(34)Adaptive Learning和Feature Normalization优化

2) Adaptive Learning处理。
基于数据正则化成果的基础上,接下来我们采用Adaptive Learning进行性能优化编码。Adaptive Learning的核心在于要对收敛度进行调整,如果收敛度太慢,则把收敛度变快;如果收敛度太快,则把收敛度变慢;
由于输出的数据没有文字说明,在Neuron_Network_Entry.py程序中进行plt.plot数据可视化的时候增加相关图例说明。
……..print("Visualize the graduation of Loss in the traning process: ")plt.plot(loss_log, label = "Normal Gradient Descent Process:") #传进要进行可视化的数据集plt.legend(bbox_to_anchor = (1,1), bbox_transform=plt.gcf().transFigure)…….
运行Neuron_Network_Entry.py程序,运行结果如下:
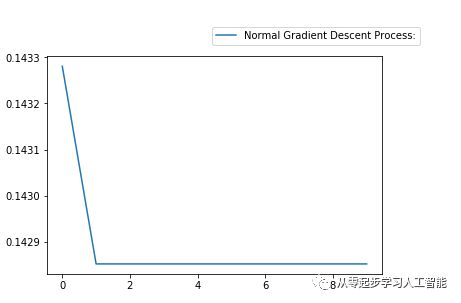
然后进行Adaptive Learning的优化。将正则化优化结果和Adaptive Learning优化结果显示出来进行比较。设置adaptive_loss_log数组,因为有很多Epoch的运行,每隔100次Epoch记录一次损失度;previous_cost 记录上一次的Loss,才能进行比较。正则化优化和Adaptive Learning优化的输入数据源都是正则化以后的数据,数据本身是一样的,但Adaptive Learning优化要将初始的权重Weight记录下来并传入。如果不记录初始Weight,进行 BackPropagation.applyBackPragation的时候权重会进行更新发生了变化。通过copy.deepcopy(weights)方式做深度拷贝,定义一个变量initial_weights记录下Neuron Network最初始的Weights。for循环遍历Epoch,将初始权重initial_weights传入,如果这次的损失度Loss小于上一次的previous_cost,说明Loss太小,则将learning_rate加大一点,这里先加上0.1,必须不断的进行尝试;如果这次的损失度Loss大于上一次的previous_cost,则将learning_rate调小一点,暂减少0.5 * learning_rate,这个调整不一定准确,调整也不一定非常有效,需在实际测试的时候不断调整,不断的去测试,因为不断循环,将当前的Loss赋值给previous_cost 。将损失度Loss追加到adaptive_loss_log数组,然后将结果进行可视化。
在Neuron_Network_Entry.py程序中修改代码如下:
……..#记录Neuron Network最初始的Weightsinitial_weights = copy.deepcopy(weights)…….adaptive_loss_log = []previous_cost = 0for i in range(epoch):nodes, initial_weights = BackPropagation.applyBackPragation(instances, nodes, initial_weights, learning_rate)loss = LossComputation.compute_loss(instances, nodes, initial_weights)if loss < previous_cost:learning_rate = learning_rate + 0.1else:learning_rate = learning_rate - 0.5 * learning_rateprevious_cost = lossif i % 100 == 0:print("Epoch " + str(i), "\t", loss)adaptive_loss_log.append(loss)plt.plot(adaptive_loss_log, label = "Adaptive Loss Log:" ) #传进要进行可视化的数据集plt.legend(bbox_to_anchor = (1,1), bbox_transform=plt.gcf().transFigure)plt.show() #显示可视化结果…….ForwardPropagation.applyForwardPropagation(nodes, initial_weights, instance)……..
运行Neuron_Network_Entry.py程序,结果如下:
Normalized Data: [[-4.0, -4.0, 0.0], [-4.0, 4.0, 1.0], [4.0, -4.0, 1.0], [4.0, 4.0, 0.0]]+1 V1 V2Hidden layer creation: 1 N[1][1] N[1][2] N[1][3] N[1][4]Output layer: OutputThe weight from 1 at layers[0] to 4 at layers[1] : 0.055769146065018926The weight from 1 at layers[0] to 5 at layers[1] : -0.13505399038496435The weight from 1 at layers[0] to 6 at layers[1] : 0.061380933948337324The weight from 1 at layers[0] to 7 at layers[1] : -0.05462732984564089The weight from 2 at layers[0] to 4 at layers[1] : 0.4697823956454532The weight from 2 at layers[0] to 5 at layers[1] : 0.006461311811961412The weight from 2 at layers[0] to 6 at layers[1] : 0.11572655831772427The weight from 2 at layers[0] to 7 at layers[1] : -0.9214359497524874The weight from 4 at layers[1] to 8 at layers[2] : 0.11216606381674765The weight from 5 at layers[1] to 8 at layers[2] : -0.49102265944483214The weight from 6 at layers[1] to 8 at layers[2] : 0.13763565486210116The weight from 7 at layers[1] to 8 at layers[2] : -0.9214942023217652Epoch 0 0.14235759446898Epoch 100 0.14491888983483653Epoch 200 0.1449188898348365Epoch 300 0.1449188898348365Epoch 400 0.14491888983483647Epoch 500 0.14491888983483647Epoch 600 0.14491888983483647Epoch 700 0.14491888983483647Epoch 800 0.14491888983483647Epoch 900 0.14491888983483647Congratulations! All Epoch is completed!!!Visualize the graduation of Loss in the traning process:Epoch 0 0.14235759446898Epoch 100 0.1430724921728433Epoch 200 0.1430724921728433Epoch 300 0.1430724921728433Epoch 400 0.1430724921728433Epoch 500 0.1430724921728433Epoch 600 0.1430724921728433Epoch 700 0.1430724921728433Epoch 800 0.1430724921728433Epoch 900 0.1430724921728433Prediction: 0.2273250229411016 while real value is: 0.0Prediction: 0.4496391575764841 while real value is: 1.0Prediction: 0.26785316975158013 while real value is: 1.0Prediction: 0.5039516181258309 while real value is: 0.0

运行结果如图所示,发现Adaptive Learning和Feature Normalization优化的效果相对比较明显。说明Adaptive Loss Log是有效的, Adaptive Loss 优化比数据正则化的优化的精确度更高,损失度更低,因此Adaptive Learning优化是有作用的。第一步是看见它的变化,表明优化程序已经可以正常工作了。从美国硅谷的见闻来看,可能这个工作比较枯燥,因为硅谷工程师们需天天调整这些参数。
本节我们编码实现了Adaptive Learning性能优化,及使用Feature Normalization进行了优化,发现Adaptive Learning和Feature Normalization优化都是有效的,因为采用这个优化和不采用这个优化,可以看到运行结果前后的对比改变。至于精确度,这是另外一个内容,我们的代码还有优化的地方,现在还没有使用。
本文根据王家林老师《5节课内从零起步(无需数学和Python基础)编码实现AI人工智能框架电子书》整理。