验
为了验证下面这句话
因为在一个表中索引页一般会等于或者小于数据页,所以在非聚集索引页里扫描会比堆里的数据页里
扫描的时间快,扫描的次数少(当数据量很多的时候)
创建CompareNonclusteredScan表 ,CompareNonclusteredScan表跟Department9表是一样的,只是没有添加任何索引
1 --非聚集索引扫描和全表扫描比较 2 USE [pratice] 3 GO 4 5 CREATE TABLE CompareNonclusteredScan( 6 DepartmentID int IDENTITY(1,1) NOT NULL , 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 14 DECLARE @i INT 15 SET @i=1 16 WHILE @i < 1000000 17 BEGIN 18 INSERT INTO CompareNonclusteredScan ( name, [Company], groupname ) 19 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 20 SET @i = @i + 1 21 END 22 23 SELECT * FROM [dbo].CompareNonclusteredScan
1 --堆表扫描统计 2 USE [pratice] 3 GO 4 DBCC DROPCLEANBUFFERS 5 GO 6 SET STATISTICS IO ON 7 GO 8 SET STATISTICS TIME ON 9 GO 10 11 SELECT [GroupName] FROM CompareNonclusteredScan WHERE [GroupName]='销售组10'
1 --非聚集索引表扫描统计 2 USE [pratice] 3 GO 4 DBCC DROPCLEANBUFFERS 5 GO 6 SET STATISTICS IO ON 7 GO 8 SET STATISTICS TIME ON 9 GO 10 11 SELECT [GroupName] FROM [dbo].[Department9] WHERE [GroupName]='销售组10'
我们就比较扫描的时候,堆表和非聚集索引表 所用IO 和所用时间的情况
Department9表的统计情况
1 SQL Server 分析和编译时间: 2 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 3 4 (1 行受影响) 5 表 'Department9'。扫描计数 1,逻辑读取 4313 次,物理读取 3 次,预读 4304 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 6 7 SQL Server 执行时间: 8 CPU 时间 = 219 毫秒,占用时间 = 1593 毫秒。
CompareNonclusteredScan表的统计情况
1 SQL Server 分析和编译时间: 2 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 3 4 (1 行受影响) 5 表 'CompareNonclusteredScan'。扫描计数 5,逻辑读取 8766 次,物理读取 0 次,预读 8756 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 6 7 SQL Server 执行时间: 8 CPU 时间 = 296 毫秒,占用时间 = 1059 毫秒。
当我不执行DBCC DROPCLEANBUFFERS 不清空缓存
1 SQL Server 分析和编译时间: 2 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 3 4 (1 行受影响) 5 表 'Department9'。扫描计数 1,逻辑读取 4313 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 6 7 SQL Server 执行时间: 8 CPU 时间 = 78 毫秒,占用时间 = 73 毫秒。
1 SQL Server 分析和编译时间: 2 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 3 4 (1 行受影响) 5 表 'CompareNonclusteredScan'。扫描计数 5,逻辑读取 8766 次,物理读取 0 次,预读 8756 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 6 7 SQL Server 执行时间: 8 CPU 时间 = 250 毫秒,占用时间 = 995 毫秒。
为什麽逻辑读的次数、扫描的次数 、占用时间会相差这麽多??
其实原因很简单
一般在一张表里面索引页面都会比数据页面少,比如一个表有100行记录,非聚集索引页面用一个页面就装下100行记录
数据页面一个页面只能装下50个,需要用两个数据页才能装得下所有数据
如下图,一个只有非聚集索引的表,数据页面有11个,非聚集索引页面有9个

