ELK实战(一)Filebeat+Logstash发送Email告警日志(1)
ELK实战(一)Filebeat+Logstash发送Email告警日志(1)
- ELK应用案例
- 典型ELK应用架构
- 本次我使用的架构(Filebeat+Logstash发送Email告警日志)
- 使用的Filebeat+Logstash版本介绍,包括jdk。
- Filebeat配置文件讲解(filebeat.yml)
- Logstash配置文件讲解(logstash.conf)
- 邮件收到的具体信息如下
- 总结
- 目前本人使用的这套架构已经投入生产环境,总的来说使用情况只过滤ERROR级别日志,以及日志数据量不是特别大的情况下,可以满足日常告警需求,如果是日志量比较大的系统,请慎用以上架构,为了保证您的系统安全稳定,以上教程仅仅给您提供参考,具体要结合实际的生产环境进行配置和开发。
ELK应用案例
最近项目中有这样一个需求,需要搜集应用服务器的日志,并把日志中包含ERROR的错误信息采集并通过邮件的方式发送给开发人员,这个需求可以通过多种方式实现,比如说把发邮件的代码嵌入到系统中,如果报错就立马调用邮件发送的接口,还有一种就是通过日志监控的方式发邮件,在这里我使用Filebeat+Logstash来实现这么一个需求,首先我们看下目前比较经典的ELK架构网络拓扑,然后我在介绍下我自己目前使用的网络拓扑。
典型ELK应用架构

这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
- 第一层、数据采集层 ,数据采集层位于最左边,在每个应用服务器上部署Filebeat做日志采集,然后把采集到的日志信息发送到Kafka+zookeeper集群上 ;
- 第二层 、消息队列层 ,日志发送到Kafka+zookeeper集群上,会进行集中存储,此时,Filebeat是消息的生产者,存储的消息可以随时被消费。;
- 第三层、数据分析层 logstash作为消费者,会去Kafka+zookeeper集群上实时拉取采集的日志信息,然后将获取到的日志根据规则进行分析、清晰、过滤,最后将清洗好的日志转发到Elasticsearch集群。
- 第四层、数据持久化存储层, Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引等才做,最后将结构化的数据存储起来。;
- 第五层、数据查询、展示层 Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化和多维度分析。
- 总结, 这个架构是ELK非常经典的一种处理大规模数据的架构,由于业务系统每天产生的日志信息量比较大,所以在Filebeat和Logasth之间加了一层Kafka+zookeeper的消息队列层,目的就是为了让logstash能够根据自己的处理数据的能力来拉取数据,不至于logstash处理不过来,如果Filebeat直接发送信息到logstash很有可能在数据量比较大的情况下导致logstash崩溃或者数据丢失,放入kafka集群就是为了缓冲大数据量,同时保证数据不丢失。
本次我使用的架构(Filebeat+Logstash发送Email告警日志)
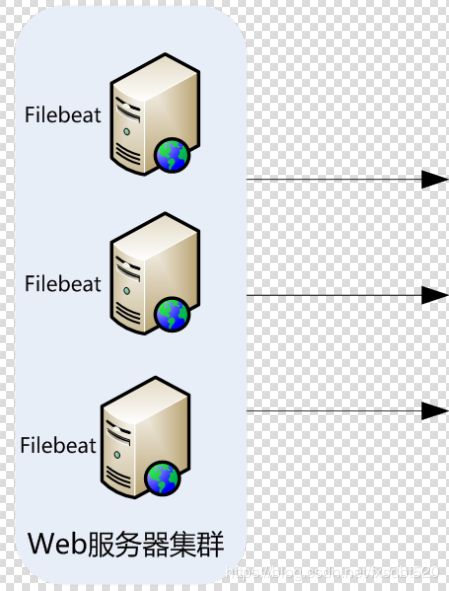

- 第一层、数据采集层 ,数据采集层位于最左边,在每个应用服务器上部署Filebeat做日志采集,然后把采集到的日志信息直接发送到logstash ;
- 第二层、数据分析层 ,logstash接受到Filebeat采集的错误日志后,将信息根据规则进行清洗、加工,然后将清洗后的数据通过Email的方式发送给开发人员;
- 总结,我这里并没有使用经典的ELK架构进行日志采集分析,由于目前应用服务器只有两台,并且每天产生的日志量并不是特别大,Filebeat发送的日志信息仅仅包含ERROR错误信息,并没有采集完整的日志信息,所以中间去掉了消息队列层,当然也可以加上消息队列层,这样对整个ELK架构来说是比较稳定的。不过,处于快速完成需求,检索错误日志发送邮件,在数据量比较小的情况下,以上这套架构可以满足需求,后续我会介绍完整的ELK经典架构 。
使用的Filebeat+Logstash版本介绍,包括jdk。
| 软件名称 | 版本 | 说明 |
|---|---|---|
| JDK | JDK1.8.0_60 | Java环境解析器 |
| Filebeat | filebeat-6.4.2-linux-x86_64 | 前端日志搜集器 |
| Logstash | logstash-6.4.2 | 日志收集、过滤、转发 |
| 操作系统 | Linux Centos 7.X | Linux 3.10.0-693.2.2.el7.x86_64 #1 SMP Tue Sep 12 22:26:13 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux |
Filebeat配置文件讲解(filebeat.yml)
本文是针对对ELK技术有所了解得开发运维人员进行介绍,相关的ELK程序安装以及原理讲解这里不做过多赘述,一上来就直接刚代码,对于急需要解决这个需求的人员来说非常有帮助,废话不多说,请看我的filebeat配置
filebeat:
prospectors:
# 指定数据的输入类型,这里是log
- input_type: log
