环境
- VirtualBox 6.1
- IntelliJ IDEA 2020.1.1
- Ubuntu-18.04.4-live-server-amd64
- jdk-8u251-linux-x64
- hadoop-2.7.7
安装伪分布式Hadoop
安装伪分布式参考:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)
这里就不再累述,注意需要安装yarn。
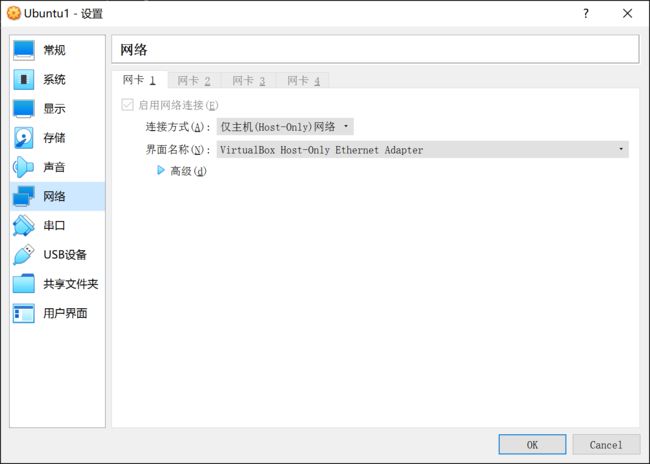
还就是我使用的是仅主机网络模式。
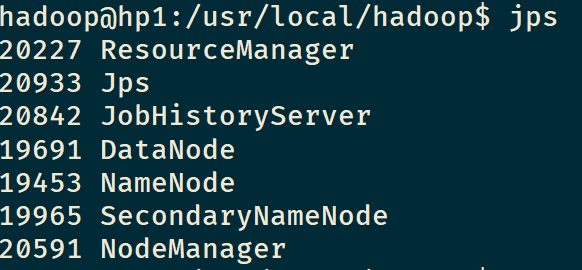
启动成功后,使用jps,显示应该有以下几项:
修改配置
首先使用ifconfig查看本机IP,我这里是192.168.56.101,下面将使用该IP为例进行展示。
修改core-site.xml,将localhost改为服务器IP
fs.defaultFS
hdfs://192.168.56.101:9000
修改mapred-site.xml,添加mapreduce.jobhistory.address
mapreduce.jobhistory.address
192.168.56.101:10020
不添加这项,会报如下错
[main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: 0.0.0.0/0.0.0.0:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
修改yarn-site.xml,添加如下项
yarn.resourcemanager.address
192.168.56.101:8032
yarn.resourcemanager.scheduler.address
192.168.56.101:8030
yarn.resourcemanager.resource-tracker.address
192.168.56.101:8031
如果不添加,将会报错
INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
配置完成后,需要重启dfs、yarn和historyserver。
配置Windows的Hadoop运行环境
首先把Linux中的hadoop-2.7.7.tar.gz解压到Windows的一个目录,本文中是D:\ProgramData\hadoop
然后配置环境变量:
HADOOP_HOME=D:\ProgramData\hadoop
HADOOP_BIN_PATH=%HADOOP_HOME%\bin
HADOOP_PREFIX=D:\ProgramData\hadoop
另外,PATH变量在最后追加;%HADOOP_HOME%\bin
然后去下载winutils,下载地址在https://github.com/cdarlint/winutils,找到对应版本下载,这里下载的2.7.7版本。
将winutils.exe复制到$HADOOP_HOME\bin目录,将hadoop.dll复制到C:\Windows\System32目录。
编写WordCount
首先创建数据文件wc.txt
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
hello world
dog fish
hadoop
spark
然后移动到Linux中去,在使用hdfs dfs -put /path/wc.txt ./input将数据文件放入到dfs中
然后使用IDEA新建maven项目,修改pom.xml文件
4.0.0
org.example
WordCount
1.0-SNAPSHOT
aliyun
aliyun
https://maven.aliyun.com/repository/central/
true
false
org.apache.hadoop
hadoop-common
2.7.7
org.apache.hadoop
hadoop-mapreduce-client-jobclient
2.7.7
log4j
log4j
1.2.17
commons-cli
commons-cli
1.2
commons-logging
commons-logging
1.1.1
${project.artifactId}
接着就是编写WordCount程序,这里我参考的是
https://www.cnblogs.com/frankdeng/p/9256254.html
然后修改一下WordcountDriver.