如果要找一行记录,如果扫描数据页可能要扫描到第二页才能找到那条记录,如果扫描非聚集索引页,只需要扫描一个非聚集索引页就可以了
先读取非聚集索引页面(逻辑读取)-》再扫描非聚集索引页面(扫描计数)
所以逻辑读取、扫描计数、占用时间跟堆表相差这麽大的原因就是这个
还有下面这个SQL语句也是索引扫描,不加where 筛选条件,因为GroupName包含在非聚集索引中,所以扫描非聚集索引页面比扫描数据页面的效率高
1 SELECT [GroupName] FROM [dbo].[Department9] --索引扫描
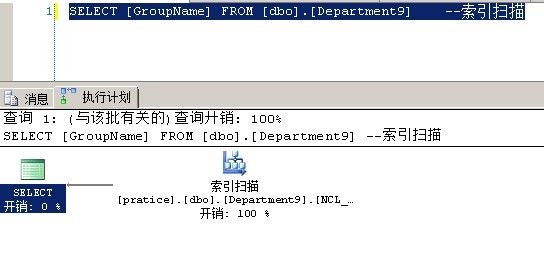
现在大家可以看出来扫描索引页和扫描数据页的优势了吧??
那么非聚集索引是不是一定会扫描非聚集索引页呢(当数据量很少的时候)???
在有聚集索引的表里,只插入少量记录,表中是不会产生聚集索引页的,因为聚集索引扫描是扫描数据页不会扫描聚集索引页
那么非聚集索引会不会跟聚集索引一样呢??
先drop掉Department9表,然后重新建立Department9表,建表脚本跟刚才一样,只插入5条记录



结果还是会生成非聚集索引页,就是说无论什么情况,非聚集索引只会扫描非聚集索引页
-------------------------------------------华丽的分割线------------------------------------------------------
覆盖索引 INCLUDE()
覆盖索引只能建立在非聚集索引上,那么覆盖索引是怎样的呢?
建立Department10表
1 --覆盖索引 2 USE [pratice] 3 GO 4 DROP TABLE [dbo].[Department10] 5 CREATE TABLE Department10( 6 DepartmentID int IDENTITY(1,1) NOT NULL , 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 14 CREATE INDEX NCL_Name_GroupName ON [dbo].[Department10](Name,[GroupName]) INCLUDE(ModifiedDate) 15 16 17 DECLARE @i INT 18 SET @i=1 19 WHILE @i < 10000 20 BEGIN 21 INSERT INTO Department10( name, [Company], groupname ) 22 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 23 SET @i = @i + 1 24 WAITFOR DELAY '00:00:00:100' 25 END 26 27 SELECT * FROM [dbo].[Department10] 28 29 --TRUNCATE TABLE [dbo].[DBCCResult] 30 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department10,-1) ') 31 32 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
查看一下索引页14549


你会发现覆盖索引跟非聚集索引的索引页结构是一样的,只不过多了ModifiedDate列,但是ModifiedDate列没有在旁边加上(key)
大家注意看

那么既然覆盖索引只是在索引页加上一个字段,那么倒不如创建非聚集索引的时候,把ModifiedDate列也纳入到非聚集索引中
1 CREATE INDEX NCL_Name_GroupName ON [dbo].[Department10](Name,[GroupName],[ModifiedDate])
究竟覆盖索引有什么存在的价值呢???
我们看一下MSDN的解释
http://msdn.microsoft.com/zh-cn/library/ms190806(SQL.90).aspx
大家注意看里面其中一句话
![]()
看了MSND的介绍,本人觉得覆盖索引最大的优势是突破了索引列大小的限制,将尽可能多的列(字段)放到索引页,
这样查询数据的时候就可以尽量使用索引扫描而不用RID查找或全表扫描,覆盖索引其他特别的用途或者特点或者优势就找不到了
还有MSDN里面提到“只能对表或索引视图的非聚集索引定义非键列”,为什麽聚集索引不能使用覆盖索引??
如果聚集索引扫描的是数据页,那么就算你把覆盖索引加到聚集索引的索引页也没有用,因为SQLSERVER使用聚集索引扫描的时候扫描的
是数据页而不像非聚集索引那样扫描的是索引页

--------------------------------------------------华丽的分割线-------------------------------------------------------
聚集索引和非聚集索引并存

1 --非聚集索引和聚集索引 2 USE [pratice] 3 GO 4 5 CREATE TABLE Department11( 6 DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY, 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department11](Name,[GroupName]) 14 15 DECLARE @i INT 16 SET @i=1 17 WHILE @i < 1000 18 BEGIN 19 INSERT INTO Department11( name, [Company], groupname ) 20 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 21 SET @i = @i + 1 22 END 23 24 SELECT * FROM [dbo].[Department11] 25 26 --TRUNCATE TABLE [dbo].[DBCCResult] 27 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department11,-1) ') 28 29 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