# 启用手工配置filebeat,而不是采用模块方式配置filebeat
enabled: true
# 从日志最后一行开始读取,设置为true类似,linux的tail命令,从文件的最后一行读取
tail_files: true
paths:
- /mnt/log/app_server/XXXXXXX/*.log
include_lines: ['ERROR'] #日志中如果有"error"关键字的日志,进行多行合并
multiline.pattern: '^\[XY\]\s*(\d{4}|\d{2})\-(\d{2}|[a-zA-Z]{3})\-(\d{2}|\d{4})' # 指定匹配的表达式(匹配以[XY] 2017-11-15 08:04:23:889
multiline.negate: true # 是否匹配到,默认false
multiline.match: after # 合并到上一行的末尾
#要删除的字段
processors:
- drop_fields:
fields: ["beat", "offset"]
#设置filebeat收集的日志中对应主机的名字,如果配置为空,则使用该服务器的主机名。这里设置为IP,便于区分多台主机的日志信息。
name: xx.xx.xx.xx
#输出到elasticsearch
#output:
# elasticsearch:
# hosts: ["127.0.0.1:9200"]
#输出到logstash
output:
logstash:
hosts: ["127.0.0.1:5044"]
#output:
# console:
# pretty: true
#定义filebeat的日志输出级别,有critical、error、warning、info、debug五种级别可选,在调试的时候可选择debug模式。
logging.level: info
错误日志:
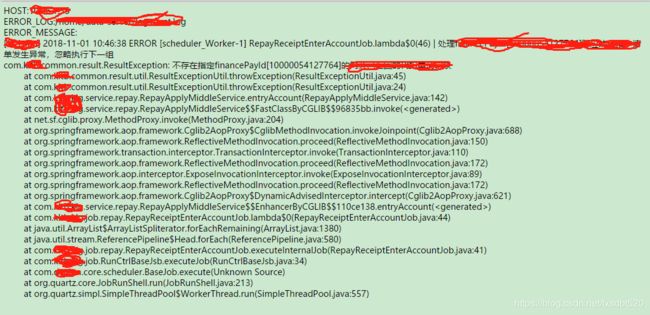
[XY] 2018-11-01 10:46:38 INFO [scheduler_Worker-1] RepayApplyService.findAllRepayApply(60) | 结束查找申请单记录,LoanRepayApplyList[[]]
[JL_Loan] 2018-11-01 10:46:38 ERROR [scheduler_Worker-1] RepayReceiptEnterAccountJob.lambda$0(46) 发生异常,忽略执行下一组
com.xxx.common.result.ResultException: 不存在指定
at com.xxx.common.result.util.ResultExceptionUtil.throwException(ResultExceptionUtil.java:45)
at com.xxx.common.result.util.ResultExceptionUtil.throwException(ResultExceptionUtil.java:24)
at com.xxx.xxx.service.repay.RepayApplyMiddleService.entryAccount(RepayApplyMiddleService.java:142)
at com.xxx.xxx.service.repay.RepayApplyMiddleService$$FastClassByCGLIB$$96835bb.invoke()
at net.sf.cglib.proxy.MethodProxy.invoke(MethodProxy.java:204)
at org.springframework.aop.framework.Cglib2AopProxy$CglibMethodInvocation.invokeJoinpoint(Cglib2AopProxy.java:688)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:110)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:89)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.Cglib2AopProxy$DynamicAdvisedInterceptor.intercept(Cglib2AopProxy.java:621)
at com.xxx.service.repay.RepayApplyMiddleService$$EnhancerByCGLIB$$110ce138.entryAccount()
[XY] 2018-11-01 10:46:38 INFO [scheduler_Worker-1] RepayApplyMiddleService.entryAccount(137) |
配置文件关键点讲解
1、multiline.pattern: ‘^[XY]\s*(\d{4}|\d{2})-(\d{2}|[a-zA-Z]{3})-(\d{2}|\d{4})’
指定匹配的表达式(匹配以[XY] 2017-11-15 08:04:23:889)开头的日志
2、multiline.negate: true # 是否匹配到,默认false
multiline.match: after # 合并到上一行的末尾
