TensorFlow 1.0.0rc1上玩量化神经网络 ——转自 慢慢学TensorFlow 微信公众号
注
这里的量化不是指“量化交易(Quantitative trade)”,而是 Quantization ,即离散化,注意是否走错片场。
前言
开发神经网络时最大的挑战是让它真正起作用,训练时一般希望速度越快越好,准确率越高越好。使用浮点算法是保持结果精确最简单的方式,GPU 拥有加速浮点算法的库,所以很自然地,不需要过多关注其他数值格式。
最近,有很多神经网络模型投入实际应用。训练计算需求随研究者数目线性增长,但预测所需的周期与用户数目成正比。这意味着纯预测的效率成为迫在眉睫的问题。
这就是量化神经网络的用武之地。该方法包括很多不同技巧,以相对 32 位浮点更紧凑的方式对数值进行存储和计算。
本文关注 8 bit 量化,后续文章还会再讲。
量化神经网络的可行性
训练神经网络时,对权值做很多微小的改动,这些微小增量一般需要浮点精度才能正常工作(也有一些研究工作使用量化网络进行训练)。
使用预训练的模型运行预测则不同。深度网络的奇妙特性是对输入噪声容忍度很高。如果你考虑识别照片中物体,网络能忽略所有 CCD 噪声,光照变化和其他不重要的差异,而把注意力放在更重要的相似性。
该功能意味着网络可以把低精度计算作为另一种噪声源,在容纳更少信息的数值格式下仍然能产生准确的预测结果。
量化神经网络的必要性
神经网络模型可能占据大量磁盘空间,例如原始的 AlexNet (浮点格式)需要超过 200 MB。
由于一个模型中常常有数百万连接,几乎所有空间都被神经元连接的权值所占据。况且这些权值都是有些微不同的浮点数,简单的压缩格式(如 zip)不能很好地压缩。它们分布在大量层中,每层权值都趋向于某个确定区间的正态分布,例如(-3.0, 6.0)。
量化网络最初的动机是减小模型文件尺寸(用 8-bit 量化可以缩小到原来 25%),在模型载入后仍然转换回浮点数,这样你已有的浮点计算代码无需改动即可正常运行。
具体方法是在网络权值保存为文件时,将每层最小值、最大值存储下来,然后将每个浮点数值采用 8-bit 整数表示(在最大值、最小值范围内空间线性划分 256 段,每段用一个唯一的 8-bit 整数表示在该段内的实数值)。
例如,在 (-3.0, 6.0) 区间内,字节 0 表示 -3.0, 字节 255 表示 6.0, 以此类推,字节 128 表示 1.5。
另一个量化的动机是降低预测过程的计算资源需求,这时需要将完整计算都采用 8-bit 实现。该方案实施也更加困难,因为需要修改所有计算代码,同时也有更大的潜在回报。读取 8-bit 数值只需要相对浮点数值 25% 内存带宽,你可以更好利用 caches,避免访存瓶颈。你也可以使用 SIMD 指令,在一个时钟周期内实现更多计算。一些情况下你还可以用 DSP 芯片加速 8-bit 计算。
将计算移植到 8-bit 可以帮助你更快地运行模型,功耗更低(在移动设备上尤其重要)。它也打开了一扇通向大量不能高效运行浮点计算代码的嵌入式系统的大门,让物联网世界大量应用成为可能。
为什么不直接用低精度训练?
有一些实验使用低位宽进行训练,但结果显示需要使用高于 8-bit 来处理反向传播梯度值。这使得实现训练异常复杂,从纯预测开始是合理的。我们也有很多训练好的浮点模型,用得多了自然十分了解,将它们直接转换格式是非常方便的。
如何量化你的模型
TensorFlow 在产品级别内在支持 8-bit 计算。它也有一个将用浮点训练好的模型转换为等效的利用量化算法进行预测的图。
例如,你可以将最新 GoogLeNet 模型转换为 8-bit 计算:
$ curl http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz -o /tmp/inceptionv3.tgz
$ tar xzf /tmp/inceptionv3.tgz -C /tmp/