先来看一下非聚集索引页,可以看到非聚集索引中多了一个字段就是建立聚集索引时的第一个字段DepartmentID

再来看聚集索引页

MSDN中的解释:http://msdn.microsoft.com/zh-cn/library/ms177484(v=SQL.105).aspx
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。
如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。
此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。
SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行
根据MSDN的解释,实际上相当于在非聚集索引上建立多一个字段,而这个字段就是联系聚集索引和非聚集索引的桥梁
1 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department11](Name,[GroupName],[DepartmentID])


那么当要查询的字段不在非聚集索引的索引页的时候,那么就要到聚集索引的叶子节点(数据页)去找记录,那么这个查找记录的过程是怎样的呢?
这个查找记录的过程实际上就是“书签查找”,在本文章的下面会讲到
-------------------------------------------------华丽的分割线-------------------------------------------------------------
网上有人说,只有堆表才有IAM页,并且IAM页面维护着数据页的前后顺序,那么索引页是不是就没有IAM页维护索引页面的前后顺序呢?
有索引的表的数据页有没有IAM页来维护数据页的前后顺序呢?


MSDN中的解释:
http://msdn.microsoft.com/zh-cn/library/ms189051%28SQL.90%29.aspx
表、索引或索引视图分区的页分配由一个 IAM 页链管理。sys.system_internals_allocation_units 中的 first_iam_page 列指向 IAM 页链(用于管理分配给 IN_ROW_DATA 分配单元中的表、索引或索引视图的空间)中的第一个 IAM 页。
sys.partitions 为表或索引中每个分区返回一行。
堆在 sys.partitions 中有一行,其 index_id = 0。
sys.system_internals_allocation_units 中的 first_iam_page 列指向指定分区中堆数据页集合的 IAM 链。服务器使用 IAM 页查找数据页集合中的页,因为这些页没有链接。
表或视图的聚集索引在 sys.partitions 中有一行,其 index_id = 1。
sys.system_internals_allocation_units 中的 root_page 列指向指定分区内聚集索引 B 树的顶端。服务器使用索引 B 树查找分区中的数据页。
为表或视图创建的每个非聚集索引在 sys.partitions 中有一行,其 index_id > 1。
sys.system_internals_allocation_units 中的 root_page 列指向指定分区内非聚集索引 B 树的顶端。
至少有一个 LOB 列的每个表在 sys.partitions 中也有一行,其 index_id > 250。
first_iam_page 列指向管理 LOB_DATA 分配单元中的页的 IAM 页链。
再说明一下在DBCC IND的结果中PageType 字段和IndexID字段的含义:
PageType 分页类型: 1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID: 0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 ,大于250就是text或image字段
-------------------------------------------------------华丽的分割线----------------------------------------------------
书签查找 BookMark Lookup
建立Department12表
1 --非聚集索引和聚集索引 书签查找 2 USE [pratice] 3 GO 4 5 CREATE TABLE Department12( 6 DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY, 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department12](Name) 14 15 DECLARE @i INT 16 SET @i=1 17 WHILE @i < 10000 18 BEGIN 19 INSERT INTO Department12( name, [Company], groupname ) 20 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 21 SET @i = @i + 1 22 END 23 24 SELECT * FROM [dbo].[Department12] 25 26 --TRUNCATE TABLE [dbo].[DBCCResult] 27 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department12,-1) ') 28 29 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
书签查找的主体是“非聚集索引”
所以书签查找只会出现在下面两种表中:
(1)只有非聚集索引的表
(2)聚集索引和非聚集索引并存的表
而只有聚集索引的表是不会出现书签查找的
为什麽非聚集索引才会出现书签查找???
大家可以再看一下非聚集索引的结构图和MSDN的定义