3、include_lines: [‘ERROR’] #日志中如果有"error"关键字的日志,进行多行合并
4、以上这三个是关键点,也就是匹配日志中以[JL_Loan] 2017-11-15 08:04:23:889开头,并且包含ERROR的日志,合并这些内容,知道下一个ERROR出现为止。
5、总的来说也就是三步曲,第一步匹配以什么开头的日志,第二步,把匹配到的日志中需要包含某个关键字的内容进行合并。第三步定义合并的开始和结束。最后将匹配到的日志信息output到logstash。
其他配置介绍
filebeat.inputs:用于定义数据原型。
type:指定数据的输入类型,这里是log,即日志,是默认值,还可以指定为stdin,即标准输入。
paths:用于指定要监控的日志文件,可以指定一个完整路径的文件,也可以是一个模糊匹配格式,例如:
- /data/nginx/logs/nginx_*.log,该配置表示将获取/data/nginx/logs目录下的所有以.log结尾的文件,注意这里有个破折号“-”,要在paths配置项基础上进行缩进,不然启动filebeat会报错,另外破折号前面不能有tab缩进,建议通过空格方式缩进。
- /var/log/*.log,该配置表示将获取/var/log目录的所有子目录中以”.log”结尾的文件,而不会去查找/var/log目录下以”.log”结尾的文件。
name: 设置filebeat收集的日志中对应主机的名字,如果配置为空,则使用该服务器的主机名。这里设置为IP,便于区分多台主机的日志信息。
logging.level:定义filebeat的日志输出级别,有critical、error、warning、info、debug五种级别可选,在调试的时候可选择debug模式。
启动filebeat脚本
nohup /home/elk/filebeat/filebeat -e -c /home/elk/filebeat/filebeat.yml >> /home/elk/logs/filebeat/filebeat.log 2>> /home/elk/logs/filebeat/filebeat.log &
如果匹配到错入日志,则filebeat会输出如下内容
{
"source" => "/mnt/log/app_server/XX_XX_X_XX/catalina.out.2018-11-06.log",
"host" => {
"name" => "10.36.1.50"
},
"@version" => "1",
"message" => "[XY] 2018-11-06 12:05:48 ERROR [messageListenerContainer-1] MessageEngine.sendMail(?) | Mail server connection failed; nested exception is javax.mail.MessagingException: Could not connect to SMTP hos
t: smtp.126.com, port: 25;\n nested exception is:\n\tjava.net.ConnectException: Connection timed out (Connection timed out). Failed messages: javax.mail.MessagingException: Could not connect to SMTP host: smtp.126.com, port:
25;\n nested exception is:\n\tjava.net.ConnectException: Connection timed out (Connection timed out)",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"@timestamp" => 2018-11-06T04:05:58.857Z
}
filebeat输出内容讲解
从这个输出可以看到,输出日志被修改成了JSON格式,日志总共分为10个字段,分别是"@timestamp"、"@metadata"、"beat"、"host"、"source"、"offset"、"message"、"prospector"、"input"和"fields"字段,每个字段含义如下:
@timestamp:时间字段,表示读取到该行内容的时间。
@metadata:元数据字段,此字段只有是跟Logstash进行交互使用。
beat:beat属性信息,包含beat所在的主机名、beat版本等信息。
host: 主机名字段,输出主机名,如果没主机名,输出主机对应的IP。
source: 表示监控的日志文件的全路径。
offset: 表示该行日志的偏移量。
message: 表示真正的日志内容。
prospector:filebeat对应的消息类型。
input:日志输入的类型,可以有多种输入类型,例如Log、Stdin、redis、Docker、TCP/UDP等
通过filebeat接收到的内容,默认增加了不少字段,但是有些字段对数据分析来说没有太大用处,所以有时候需要删除这些没用的字段,在filebeat配置文件中添加如下配置,即可删除不需要的字段:
processors:
- drop_fields:
