我是怎么用大数据分析预测航班延误的?(上)

导 语
根据HBR的Thomas Davenport的说法,分析技术在过去十年中发生了巨大的变化,通过商用服务器、流分析和经过优化的机器学习技术实现更强大,更便宜的分布式计算,使公司能够存储和分析更多不同类型的数据。Werner Vogel在他最近发表的主题演讲中指出,如今关键技术的驱动因素是数据、物联网(IoT)和机器学习。
利用来自物联网需要实时处理的大量数据,使用机器学习为它增值,并具有可扩展的快速存储。本文是一系列讨论端到端应用程序架构的博客中的第一篇,该应用程序将流数据与机器学习和快速存储相结合。通过本文,我将帮助您开始使用Apache Spark的机器学习管道和决策树分类器来预测航班延误。本博客也是对以前的Apache Spark机器学习教程的更新,该教程使用了基于Spark RDD的API。

在电子书《 Machine Learning Logistics and Streaming Architecture》中更详细地讨论了这类应用程序的体系结构。

什么是机器学习?
机器学习使用算法来查找数据中的模式,然后使用识别这些模式的模型对新数据进行预测。
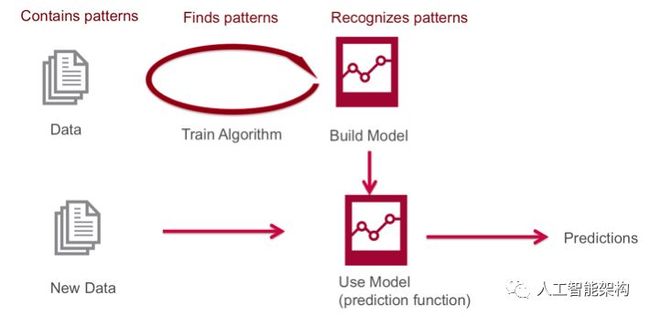
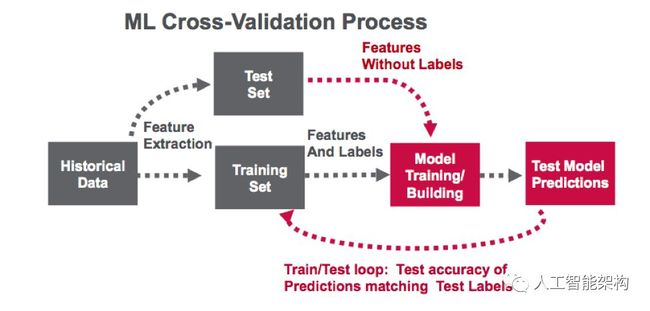
通常有两个阶段的机器学习和实时数据:
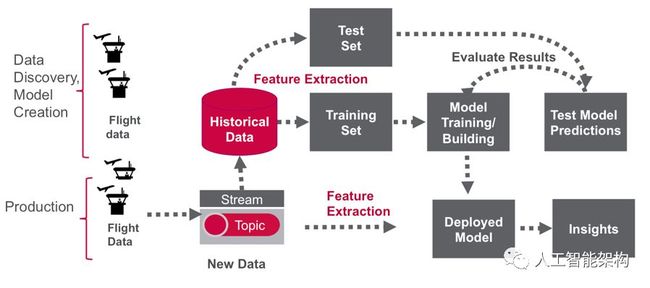
数据发现:第一阶段,主要是分析历史数据以构建机器学习模型.
使用模型的分析:第二阶段,在实时事件中使用该模型。(注意:Spark提供了一些流媒体机器学习算法,但仍经常需要对历史数据进行分析.)
通常,机器学习可以分为三种类型:监督学习、无监督学习和半监督学习。
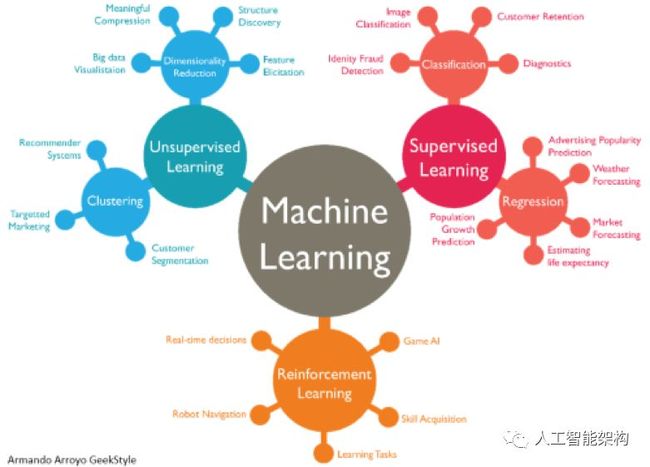
监督学习算法使用有标记的数据,其输入和目标结果都经过标记提供给了算法。

