使用JAVA代码实现编程式提交Spark任务
0x0 背景介绍
项目中使用SparkSession来执行任务,出现一个问题:
SparkSession开启后会一直占用集群的资源(CPU和内存),而且,SparkSession关闭后,无法再次开启(报异常)。
为了解决以上问题,只有采用Java代码模拟Spark Submit来提交任务到集群,从而实现动态调用spark。
0x1 方法
查看多方资料,发现三个方法,分别是:
1. 直接调用SparkSubmit的main方法
2. SparkLauncher类的launch方法或者startApplication方法
3. 使用RestSubmissionClient的run方法
下面分别介绍这两种方法。
0x2 SparkSubmit提交任务
我采用的是spark的standalone模式执行任务,代码如下:
String[] args = {
"--class", "com.fly.spark.WordCount",
"--master", "spark://192.168.0.181:6066",
"--deploy-mode", "cluster",
"--executor-memory", "1g",
"--total-executor-cores", "4",
"hdfs:///wordcount.jar",
"hdfs:///wordcount.txt",
"hdfs:///wordcount"
};
SparkSubmit.main(args);可见,基本上就是把spark-submit脚本放到了java中执行!
但是要注意:
"--master", "spark://192.168.0.181:6066"这里的端口号是6066,如果你写7077会报如下异常:
Running Spark using the REST application submission protocol.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
18/02/24 14:37:14 INFO RestSubmissionClient: Submitting a request to launch an application in spark://192.168.0.181:7077.
18/02/24 14:37:25 WARN RestSubmissionClient: Unable to connect to server spark://192.168.0.181:7077.
Warning: Master endpoint spark://192.168.0.181:7077 was not a REST server. Falling back to legacy submission gateway instead.
18/02/24 14:37:31 ERROR ClientEndpoint: Exception from cluster was: java.lang.IllegalArgumentException: Invalid environment variable name: "=::"
java.lang.IllegalArgumentException: Invalid environment variable name: "=::"
at java.lang.ProcessEnvironment.validateVariable(ProcessEnvironment.java:114)
at java.lang.ProcessEnvironment.access$200(ProcessEnvironment.java:61)
at java.lang.ProcessEnvironment$Variable.valueOf(ProcessEnvironment.java:170)
at java.lang.ProcessEnvironment$StringEnvironment.put(ProcessEnvironment.java:242)
at java.lang.ProcessEnvironment$StringEnvironment.put(ProcessEnvironment.java:221)
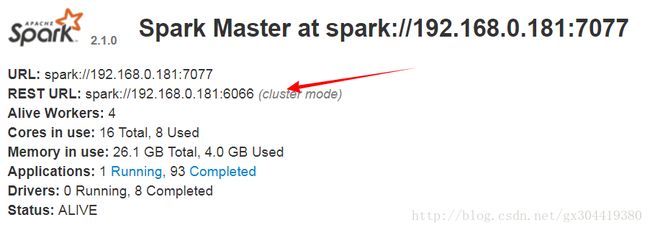
从异常中可以看出:using the REST application submission protocol, 也就是说他是用REST提交协议进行提交的!另外,在spark的web界面上也可以查看到,Rest URL端口是6066:
0x3 SparkLauncher提交任务
暂时未测试成功,先贴出代码:
SparkLauncher launcher = new SparkLauncher();
SparkAppHandle handler = launcher.setAppName("Test Submit Spark Job From Java")
.setMaster("spark://192.168.0.181:7077")
.setAppResource("hdfs://192.168.0.181:8020/opt/guoxiang/wordcount.jar")
.setMainClass("com.fly.spark.WordCount")
.setDeployMode("cluster")
.addAppArgs(new String[]{"hdfs://192.168.0.181:8020/opt/guoxiang/wordcount.txt", "hdfs://192.168.0.181:8020/opt/guoxiang/wordcount"})
.setConf("spark.executor.memory", "1g")
.setConf("spark.cores.max", "4")
.setVerbose(true)
.startApplication();
System.out.println(handler.getAppId());
System.out.println(handler.getState());
System.out.println("launcher over");哪位大侠给看看,每次执行啥都没有显示就完了
未报任何异常!
补充:
SparkLauncher需要设置spark home属性
否则无法运行
.setSparkHome("/path/to/your/spark")0x4 RestSubmissionClient的run方法提交
@Test
public void submit() {
String appResource = "hdfs://192.168.0.181:8020/opt/guoxiang/wordcount.jar";
String mainClass = "com.fly.spark.WordCount";
String[] args = {
"hdfs://192.168.0.181:8020/opt/guoxiang/wordcount.txt",
"hdfs://192.168.0.181:8020/opt/guoxiang/wordcount"
};
SparkConf sparkConf = new SparkConf();
// 下面的是参考任务实时提交的Debug信息编写的
sparkConf.setMaster("spark://192.168.0.181:6066")
.setAppName("carabon" + " " + System.currentTimeMillis())
.set("spark.executor.cores", "4")
.set("spark.submit.deployMode", "cluster")
.set("spark.jars", appResource)
.set("spark.executor.memory", "1g")
.set("spark.cores.max", "4")
.set("spark.driver.supervise", "false");
Map env = System.getenv();
CreateSubmissionResponse response = null;
try {
response = (CreateSubmissionResponse)
RestSubmissionClient.run(appResource, mainClass, args, sparkConf, new HashMap<>());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(response.toJson());
} 该方法的好处在于,可以获取response.toJson()
从而查看JOB是否执行成功!