package cabbage;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于一个yarn集群的客户端,
* 需要在此封装我们的mr程序相关运行参数,指定jar包
* 最后提交给yarn
*/
public class WordcountDriver {
/**
* 删除指定目录
*
* @param conf
* @param dirPath
* @throws IOException
*/
private static void deleteDir(Configuration conf, String dirPath) throws IOException {
FileSystem fs = FileSystem.get(conf);
Path targetPath = new Path(dirPath);
if (fs.exists(targetPath)) {
boolean delResult = fs.delete(targetPath, true);
if (delResult) {
System.out.println(targetPath + " has been deleted sucessfullly.");
} else {
System.out.println(targetPath + " deletion failed.");
}
}
}
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
System.setProperty("hadoop.home.dir", "D:\\ProgramData\\hadoop");
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("fs.default.name", "hdfs://192.168.56.101:9000");
configuration.set("mapreduce.app-submission.cross-platform", "true");//跨平台提交
configuration.set("mapred.jar","D:\\Work\\Study\\Hadoop\\WordCount\\target\\WordCount.jar");
// 8 配置提交到yarn上运行,windows和Linux变量不一致
// configuration.set("mapreduce.framework.name", "yarn");
// configuration.set("yarn.resourcemanager.hostname", "node22");
//先删除output目录
deleteDir(configuration, args[args.length - 1]);
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
// job.setJar("/home/admin/wc.jar");
job.setJarByClass(WordcountDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setCombinerClass(WordcountReducer.class);
