Ceph 入门系列(二):Ceph三种(块/文件/对象)存储接口的由来和特点
转载:理解Ceph的三种存储接口:块设备、文件系统、对象存储
一. Ceph的块设备存储接口
首先,什么是块设备?
块设备是i/o设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,还可以在设备的任意位置读取一定长度的数据。
看不懂?那就暂且认为块设备就是硬盘或虚拟磁盘。
查看下Linux环境中的设备:
# lsblk

上面的/dev/sda、/dev/sdb和/dev/hda都是块设备文件,这些文件是怎么出现的呢?
当给计算机连接块设备(硬盘)后,系统检测的有新的块设备,该类型块设备的驱动程序就在/dev/下创建个对应的块设备设备文件,用户就可以通过设备文件使用该块设备了。
它们怎么有的叫 sda?有的叫 sdb?有的叫 hda?
以sd开头的块设备文件对应的是SATA接口的硬盘,而以hd开头的块设备文件对应的是IDE接口的硬盘。
那SATA接口的硬盘跟IDE接口的硬盘有啥区别?你只需要知道,IDE接口硬盘已经很少见到了,逐渐被淘汰中,而SATA接口的硬盘是目前的主流。而sda和sdb的区别呢?当系统检测到多个SATA硬盘时,会根据检测到的顺序对硬盘设备进行字母顺序的命名。
怎么还有的叫 rbd1 和 rbd2 呢?
被你发现了,rbd就是我们压轴主角了。rbd就是由Ceph集群提供出来的块设备。可以这样理解,sda和hda都是通过数据线连接到了真实的硬盘,而rbd是通过网络连接到了Ceph集群中的一块存储区域,往rbd设备文件写入数据,最终会被存储到Ceph集群的这块区域中。
那么块设备怎么用呢?
我们打个比方,一个块设备是一个粮仓,数据就是粮食。农民伯伯可以存粮食(写数据)了,需要存100斤玉米,粮仓(块设备)这么大放哪里呢,就挨着放(顺序写),又需要存1000斤花生,还是挨着放。又需要存……后来,农民伯伯来提粮食(读数据)了,他当时存了1000斤小麦,哎呀妈呀,粮仓这么大,小麦在哪里啊?仓库管理员找啊找,然后哭晕在了厕所!
新管理员到任后,想了个法子来解决这个问题,用油漆把仓库划分成了方格状,并且编了号,在仓库门口的方格那挂了个黑板,当农民伯伯来存粮食时,管理员在黑板记录,张三存了1000斤小麦在xx方格处。后来,农民伯伯张三来取粮食时,仓库管理员根据小黑板的记录很快提取了粮食。
故事到此为止了,没有方格和黑板的仓库(块设备)称为裸设备。由上例可见,裸设备对于用户使用是很不友好的,直接导致了旧仓库管理员的狗带。例子中划分方格和挂黑板的过程其实是在块设备上构建文件系统的过程,文件系统可以帮助块设备对存储空间进行条理的组织和管理,于是新管理员通过文件系统(格子和黑板)迅速找到了用户(农民伯伯张三)存储的数据(1000斤小麦)。
针对多种多样的使用场景,衍生出了很多的文件系统,有的文件系统能够提供更好的读性能,有的文件系统能提供更好的写性能。我们平时常用的文件系统如xfs、ext4是读写性能等各方面比较均衡的通用文件系统。
能否直接使用不含有文件系统块设备呢?
可以的,xfs和ext4等通用的文件系统旨在满足大多数用户的存储需求,所以在数据存储的各方面的性能比较均衡。然而,很多应用往往并不需要这种均衡,而需要突出某一方面的性能,如小文件的存储性能。此时,xfs、ext4等通用文件系统如果不能满足应用的需求,应用往往会在裸设备上实现自己的数据组织和管理方式。简单的说,就是应用为了强化某种存储特性而实现自己定制的数据组织和管理方式,而不使用通用的文件系统。
Ceph块设备接口怎么使用?