监督学习也称为:预测建模或预测分析,因为我们构建了一个能够进行预测的模型。
无监督学习算法是在为标记的数据中找到模式。
半监督学习使用标记和未标记数据的混合。强化学习训练算法是基于反馈最大化奖励。
三种机器学习技术
机器学习技术的三种常见类别有:分类、聚类和协同过滤。

分类(Classification):Gmail使用了称为分类的机器学习技术,根据电子邮件的发件人,收件人,主题和邮件正文等数据判断电子邮件是否为垃圾邮件。分类采用已知标签的一组数据,并学习如何基于这些信息标记新记录。
群集(Clustering):Google新闻使用一种称为群集的技术,根据标题和内容将新闻文章分组到不同的类别。聚类算法发现数据集合中出现的分组。
协同过滤(Collaborative filtering):亚马逊使用称为协同过滤(通常称为推荐)的机器学习技术,根据用户的历史记录和与其他用户的相似性来确定用户会喜欢哪些产品。
在本文介绍的例子中,我们将使用监督学习算法来分类航班延误。
分 类
分类是一系列受监督的机器学习算法,它是基于已知项目的标记示例(即,已知为欺诈交易)来识别项目属于哪个类别(即,交易是否为欺诈)。分类采用有标签和预定特征的一组数据,并学习如何基于这些信息标记新记录。这类问题的特点是“如果”,标签是这些问题的答案。在下面的例子中,如果它像鸭子一样走路,游泳和嘎嘎叫,那么标签就是“鸭子”。

我们来看一个航班延误的例子:
我们想要预测什么?
是否会延误航班。
延迟是标签:真或假。
使用什么“如果”或属性对问题进行预测?
始发机场是哪里?
目的地机场是哪里?
预计出发时间是几点?
预计抵达时间是几点?
是一周中的哪一天?
什么是航空公司?
决策树
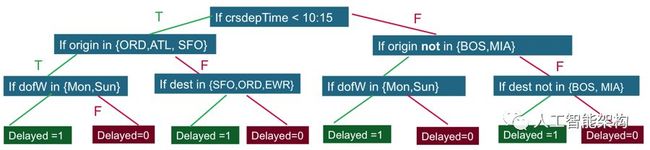
决策树创建一个模型,通过评估遵循if-then-else模式的一组规则来预测标签(或类)。if-then-else特征问题是节点,而答案true或false是树节点到子节点的分支。决策树模型评估做出正确决策的概率所需的真/假问题的最小数量。以下是航班延误的简化决策树示例:
Q1:如果预计起飞时间<上午10:15
T:Q2:如果原始机场在{ORD,ATL,SFO}
T:Q3:如果星期几是{星期一,星期日}
T:延迟= 1
F:延迟= 0
F:Q3:如果目的地机场在{SFO,ORD,EWR}
T:延迟= 1
F:延迟= 0
F:Q2:如果原始机场不在{BOS,MIA}
T:Q3:如果星期几在{星期一,星期日}
T:延迟= 1
F:延迟= 0
F:Q3F:如果原始机场不在{BOS,MIA}
T:延迟= 1
F:延迟= 0
示例数据集
我们使用的数据是2017年1月、2月、3月、4月和5月的航班信息。对于每个航班,有如下信息:
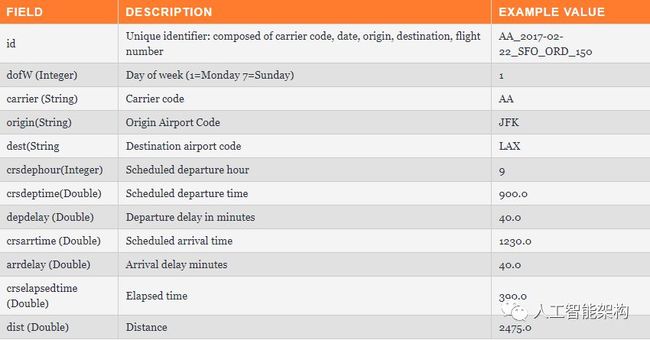
我们已经对机场和运营商的数量做了限制,并将数据转换为两个JSON文件:一个用于训练,另一个用于测试。(在GitHub上可以看到这部分代码),JSON文件具有以下格式:

可以使用MapR 5.2.1或MapR 6.0(包括Spark 2.1)运行此示例的代码,您可以使用Zeppelin查看器代码。
将数据文件加载到DataFrame中

我们使用Scala案例类和Structype定义架构。对应于JSON数据文件中的一行。

下面,我们指定要加载到数据集中的数据源、模式和类。我们加载1月和2月的数据作为训练数据集。(注意:在将数据加载到DataFrame时指定架构将提供比架构推断更好的性能)

DataFrame显示了前20行:

下面,我们加载3月和4月的数据,作为测试数据集:

摘要统计
Spark DataFrames包含一些用于统计处理的内置函数。该 describe() 函数对所有数字列执行摘要统计计算,并将它们作为DataFrame返回。
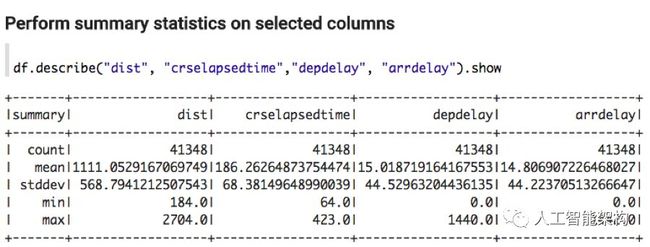
数据探索
我们使用Spark SQL探索数据集。以下是使用Spark SQL的一些示例查询:

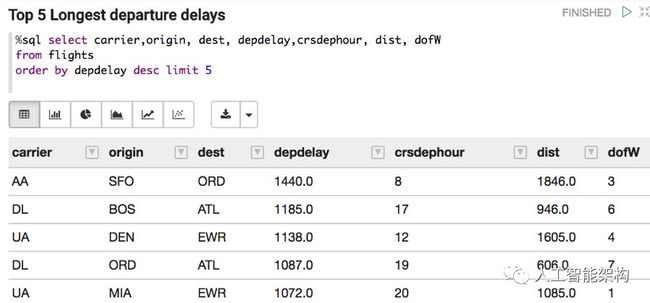
下面显示了最长的延误信息:
下面,显示了运营商的平均延误:
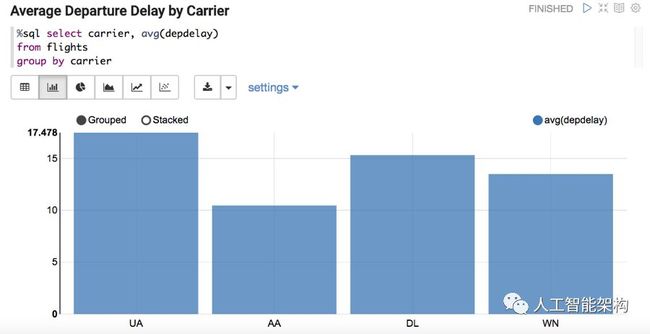
我们想预测延迟时间> 40分钟的航班延误,让我们来探索这些数据。下面,我们看到2017年1月和2月的联合航空公司和达美航空公司的航班延误次数最多(训练集)。
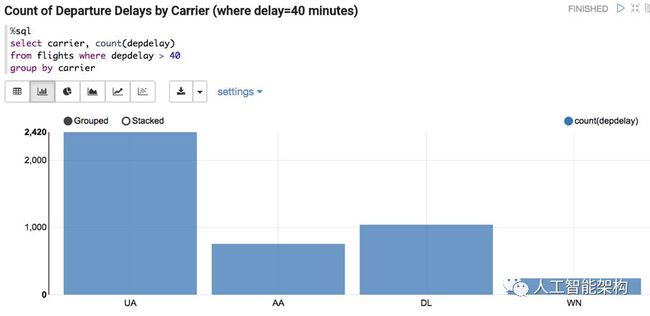
在下面的查询中,我们看到周一和周日的航班延误次数最多的信息。