而书签查找的定义:
MSDN定义:
定义:当查询优化器使用非聚集索引进行查找时,如果所选择的列或查询条件中的列只部分包含在使用的非聚集索引和聚集索引中时,就需要一个查找(lookup)来检索其他字段来满足请求。对一个有聚簇索引的表来说是一个键查找(key lookup),对一个堆表来说是一个RID查找(RID lookup),这种查找即是——书签查找(bookmark lookup)。简单的说就是当你使用的sql查询条件和select返回的列没有完全包含在索引列中时就会发生书签查找
因为无论是(1)只有非聚集索引的表 还是(2)聚集索引和非聚集索引并存的表 数据页都不是非聚集索引的一部分
所以如果所查找的数据不在非聚集索引的索引页就需要到数据页去取数据,这种情况就叫“书签查找”
其实数据表里的数据就像书本里的内容,而非聚集索引就像书签,因为书本里的内容不可能全部在书签里,但是要找到书本里的内容需要书签去定位
其实简单来讲,就四种情况:
我们再回到Department9表
第一种
1 SELECT [DepartmentID],[ModifiedDate] FROM [dbo].[Department9] WHERE name= '销售部8' --RID查找 索引查找
前面说到的:
因为非聚集索引不包括[DepartmentID],[ModifiedDate]这两个字段,所以SQLSERVER先索引查找,在索引页里找出name= '销售部8'的那条记录
然后根据name= '销售部8'的那条记录存储的HEAP RID(key) 值,在数据页里找到name= '销售部8' 这条记录,然后把其他字段读出来
实际上HEAP RID(key) 存储的就是指向数据页的指针,直接指向数据页里name= '销售部8' 这条记录
第二种
1 SELECT * FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --RID查找 索引扫描
前面说到的:
其实这条语句的前半部分查找过程跟SELECT [GroupName] FROM [dbo].[Department9] WHERE [GroupName]='销售组10' --索引扫描
这条语句是一样的,因为其他字段不在非聚集索引的索引页里,所以需要利用HEAP RID(key) 值找到记录所在的数据页然后把其他字段的值读出来
第三种
我们先建立Department13表 ,Department13表和Department11表的表结构是一样的
不过在Department13表里添加了1000000条记录,因为记录不够多(数据量很少)会走聚集索引扫描
1 --非聚集索引和聚集索引 2 USE [pratice] 3 GO 4 5 CREATE TABLE Department13( 6 DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY, 7 Name NVARCHAR(200) NOT NULL, 8 GroupName NVARCHAR(200) NOT NULL, 9 Company NVARCHAR(300), 10 ModifiedDate datetime NOT NULL DEFAULT (getdate()) 11 ) 12 13 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department13](Name,[GroupName]) 14 15 DECLARE @i INT 16 SET @i=1 17 WHILE @i < 1000000 18 BEGIN 19 INSERT INTO Department13( name, [Company], groupname ) 20 VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) ) 21 SET @i = @i + 1 22 END 23 24 SELECT * FROM [dbo].[Department13]
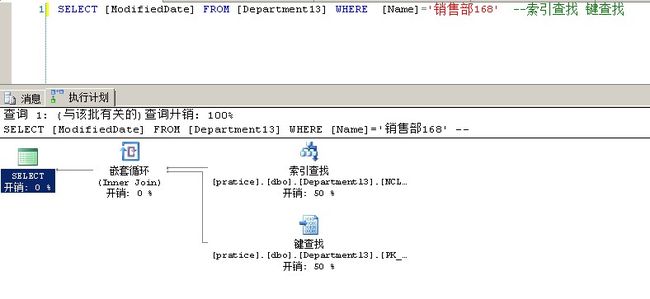
1 SELECT [ModifiedDate] FROM [Department13] WHERE GroupName='销售组168' --索引扫描 键查找 并行

那么第三种情况的查找过程是怎样的??
先用之前用到的测试语句测试一下用了什么锁
1 USE [pratice] 2 GO 3 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ 4 GO 5 6 BEGIN TRAN 7 SELECT [ModifiedDate] FROM [Department13] WHERE GroupName='销售组168' --索引扫描 键查找 并行 8 9 --COMMIT TRAN 10 11 USE [pratice] --要查询申请锁的数据库 12 GO 13 SELECT 14 [request_session_id], 15 c.[program_name], 16 DB_NAME(c.[dbid]) AS dbname, 17 [resource_type], 18 [request_status], 19 [request_mode], 20 [resource_description],OBJECT_NAME(p.[object_id]) AS objectname, 21 p.[index_id] 22 FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p 23 ON a.[resource_associated_entity_id]=p.[hobt_id] 24 LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid] 25 WHERE c.[dbid]=DB_ID('pratice') AND a.[request_session_id]=@@SPID ----要查询申请锁的数据库 26 ORDER BY [request_session_id],[resource_type]