在Ceph集群中创建块设备:
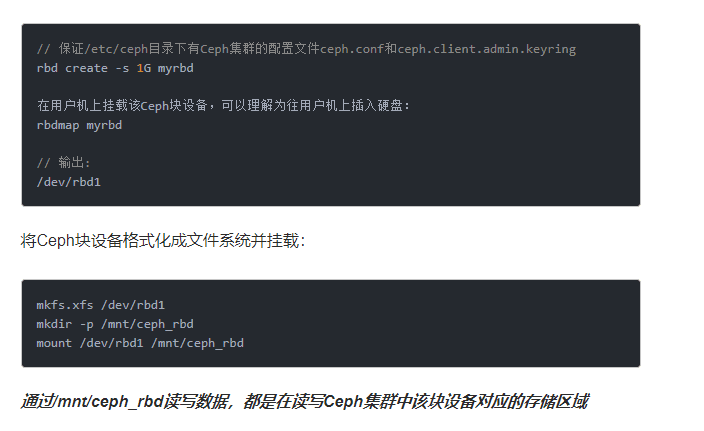
总结一下,块设备可理解成一块硬盘,用户可以直接使用不含文件系统的块设备,也可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持。
二. Ceph的文件系统存储接口
什么是Ceph的文件系统接口?
还记得上面说的块设备上的文件系统吗,用户可以在块设备上创建xfs文件系统,也可以创建ext4等其他文件系统。
如图1,Ceph集群实现了自己的文件系统来组织管理集群的存储空间,用户可以直接将Ceph集群的文件系统挂载到用户机上使用。
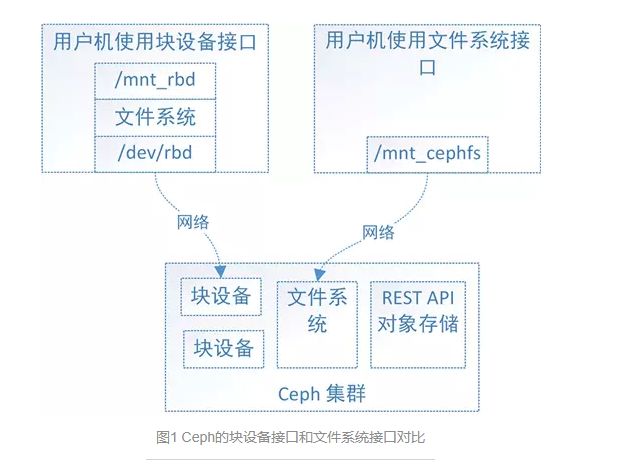
Ceph有了块设备接口,在块设备上完全可以构建一个文件系统,那么Ceph为什么还需要文件系统接口呢?
主要是因为应用场景的不同,Ceph的块设备具有优异的读写性能,但不能多处挂载同时读写,目前主要用在OpenStack上作为虚拟磁盘,而Ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性。
想了解更多?快去查查SAN和NAS。
一文看懂:NAS网络存储与SAN、DAS的区别
What is a SAN and how does it differ from NAS?
为什么Ceph的块设备接口不具有共享性,而Ceph的文件系统接口具有呢?
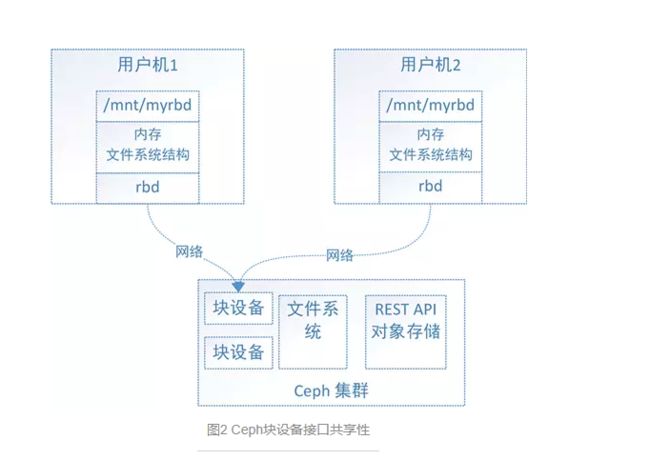
对于Ceph的块设备接口,如图2,文件系统的结构状态是维护在各用户机内存中的,假设Ceph块设备同时挂载到了用户机1和用户机2,当在用户机1上的文件系统中写入数据后,更新了用户机1的内存中文件系统状态,最终数据存储到了Ceph集群中,但是此时用户机2内存中的文件系统并不能得知底层Ceph集群数据已经变化而维持数据结构不变,因此用户无法从用户机2上读取用户机1上新写入的数据。
对于Ceph的文件系统接口,如图3,文件系统的结构状态是维护在远端Ceph集群中的,Ceph文件系统同时挂载到了用户机1和用户机2,当往用户机1的挂载点写入数据后,远端Ceph集群中的文件系统状态结构随之更新,当从用户机2的挂载点访问数据时会去远端Ceph集群取数据,由于远端Ceph集群已更新,所有用户机2能够获取最新的数据。

Ceph的文件系统接口使用方式?