fields: ["beat", "input", "source", "offset"]
这个设置表示删除"beat"、"input"、"source"、"offset" 四个字段,其中, @timestamp 和@metadata字段是不能删除的。做完这个设置后,再次查看kafka中的输出日志,已经不再输出这四个字段信息了。
Logstash配置文件讲解(logstash.conf)
本文是针对对ELK技术有所了解得开发运维人员进行介绍,相关的ELK程序安装以及原理讲解这里不做过多赘述,一上来就直接刚代码,对于急需要解决这个需求的人员来说非常有帮助,废话不多说,请看我的logstash配置
input {
beats {
host => '127.0.0.1'
port => 5044
}
}
filter {
grok {
match => ["message", "%{TIMESTAMP_ISO8601:logdate}"]
}
}
output{
# stdout{
# codec=>rubydebug
# }
email {
port =>"25" # 邮件smtp服务器发送的端口,如果是使用阿里云服务器,记得需要申请开通25端口,需要人工审核。
address =>"smtp.exmail.qq.com" # smtp服务器地址
username =>"[email protected]" # 邮箱登录名
password =>"123456" #邮箱登录密码
authentication =>"plain" #默认planin即可
use_tls => false #不使用ssl发送邮件,如果使用则设置为true,那么端口就不是25,一般是456或者987,具体根据邮件服务商提供的stmp服务器端口填写即可
from =>"[email protected]" #跟上面邮箱登录名保持一致即可
subject =>"IP:%{[host][name]},DATE:%{logdate},Warning: you have an error!" #发送的具体标题,%{[host][name]}表示取logstash最终输出中host节点下面name字段的值,%{logdate}就是取之前在filter插件中使用grok正则表达式获得的系统时间。
to =>"[email protected]" # 表示需要发送的目标邮箱地址,如果需要发送给多个邮箱地址,则逗号分隔即可
via =>"smtp" # 通过smtp服务器进行发送
body =>"[app_server]HOST:%{[host][name]}\nERROR_LOG:%{source}\nERROR_MESSAGE:\n%{message}" #表示发送的具体内容,logstash取变量的表达式都是一个百分号然后加上一个大括号%{},大括号里面写变量值即可。
}
}
配置文件关键点讲解
1、input插件监控本机5044端口,对应filebeat发送日志的端口即可。
2、filter插件使用grok正则表达式,匹配日志中[XY] 2018-11-06 12:05:48 ,2018-11-06 12:05:48这条记录的打印时间,确定错误信息发生的时间,grok表达式中内置了很多正则,大家可以去学习下grok正则表达式。 match => [“message”, “%{TIMESTAMP_ISO8601:logdate}”]这句话的意思表示匹配到日志中的系统时间,最后输出到logdate字段。如果将logstash输出到控制台,则最后输出的字段包含"logdate" => “2018-11-06 11:57:19”。
3、Email插件,output里面包含一个Email,表示最终输出到Email,也就是说如果logstash匹配到错误日志之后,经过加工清洗,最终发一封邮件出去。Email中所有的字段就是配置Email信息。
4、总的来说也就是三步曲,第一步定义input输入源,信息来源就是filebeat,监听一个端口即可,第二步,把发送过来的日志进行过滤清洗,一般是通过判断,并且使用正则表达式匹配到想要的内容,然后输出到某个固定字段。第三步定义output输出,可以输出到elasticsearch、文件、邮件、等等。
启动logstash脚本
nohup /home/elk/logstash/bin/logstash -f /home/elk/logstash/config/logstash.conf >> /home/elk/logs/logstash/logstash.log 2>> /home/elk/logs/logstash/logstash.log &
生产logstash配置调优(logstash.yml、jvm.options)
当前,在云上的logstash节点所使用的机器是4c8g的配置。对应的,在logstash的配置方面:
lostash.yml:
pipeline.workers: 2 (不配置的情况下,默认是系统核数,该参数可控制output或filter插件的工作线程数(只能设置正整数),当发现事件正在备份或CPU没有饱和,则可以增加工作线程,以提高性能。)
pipeline.output.workers: 2 (不配置的情况下,默认是1/2系统核数,批处理的最大等待值,input需要按照batch处理的最大值发送到消息队列,但是不能一直等,所以需要一个最大的超时机。)
jvm.options:
-Xms2g
-Xmx2g
邮件收到的具体信息如下