job.setReducerClass(WordcountReducer.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
// job.submit();
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
关键代码
System.setProperty("HADOOP_USER_NAME", "hadoop");
如果不添加这行,会导致权限报错
org.apache.hadoop.ipc.RemoteException: Permission denied: user=administration, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
如果修改了还是报错,可以考虑将文件权限修改777
这里我主要参考一下几篇文章
https://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
https://blog.csdn.net/jzy3711/article/details/85003606
System.setProperty("hadoop.home.dir", "D:\\ProgramData\\hadoop");
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("fs.default.name", "hdfs://192.168.56.101:9000");
configuration.set("mapreduce.app-submission.cross-platform", "true");//跨平台提交
configuration.set("mapred.jar","D:\\Work\\Study\\Hadoop\\WordCount\\target\\WordCount.jar");
如果不添加这行会报错
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class cabbage.WordcountMapper not found
这里我主要参考了
https://blog.csdn.net/u011654631/article/details/70037219
//先删除output目录
deleteDir(configuration, args[args.length - 1]);
output每次运行时候不会覆盖,如果不删除会报错,这里应该都知道。
添加依赖
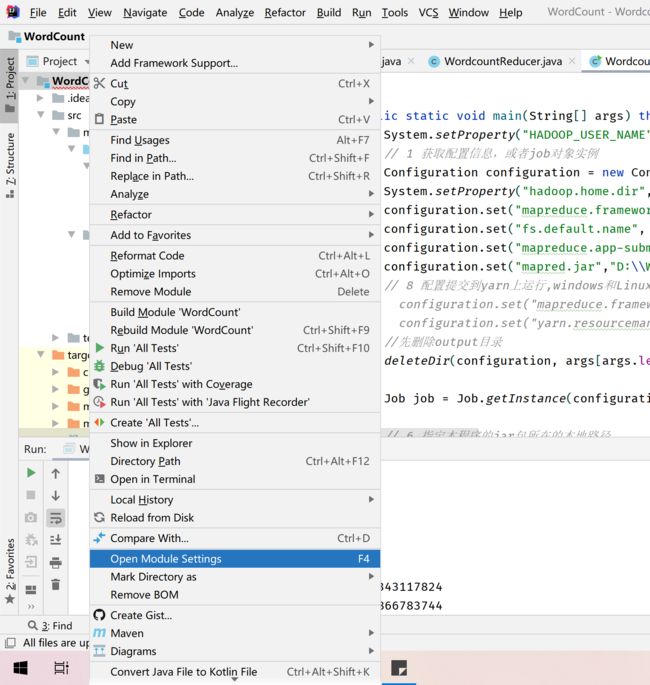
然后添加依赖的Libary引用,项目上右击 -> Open Module Settings 或按F12,打开模块属性
然后点击Dependencies->右边的加号->Libray
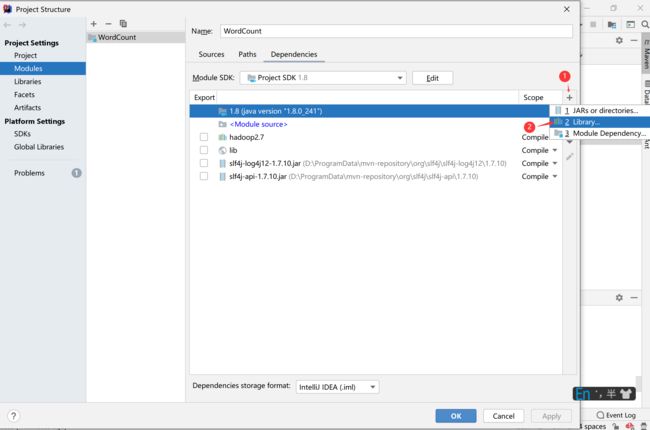
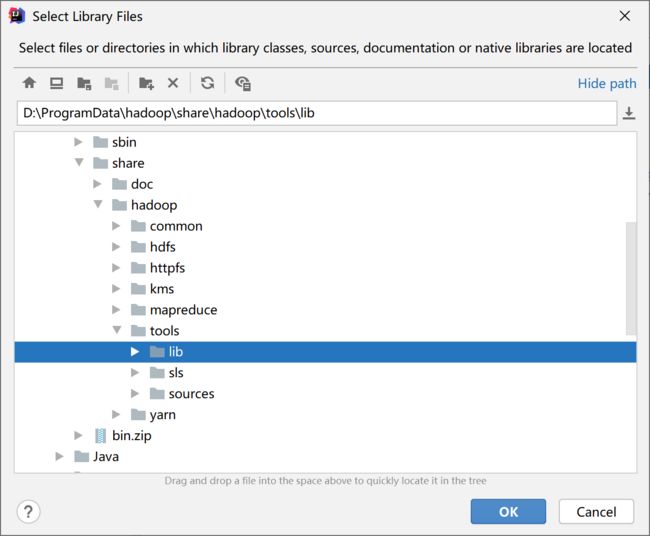
接着把$HADOOP_HOME下的对应包全导进来