大家可以看到执行计划里面索引扫描的开销是96% ,键查找的开销是0%
因为SQLSERVER要扫描每一个非聚集索引页,当找到GroupName='销售组168'的那条记录的时候,自然就知道[DepartmentID]的值
这里GroupName='销售组168'的那条记录DepartmentID的值是168

然后根据[DepartmentID]的值去聚集索引页里找记录,但是聚集索引页里的每行记录只记录了聚集索引键(DepartmentID)的范围值
那怎么找呢?
先看一下Department13表的聚集索引页
1 --先清空[DBCCResult]表里的记录 2 --TRUNCATE TABLE [dbo].[DBCCResult] 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,Department13,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC


可以看到每隔120条记录为一行,即是每个数据页有120条记录

刚才说到:然后根据[DepartmentID]的值去聚集索引页里找记录,但是聚集索引页里的每行记录只记录了聚集索引键(DepartmentID)的范围值
那怎么找呢?
答案是匹配查找,SQLSERVER需要在聚集索引页里找到168究竟在哪个范围之内,逐个匹配,当匹配到108~209这个范围之后
就到14554的数据页里找数据,把[ModifiedDate]的值读出来

因为要用到匹配查找,所以这里会有嵌套循环inner join,又因为数据有点多,所以需要用到并行

因为这里只需要在每个非聚集索引页里逐行记录逐行记录扫描,而不需要在聚集索引页里逐行记录去查找(就是说聚集索引什么动作都不用做,
等非聚集索引把GroupName='销售组168'那条记录读出来把DepartmentID也读出来然后与聚集索引页里的记录逐个匹配就可以了)
所以开销是0%

第四种
1 SELECT [ModifiedDate] FROM [Department13] WHERE [Name]='销售部168' --索引查找 键查找
前面说到的:
第四种的后半部分查找过程其实跟第三种SELECT [ModifiedDate] FROM [Department13] WHERE GroupName='销售组168' --索引扫描 键查找 并行
是一样的,而前半部分的索引查找过程就不说了,前面已经说过了
解决方法:
至于书签查找的解决办法,网上很多说使用覆盖索引,实际上这个解决方法只是对了一半
因为前面在讲覆盖索引的时候说到“当你当前索引的列数超过16列或最大索引键大小超过900字节”才考虑使用覆盖索引,如果你当前表中的
非聚集索引还没有达到这个限制可以把要包含的列纳入到索引中来
例子里就是[ModifiedDate]字段
1 DROP INDEX [dbo].[Department13].[NCL_Name_GroupName] 2 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department13](Name,[GroupName],[ModifiedDate]) 3 4 SELECT [ModifiedDate] FROM [Department13] WHERE GroupName='销售组168' --索引扫描
把[ModifiedDate]字段 纳入到非聚集索引之后就变成了索引扫描

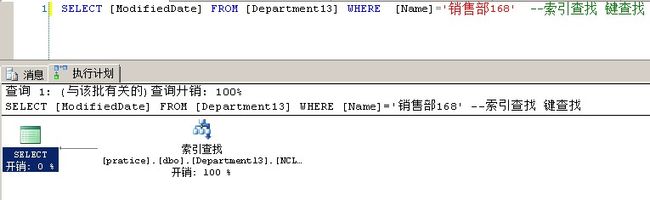
可以看到已经把[ModifiedDate]字段放到非聚集索引页里去了

对于Department9表
1 DROP INDEX [dbo].[Department9].[NCL_Name_GroupName] 2 CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department9](Name,[GroupName],[ModifiedDate],[DepartmentID],[Company])