以下信息显示了查询13:00-19:00之间最高的航班延误时间。
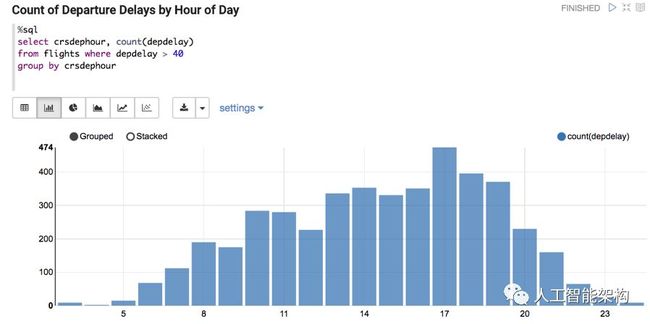
以下是芝加哥和亚特兰大机场起飞的航班延误次数最多的信息。
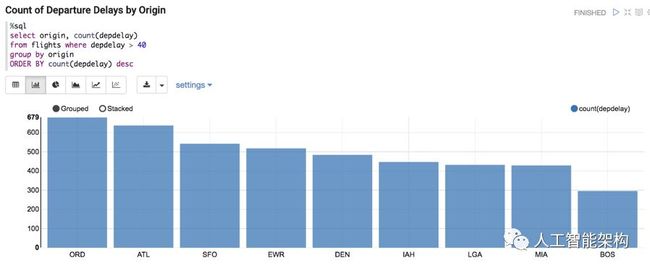
以下是旧金山和纽瓦克目的机场航班延误次数最多的信息。
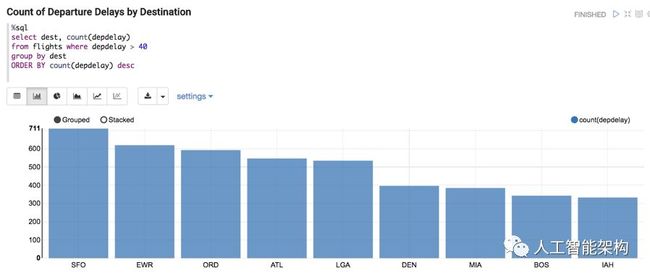
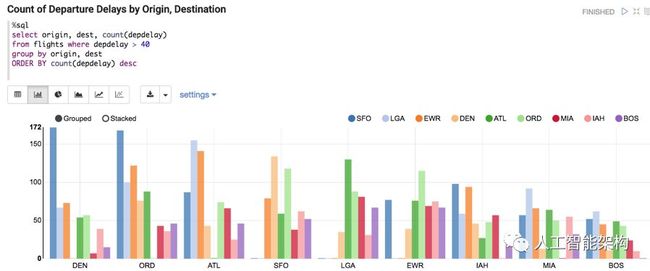
在下面的查询中,我们看到了起点和目的地的出发延误统计。ORD --> SFO和DEN --> SFO的航线延误时间最长,可能是因为1月和2月的天气。为此数据集添加天气会产生更好的结果,但这仍然是读者的练习。
在下面的代码中,Spark Bucketizer用于将数据集拆分为延迟和未延迟的航班,延迟时间为0/1。然后,统计显示结果。通过延迟字段对数据进行分组并计算每个组中的实例数量表明,未延迟样本大约是延迟样本的八倍。

在下面的查询中可以看到起点延迟(0=深蓝色)和延迟(1=浅蓝色)飞行的统计。

分层采样
为了确保我们的模型对延迟样本敏感,我们可以使用分层采样将两种样本类型放在同一个基础上。sampleBy() 当提供要返回的每个样本类型的分数时,DataFrames 函数执行此操作。在这里,保留所有延迟的实例,但是将未延迟的实例下采样到29%,然后显示结果。

