EfficientNet
一、背景介绍
卷积神经网络通常是在固定资源预算下开发的,如果可用资源有变化,则可以进行Model Scaling(模型缩放)以提高模型性能。为了获得更高的准确率和效率,对卷积网络进行缩放是近几年研究者们经常干的事情,比如从ResNet-18到ResNet-200是对depth的缩放,MobileNet系列里width multiplier对channel的缩放等等。然而,大家都在模型缩放了,而且放缩depth、width(channel)以及resolution都是有效的,但是并没有人总结出原理性的方法来指导模型缩放。大家都是任意地对其中一两个维度进行缩放,缩放多少也得靠手动调整,不仅过程繁琐,而且这样的“野路子”产生的网络性能也不是最佳的。如下图所示,分别增大网络三个维度到一定程度,准确率会饱和:
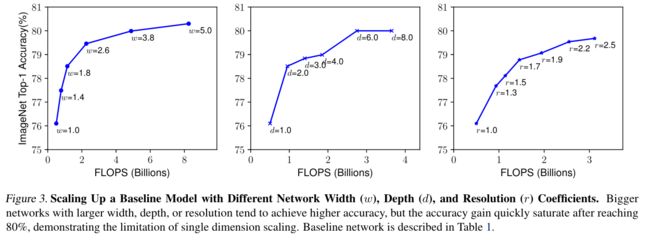 于是,EfficientNet的作者决定总结出教科书般的模型缩放原则。他们提出了一种简单高效的模型缩放方法,即
于是,EfficientNet的作者决定总结出教科书般的模型缩放原则。他们提出了一种简单高效的模型缩放方法,即compound scaling method(复合缩放方法)。下图展示了对不同维度缩放的区别:

二、思路提出
2.1 Compound scaling method
按道理来说,输入图片分辨率越高,也就需要更深的网络来扩大感受野,更多的通道来捕捉特征。考虑到深度、宽度和分辨率之间应该是有联系的,作者设置了不同深度和分辨率的网络作为对照,同时对网络的宽度进行缩放,发现d = 2, r = 1.3组不容易饱和,而且在同等FLOPs下,准确率最高。这就验证了作者的猜想:平衡好网络三个维度的缩放系数可以得到更好的效率和准确率。
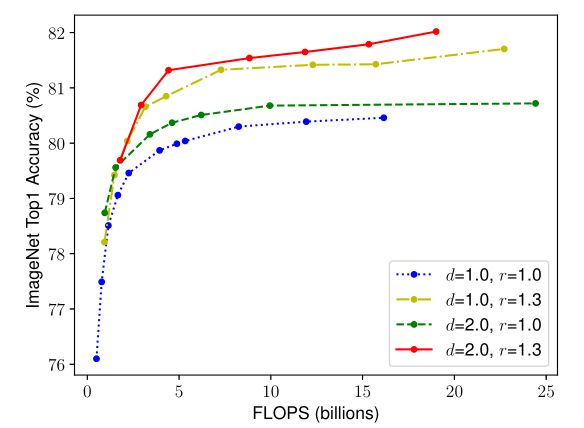
鉴此,作者提出了以下的基本优化模型,在资源(Memory、FLOPS)有限的情况下,通过三个维度的缩放,最大化准确率:

其中 N ( d , w , r ) N(d, w, r) N(d,w,r)表示缩放系数分别为 d , w , r d, w, r d,w,r的卷积网络, F ^ i L ^ i \hat{F}_i^{\hat L_i} F^iL^i表示第 i i i个阶段(stage) F i F_i Fi层重复了几次(卷积网络可以被划分为几个阶段,如ResNet有五个阶段),并且depth、width、resolution都乘上缩放系数。
随之而来的问题是,这些系数怎么确定呢?首先作者不会变动baseline的具体参数设置,其次所有层的缩放系数都是相同的,这样可以减小参数空间。但仅仅这两个限制条件还是不够的,作者提出了复合缩放方法:

其中, α , β , γ \alpha, \beta, \gamma α,β,γ为基本缩放系数,也可以看作是资源分配在三个维度上的比例;而 ϕ \phi ϕ是复合缩放系数,其控制着当前消耗的资源量。另外,通常FLOPS的大小是和 α , β 2 , γ 2 \alpha, \beta^2, \gamma^2 α,β2,γ2成比例的,如果宽度和分辨率增加一倍,那么计算量就会增至四倍,如果深度增加了一倍,那么计算量增至两倍,所以限制 α ⋅ β 2 ⋅ γ 2 \alpha \cdot \beta^2 \cdot \gamma^2 α⋅β2⋅γ2也是为了方便控制资源占用。再考虑 ϕ \phi ϕ的影响,缩放后的网络总资源消耗量是初始资源的 ( α ⋅ β 2 ⋅ γ 2 ) ϕ (\alpha \cdot \beta^2 \cdot \gamma^2)^\phi (α⋅β2⋅γ2)ϕ倍。
2.2 EfficientNet
在求解上面两组模型之前,先讲讲什么是EfficientNet。因为模型缩放不会改变每一层的参数设置,所以有个好的baseline 对模型缩放的效果很重要。作者借鉴了MnasNet,以 A C C ( m ) × [ F L O P S ( m ) / T ] w ACC(m) \times \left[FLOPS(m) / T\right]^w ACC(m)×[FLOPS(m)/T]w为优化目标,采用了和MnasNet一样的搜索空间,设计出了和MnasNet类似的网络,即为EfficientNet,可以看一下EfficientNet-B0的网络结构,主要是以MobileNet_v2中提出的inverted bottleneck为主:

现在讲一下怎么求解之前的模型:
- 固定 ϕ = 1 \phi = 1 ϕ=1,即假设了两倍初始资源,利用小网格搜索(告辞)确定 α , β , γ \alpha, \beta, \gamma α,β,γ,即为EfficientNet-B0。
- 然后在得到的 α , β , γ \alpha, \beta, \gamma α,β,γ基础上,增大 ϕ \phi ϕ,继而得到EfficientNet-B1至EfficientNet-B7。
注意,利用网格搜索来确定最优 α , β , γ \alpha, \beta, \gamma α,β,γ是非常耗时的,所以这种方式不能直接应用在大型模型上,所以作者们仅在第一步对baseline这样的小模型进行参数搜索,之后的大模型就直接使用已经得到的参数了,仅改变 ϕ \phi ϕ。
但实际上EfficientNet代码的实现并不是上面这张图看起来这么简单,部分模块的具体实现我缺乏前置知识暂时看不懂,后续看懂之后我再更新。
参考资料
- 令人拍案叫绝的EfficientNet和EfficientDet
- EfficientNet-可能是迄今为止最好的CNN网络
- FLOPs与模型推理速度