已经把需要查询到的字段放到非聚集索引页里去了

--------------------------------------------------------华丽的分割线----------------------------------------------------
MSDN参考资料:
表组织和索引组织
聚集索引结构
非聚集索引结构
大家看完这两篇文章之后可以到
园子里懒惰的肥兔大侠写的文章里看一下他画的图跟本人画的图的差别,判断一下懒惰的肥兔大侠画的图的正确性
Sql Server查询性能优化之不可小觑的书签查找
至于懒惰的肥兔大侠画的图是对的还是错的本人不作评论,因为本人画的图也有可能是错的o(∩_∩)o
---------------------------------------------------华丽的分割线--------------------------------------------------
这两篇文章写完了,松一口气了,断断续续用了4天时间差不多用了20个小时来写,不停找资料,画草图,希望各位看官可以给个推荐o(∩_∩)o
如有不对的地方,也欢迎强烈拍砖o(∩_∩)o
----------------------------------------------------------------------------------
2013-8-18 补充:
关于覆盖索引的列只存在于叶子节点索引页,根节点的索引页里是不存在覆盖索引的列的
覆盖索引根节点和叶子节点的区别,根节点索引页面会有ChildFileId和ChildPageId来连接叶子节点
以下来自联机丛书
“通过将包含列(称为非键列)添加到索引的叶级, 可以扩展非聚集索引的功能。
键列存储在非聚集索引的所有级别,而非键列仅存储在叶级别。”

更详细的大家可以看一下这篇文章:T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
在文章的评论里有讲到“非键列仅存储在叶级别”
------------------------------------------------------------------------------------------
2013-9-15 补充:
如何查看非聚集索引页面的内容,使用DBCC PAGE的时候使用1这个格式就可以了
表中有两条数据记录,因此非聚集索引也有两条记录,而且两套记录的Record Type = INDEX_RECORD
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE([pratice],1,13571,1) 4 GO
1 PAGE: (1:13571) 2 3 4 BUFFER: 5 6 7 BUF @0x03E05DA4 8 9 bpage = 0x1748A000 bhash = 0x00000000 bpageno = (1:13571) 10 bdbid = 5 breferences = 0 bUse1 = 3652 11 bstat = 0x2c0000b blog = 0x2159bbcb bnext = 0x00000000 12 13 PAGE HEADER: 14 15 16 Page @0x1748A000 17 18 m_pageId = (1:13571) m_headerVersion = 1 m_type = 2 19 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x4 20 m_objId (AllocUnitId.idObj) = 537 m_indexId (AllocUnitId.idInd) = 256 21 Metadata: AllocUnitId = 72057594073120768 22 Metadata: PartitionId = 72057594060931072 Metadata: IndexId = 3 23 Metadata: ObjectId = 1399676034 m_prevPage = (0:0) m_nextPage = (0:0) 24 pminlen = 13 m_slotCnt = 2 m_freeCnt = 8060 25 m_freeData = 128 m_reservedCnt = 0 m_lsn = (3045:23318:110) 26 m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 27 m_tornBits = 0 28 29 Allocation Status 30 31 GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED 32 PFS (1:8088) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED 33 ML (1:7) = NOT MIN_LOGGED 34 35 DATA: 36 37 38 Slot 0, Offset 0x60, Length 16, DumpStyle BYTE 39 40 Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 41 Memory Dump @0x09F3C060 42 43 00000000: 16010000 009f3800 00010000 000200fc †......8......... 44 45 Slot 1, Offset 0x70, Length 16, DumpStyle BYTE 46 47 Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 48 Memory Dump @0x09F3C070 49 50 00000000: 16020000 009f3800 00010001 000200fc †......8......... 51 52 OFFSET TABLE: 53 54 Row - Offset 55 1 (0x1) - 112 (0x70) 56 0 (0x0) - 96 (0x60) 57 58 59 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
----------------------------------------------------------------------------------------------
2013-10-18 补充
在原先只有非聚集索引的表上加聚集索引之后,除了所有索引页和数据页重新调整外,数据页会比没有加聚集索引前少了
为了证明这个,使用下面脚本
1 USE [pratice] 2 GO 3 4 --建表 5 CREATE TABLE ct1(c1 INT,c2 INT, c3 VARCHAR (2000)); 6 GO 7 8 9 --建立非聚集索引 10 CREATE INDEX nt1c1 ON ct1(c2); 11 GO 12 13 14 --插入测试数据 15 DECLARE @a INT; 16 SELECT @a = 1; 17 WHILE (@a <= 1000) 18 BEGIN 19 INSERT INTO ct1 VALUES (@a,@a, replicate('a', 2000)) 20 SELECT @a = @a + 1 21 END 22 GO 23 24 25 26 --查询数据 27 SELECT * FROM ct1
看一下数据页
1 CREATE TABLE DBCCResult ( 2 PageFID NVARCHAR(200), 3 PagePID NVARCHAR(200), 4 IAMFID NVARCHAR(200), 5 IAMPID NVARCHAR(200), 6 ObjectID NVARCHAR(200), 7 IndexID NVARCHAR(200), 8 PartitionNumber NVARCHAR(200), 9 PartitionID NVARCHAR(200), 10 iam_chain_type NVARCHAR(200), 11 PageType NVARCHAR(200), 12 IndexLevel NVARCHAR(200), 13 NextPageFID NVARCHAR(200), 14 NextPagePID NVARCHAR(200), 15 PrevPageFID NVARCHAR(200), 16 PrevPagePID NVARCHAR(200) 17 ) 18 19 --TRUNCATE TABLE [dbo].[DBCCResult] 20 -- 21 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ct1,-1) ') 22 23 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
查询到有345行记录,去除两个IAM页面, 非聚集索引页面和数据页有343个