功能阵列
要构建分类器模型,提取最有助于分类的功能。在这种情况下,根据以下功能构建一个树来预测延迟或不延迟的标签:
标签 - ->延迟= 0
如果延迟> 40分钟,则延迟= 1
功能 --> {星期几,预定起飞时间,预定抵达时间,承运人,预定经过时间,始发地,目的地,距离}
| DELAYED | DOFW | CRSDEPTIME | CRSARRTIME | CARRIER | ELAPTIME | ORIGIN | DEST | DIST |
|---|---|---|---|---|---|---|---|---|
| 1.0/0.0 | 1 | 1015 | 1230 | AA | 385.0 | JKF | LAX | 2475.0 |
为了使机器学习算法使用这些特征,必须将它们转换并放入特征向量中,这些特征向量是表示每个特征的值的数字向量。
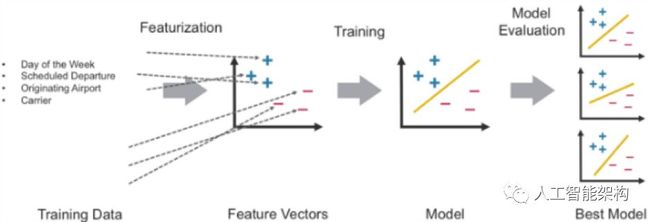
使用Spark ML包
ML封装的是机器学习程序的新库。Spark ML提供了一组构建在DataFrame之上的统一的高级API。
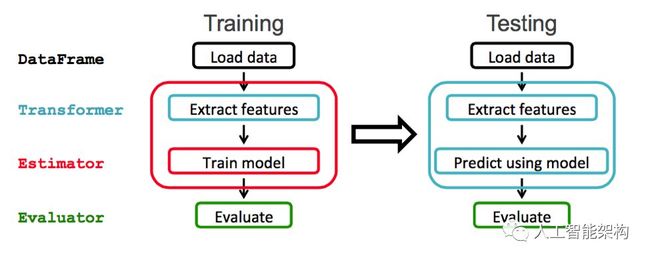
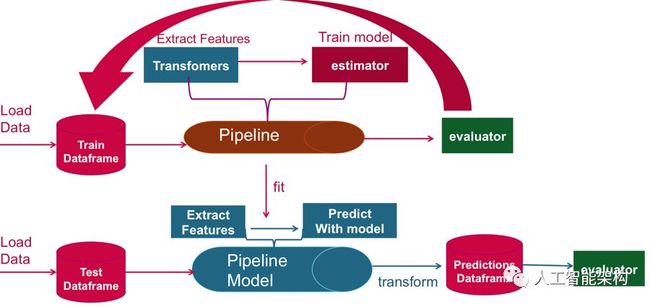
我们将使用ML Pipeline通过转换器传递数据以提取特征和估算器生成模型。
Transformer:是一种将一个DataFrame转换为另一个DataFrame的算法。使用转换器获取具有特征向量列的DataFrame。
Estimator:是一种算法,可以适应DataFrame以生成Transformer。使用估算器训练可以转换数据以获得预测的模型。
管道:管道将多个转换器和估算器链接在一起以指定ML工作流程。
特征提取与流水线
ML包需要将标签和特征向量作为列添加到输入DataFrame。我们设置一个管道来通过转换器传递数据,以便提取特征和标签。使用StringIndexer将字符串列编码为数字索引列。使用OneHotEncoder将数字索引列映射到二进制向量列,最多只有一个单值。对分类特征进行编码允许决策树适当地处理分类特征,从而提高性能。下面显示了运营商的StringIndexing和OneHotEncoding的示例:


下面,Bucketizer用于添加延迟0/1的标签。VectorAssembler将给定的列列表组合到单个特征向量列中。

在管道中运行这些转换器的结果是向数据集添加标签和要素列,如下所示。

管道中的最后一个元素是估算器(决策树分类器),对标签和特征向量进行训练。

下面,我们在管道中链接索引和树。

训练模型
我们想确定决策树的哪些参数值产生最佳模型。模型选择的常用技术是k-fold cross-validation,其中,数据被随机分成k个分区。每个分区一次用作测试数据集,其余分区用于训练。然后,使用训练集生成模型,并使用测试集进行评估,从而产生k模型性能测量。导致最高性能度量的模型参数产生最佳模型。
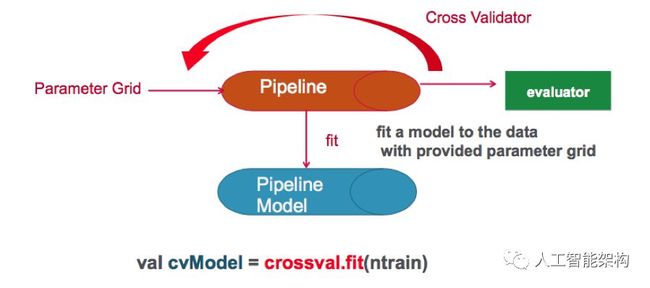
Spark ML支持使用转换/估计管道进行k-fold cross-validation,尝试不同的参数组合,使用网格搜索的过程,可以在其中设置要测试的参数,以及用于构建模型选择的交叉验证评估程序流程。
下面,使用ParamGridBuilder来构造参数网格。定义一个Evaluator,通过比较测试标签列和测试预测列来评估模型。使用CrossValidator进行模型选择。

CrossValidator使用Estimator Pipeline,Parameter Grid和Classification Evaluator来拟合训练数据集并返回模型。

CrossValidator使用ParamGridBuilder迭代决策树的maxDepth参数并评估模型,每个参数值重复三次以获得可靠的结果。
接下来,我们可以获得最佳决策树模型,以打印出决策树和特征重要性。(注意:OneHotEncoders增加了功能的数量。为了更好地理解这个打印输出,我构建了一个没有编码器的树,其精度略低)