$ cd ~/tensorflow-1.0.0-rc1/
$ bazel build tensorflow/tools/quantization:quantize_graph
$ bazel-bin/tensorflow/tools/quantization/quantize_graph \
--input=/tmp/classify_image_graph_def.pb \
--output_node_names="softmax" \
--output=/tmp/quantized_graph.pb \
--mode=eightbit
运行截图见下图所示:

这样将会产生一个新模型 quantized_graph.pb,与原始模型运行相同计算,但内部使用 8-bit 计算,所有权值也做 8-bit 量化。
如果你注意文件尺寸,会发现它只有原先模型的 1/4 ( 23MB vs 91 MB)。
你仍然可以运行这个模型使用几乎相同输入和输出,并获得等价的结果。下面是例子:
$ bazel build tensorflow/examples/label_image:label_image
$ bazel-bin/tensorflow/examples/label_image/label_image \
--image=
--graph=/tmp/quantized_graph.pb \
--labels=/tmp/imagenet_synset_to_human_label_map.txt \
--input_width=299 \
--input_height=299 \
--input_mean=128 \
--input_std=128 \
--input_layer="Mul:0" \
--output_layer="softmax:0"
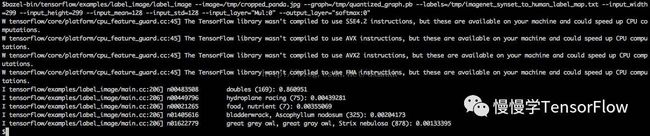
用原始模型运行结果如图所示:
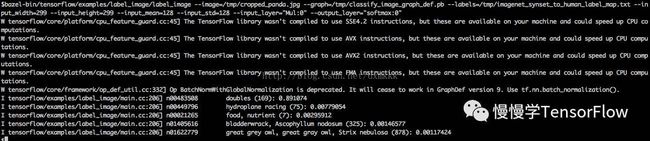
你会看到新量化的图,输出与原始模型非常近似的结果。
量化过程是怎样的
TF 已经通过编写等价的预测时常用的 8-bit 版本运算符实现了量化计算,这些运算符包括卷积、矩阵乘、激活函数、下采样和拼接。转换脚本首先替换所有已知的运算符为等价的量化运算符。
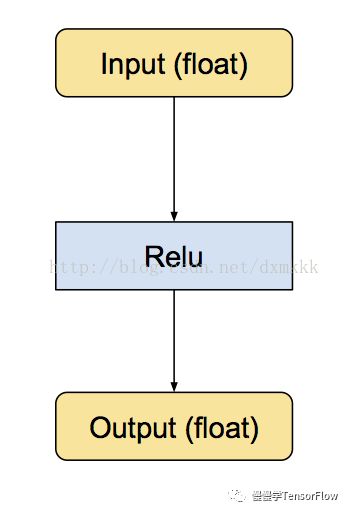
小的子图在输入和输出部分有转换函数实现浮点到 8-bit 的转换。以下是一个例子,展示了它们的模样。
首先是原始的 Relu 运算符,具有浮点输入和输出:
接下来是等价的转换后的子图,仍然为浮点输入和输出,但内部转换为 8-bit,这样所有计算都是以 8-bit 实现:
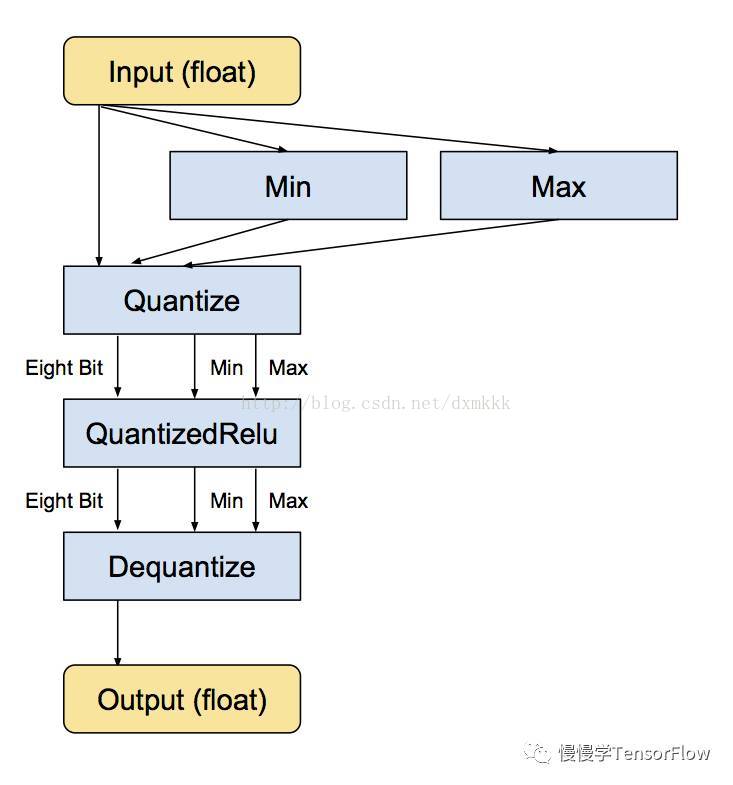
最小和最大值运算符实际上是根据输入浮点值进行计算,之后送入 Quantize 运算符将输入张量转换为 8-bit。
每个独立运算符转换完毕,下一步是去除不必要的转换。如果存在一串连续的浮点运算符,它们都以浮点张量传递结果,那么会存在大量相邻的 反量化/量化运算符。在该步检测以上情形,识别出彼此可以抵消,之后便删除这些不必要的步骤,如下图所示:
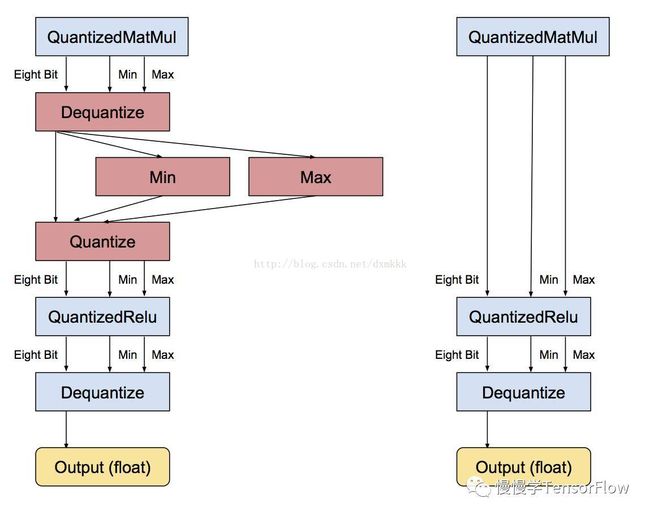
应用到大规模模型,所有运算符都有量化版本,可以实现一张全部张量计算都以 8-bit 实现的图,无需转换回浮点。
内容译自: https://www.tensorflow.org/versions/r1.0/how_tos/quantization/
部分图片来源:https://petewarden.com/2016/05/03/how-to-quantize-neural-networks-with-tensorflow/
微信扫描下面二维码关注此公众号!