这时候的非聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE([pratice],1,110,3) 4 GO

建立聚集索引
1 --建立聚集索引 2 CREATE CLUSTERED INDEX t1c1 ON ct1(c1); 3 GO
再看一下页面情况
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 -- 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ct1,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC 6 7 SELECT COUNT(*) FROM [dbo].[DBCCResult]


只有256行记录,取出两个IAM页面, 也就是有254个数据页和索引页面
看一下非聚集索引页面
1 DBCC TRACEON(3604,-1) 2 GO 3 DBCC PAGE([pratice],1,14495,3) 4 GO

会看到多了UNIQUIFIER(KEY)列,这个很正常,因为SQLSERVER需要将聚集索引和非聚集索引做关联
关联的字段是c1列,那么肯定会将c1(KEY)列和UNIQUIFIER(KEY)列搬过来非聚集索引页面
这个没有什么好研究的
关键大家看一下加聚集索引前和加聚集索引后的页面情况

非聚集索引页面少了,所有数据页面的页面编号都不一样了,这里就证明了“建立聚集索引后所有索引页和数据页重新调整”
我们drop掉聚集索引
1 DROP INDEX t1c1 ON ct1
看一下页面情况
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 -- 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ct1,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC 6 7 SELECT COUNT(*) FROM [dbo].[DBCCResult]
页面还是256

可以看到数据页面和非聚集索引页面的页面编号有不同了,证明SQLSERVER又重新分配索引页面和数据页面
其实这里可以证明:建立聚集索引和删除聚集索引是一个昂贵的操作,建立和删除聚集索引都需要重新分配页面
我们删除非聚集索引
1 DROP INDEX nt1c1 ON ct1
1 --TRUNCATE TABLE [dbo].[DBCCResult] 2 -- 3 INSERT INTO DBCCResult EXEC ('DBCC IND(pratice,ct1,-1) ') 4 5 SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC

可以看到,数据页面的编号都没有变化,非聚集索引页面全部删除了
所以,删除非聚集索引对于SQLSERVER影响不大,为什麽聚集索引和非聚集索引的建立和删除会有这麽大的区别
大家只要认真看 SQLSERVER聚集索引与非聚集索引的再次研究(上/下)就可以了,文章开头的结构图已经给出了答案o(∩_∩)o
简单对比
虽然使用主键值当作指针会让辅助索引占用更多空间,但好处是,聚集索引在移动行时无需更新辅助索引中的主键值,而非聚集索引需要调整其叶子节点中的堆地址
聚集索引下,数据记录是保存在B+树的叶子节点(大小相当于磁盘上的页)上,当插入新的数据时,如果主键的值是有序的,它会把每一条记录都存储在上一条记录的后面,但是如果主键使用的是无序的数值,例如UUID,这样在插入数据时聚集索引无法简单地把新的数据插入到最后,而是需要为这条数据寻找合适的位置,这就额外增加了工作