我们发现使用交叉验证过程生成的最佳树模型是深度为6的模型。toDebugString()函数提供的决策节点的打印和最终也的最终预测结果。以下是决策树的部分打印输出:
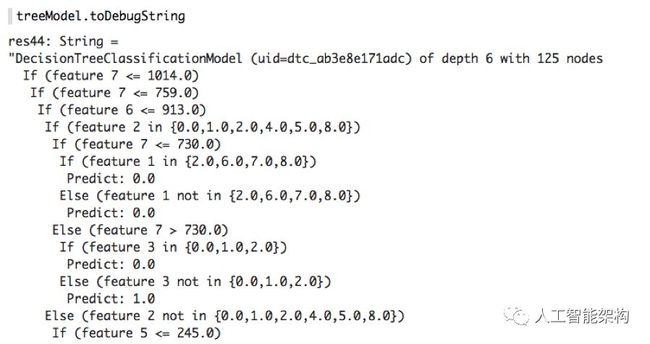
功能编号对应于以下内容:
(0 = carrierIndexed,1 = destIndexed,2 = originIndexed,3 = dofW,4 = crsdephour,5 = crselapsedtime,6 = crsaatime,7 = crsdeptime,8 = dist) ,6 = crsarrtime,7 = crsdeptime,8 = dist)
下面,我们可以看到顺序中的功能重要性是:
预定出发时间(功能7)
目的地(特色1)
起源(特征2)
预定抵达时间(功能6)
星期几(功能3)
![]()

决策树通常用于特征选择,因为它们提供了一种自动机制,用于确定最重要的特征(最接近树根的特征)。
预测和模型评估
可以使用尚未用于任何训练或交叉验证活动的测试数据集来确定模型的实际性能。
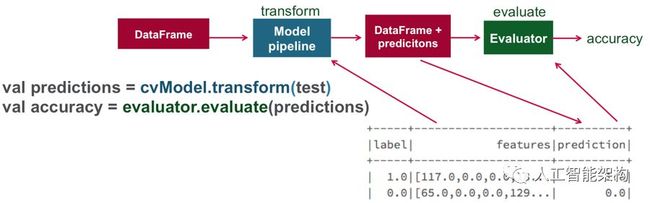
使用模型管道转换测试DataFrame,模型管道将根据管道转换特征,估计,然后在新DataFrame的列中返回标签预测。

评估器将向我们提供预测的分数。精度由ROC曲线下的面积测量。该区域测量了测试从误报中正确分类的能力。随机预测器的准确度为.5。值越接近1,其预测越好。在这种情况下,评估返回81%的精度。

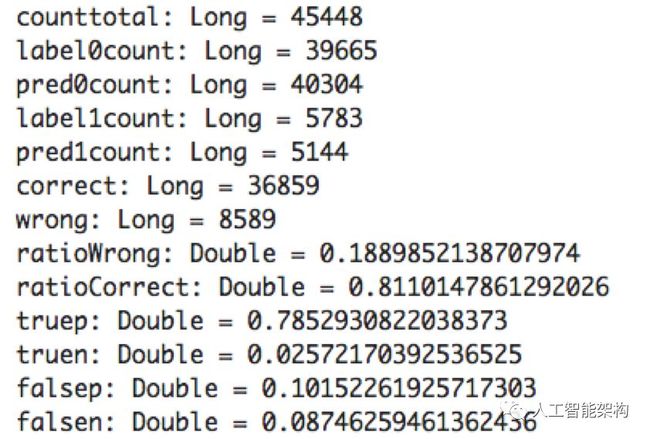
下面,我们计算更多指标。假/真预测的数量也很有用:
精准是模型正确预测延误航班的频率。
误报是模型错误预测延误飞行的频率。
正数表示模型正确预测的延误航班的频率。
负数表示模型错误预测不会延误航班的频率。

保存模型
我们现在可以保存我们安装的Pipeline,以便以后使用流媒体事件。这样可以节省特征提取阶段和模型调整所选择的决策树模型。

保存管道模型的结果是元数据的JSON文件和模型数据的Parquet。使用load命令重新加载模型; 原始和重新加载的模型是相同的:
结语
通过本文的讲解,读者可以选择自己感兴趣的的信息进行训练和预测,灵活的应用才能真正的掌握这个技术呦。

长按二维码 ▲
订阅「架构师小秘圈」公众号
如有启发,帮我点个在看,谢谢↓