将Ceph的文件系统挂载到用户机目录
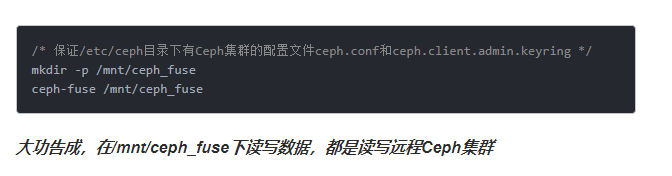
总结一下,Ceph的文件系统接口弥补了Ceph的块设备接口在共享性方面的不足,Ceph的文件系统接口符合POSIX标准,用户可以像使用本地存储目录一样使用Ceph的文件系统的挂载目录。还是不懂?这样理解吧,无需修改你的程序,就可以将程序的底层存储换成空间无限并可多处共享读写的Ceph集群文件系统。
三. Ceph的对象存储接口
首先,通过图4来看下对象存储接口是怎么用的?
简单了说,使用方式就是通过http协议上传下载删除对象(文件即对象)。
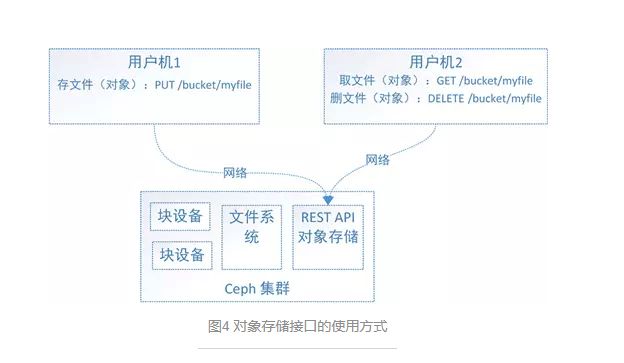
老问题来了,有了块设备接口存储和文件系统接口存储,为什么还整个对象存储呢?
往简单了说,Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共享性然而性能较块设备存储差,为什么不权衡一下存储性能和共享性,整个具有共享性而存储性能好于文件系统存储的存储呢,对象存储就这样出现了。
对象存储为什么性能会比文件系统好?
原因是多方面的,主要原因是对象存储组织数据的方式相对简单,只有bucket和对象两个层次(对象存储在bucket中),对对象的操作也相对简单。而文件系统存储具有复杂的数据组织方式,目录和文件层次可具有无限深度,对目录和文件的操作也复杂的多,因此文件系统存储在维护文件系统的结构数据时会更加繁杂,从而导致文件系统的存储性能偏低。
Ceph的对象存储接口怎么用呢?
Ceph的对象接口符合亚马逊S3接口标准和OpenStack的Swift接口标准,可以自行学习这两种接口。
Amazon S3 简介
Openstack Swift 原理、架构与 API 介绍
总结一下,文件系统存储具有复杂的数据组织结构,能够提供给用户更加丰富的数据操作接口,而对象存储精简了数据组织结构,提供给用户有限的数据操作接口,以换取更好的存储性能。对象接口提供了REST API,非常适用于作为web应用的存储。
四. 总结
概括一下,块设备速度快,对存储的数据没有进行组织管理,但在大多数场景下,用户数据读写不方便(以块设备位置offset + 数据的length来记录数据位置,读写数据)。而在块设备上构建了文件系统后,文件系统帮助块设备组织管理数据,数据存储对用户更加友好(以文件名来读写数据)。Ceph文件系统接口解决了“Ceph块设备+本地文件系统”不支持多客户端共享读写的问题,但由于文件系统结构的复杂性导致了存储性能较Ceph块设备差。对象存储接口是一种折中,保证一定的存储性能,同时支持多客户端共享读写。
五、参考
理解Ceph的三种存储接口
虚拟座谈会:有关分布式存储的三个基本问题
玩转 Ceph 的正确姿势
作者:MissHandsome
链接:https://www.jianshu.com/p/7656fe528488
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。