然后再导入$HADOOP_HOME\share\hadoop\tools\lib
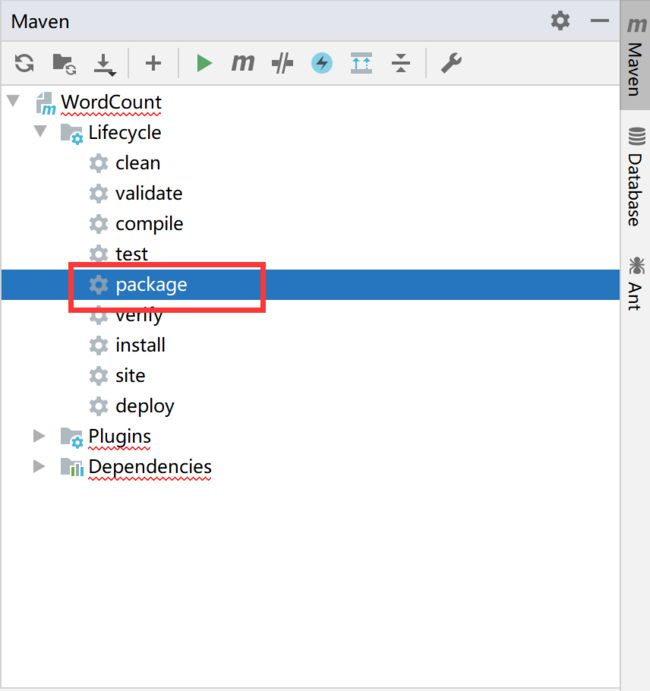
然后使用maven的package打包jar包
添加resources
在resources中新建log4j.properties,添加如下内容
log4j.rootLogger=INFO, stdout
#log4j.logger.org.springframework=INFO
#log4j.logger.org.apache.activemq=INFO
#log4j.logger.org.apache.activemq.spring=WARN
#log4j.logger.org.apache.activemq.store.journal=INFO
#log4j.logger.org.activeio.journal=INFO
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n
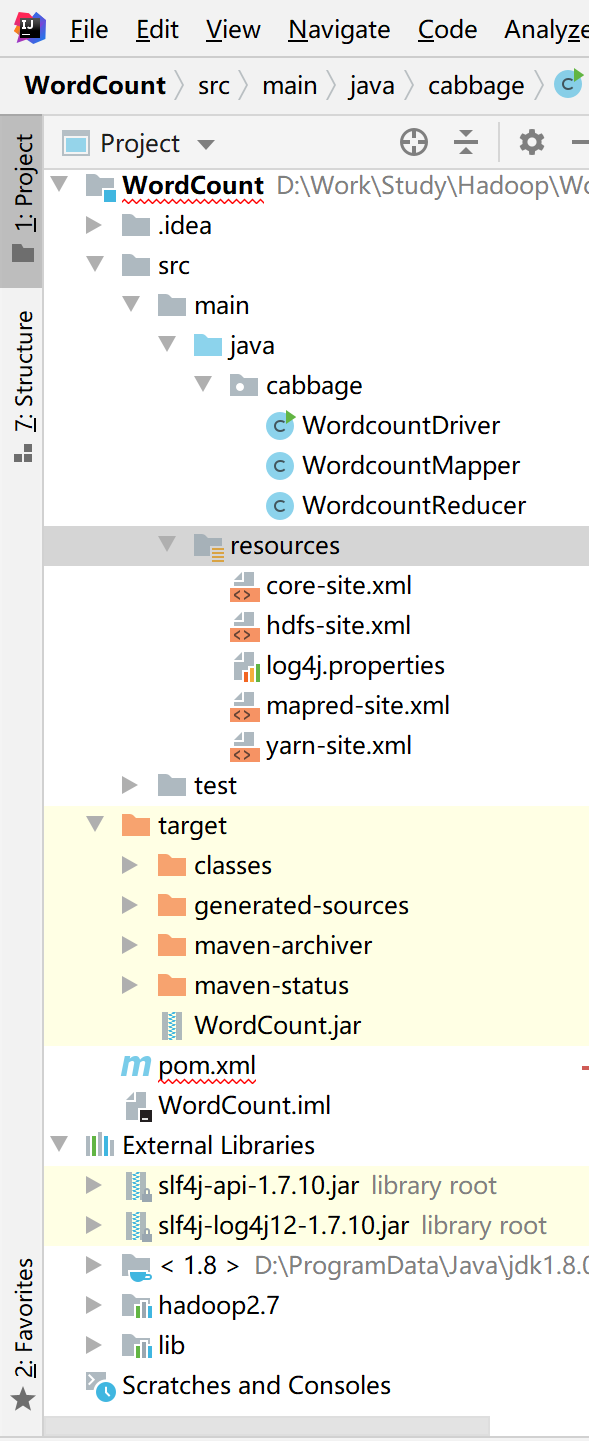
然后再把Linux里面的core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml移动过来,最后的项目结构如下图
配置IDEA
上面配置完了,就可以设置运行参数了
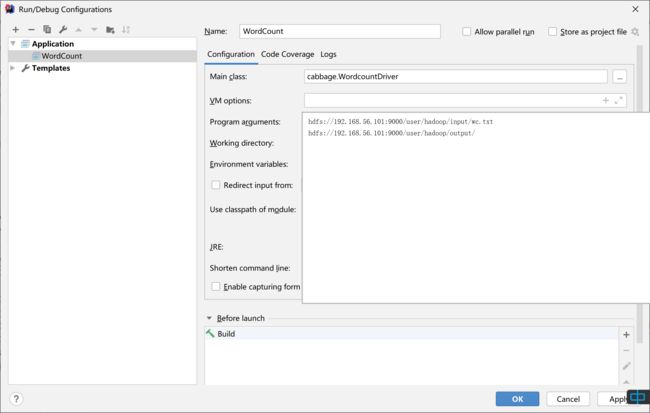
注意两个地方
-
Program aguments,指定输入文件和输出文件夹,注意是
hdsf://ip:9000/user/hadoop/xxx -
Working Directory,即工作目录,指定为$HADOOP_HOME所在目录
运行
点击运行即可,如果报错说缺少依赖,比如我就报错缺少slf4j-log这个包,然后就自己添加到依赖里面就行了。
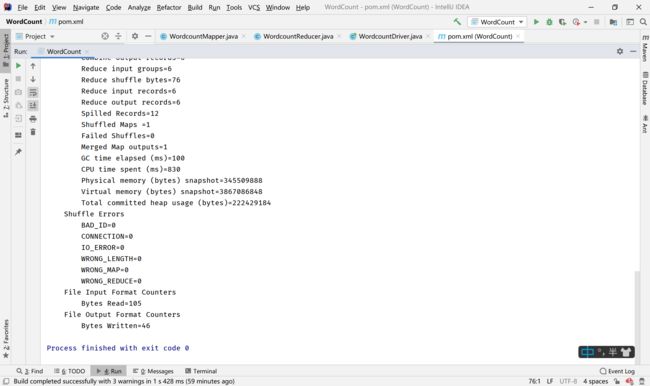
运行完成后IDEA显示如下图:
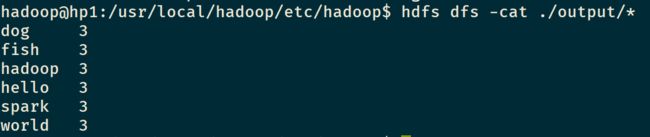
然后再output文件中看看输出结果,在Linux里面输入hdfs dfs -cat ./output/*,显示如下结果,就正确了。
如果有什么问题,可以再评论区提出来,一起讨论;)。
参考
- http://dblab.xmu.edu.cn/blog/install-hadoop/
- https://blog.csdn.net/u011654631/article/details/70037219
- https://www.cnblogs.com/yjmyzz/p/how-to-remote-debug-hadoop-with-eclipse-and-intellij-idea.html
- https://www.cnblogs.com/frankdeng/p/9256254.html
- https://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
- https://blog.csdn.net/djw745917/article/details/88703888
- https://www.jianshu.com/p/7a1f131469f5