遗传算法
使用遗传算法求解多峰函数的最大值,是我的一项课程作业,做完之后,顺便把文档整理出来做个记录。全部内容如下:
1、问题描述
编程实现遗传算法,并求解多峰函数的最大值。多峰函数的表达式如下所示:
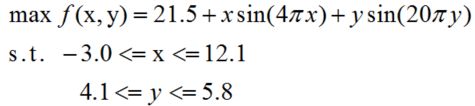
用MATLAB做出函数的图像如下:
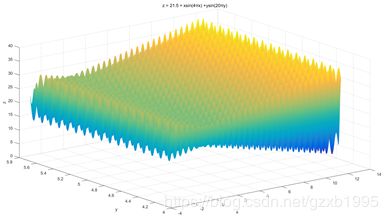
2、算法描述及实现
2.1、遗传算法概述
遗传算法(GA,Genetic Algorithm),也称为进化算法。遗传算法是受达尔文的进化论的启发,借鉴生物进化过程而提出的一种启发式搜索算法。其主要特点是直接对结构对象进行操作,因此不同于其他求解最优解的算法,遗传算法不存在求导和对函数连续性的限定,采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
以上是对遗传算法相对抽象的总结,为了更具体形象的解释遗传算法的一般原理,我们首先介绍一些生物学上的概念:
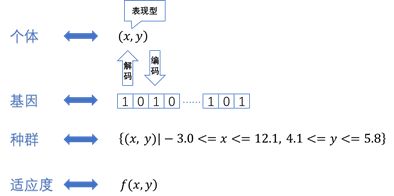
①种群:不同生物个体形成的群体,生物的进化以群体的形式进行,这样的一个群体称为种群;
②个体:组成种群的单个生物;
③基因:带有遗传信息的DNA片段,可以通俗的将基因理解为一段信息,这段信息决定的生物个体的性状;
④表现型:根据基因形成的个体的外部表现;
⑤适应度:生物个体对于生存环境的适应程度,越适应那么其得以存活和繁衍的概率就越大;
⑥遗传:通过繁殖过程,子代将从父母双方各获取一部分基因,形成新的自己的基因,这个过程中,会发生基因的复制、交叉,也会以较低的概率发生基因突变;
⑦自然选择:物竞天择,适者生存的自然淘汰机制。具体为对环境适应度高的个体参与繁殖的机会比较多,后代就会越来越多。适应度低的个体参与繁殖的机会比较少,后代就会越来越少;
⑧进化:种群通过代际繁衍不断适应生存环境的过程,在这个过程中,以对外界环境的适应度为评判标准,生物的性状不断得到改良。
了解了这些术语的含义,我们就可以进一步说说生物进化的过程了。由于自然选择是客观存在的,即生物只能改变自己去适应环境,那么在自然选择的过程中,适应度低的个体会被淘汰,适应度高的个体被保留,高适应度的父体与母体又有更高的概率繁衍出适应度高的子代,因此在一代又一代的繁衍之后,高适应度的个体在种群中所占的比例越来越大,种群就这样完成了进化。
现在我们要参考生物进化的过程来设计算法解决求最优解的问题。对此,遗传算法的思路是,将要解决的问题模拟成一个生物进化的过程,通过进化来寻找最优解。以我们题目中寻找多峰函数的最大值这个问题为例:
将(x, y)这一可能的解作为一个个体;将多峰函数的函数值f(x, y)作为个体的适应度;对(x, y)进行编码作为个体的基因;以适应度为标准不断筛选生物个体;通过遗传算子(如复制、交叉、变异等)不断产生下一代。如此不断循环迭代,完成进化。最终,根据设定的迭代次数,可得到最后一代种群,该种群中的个体适应度都较高,而多峰函数的最大值就有比较大的概率存在于这一群解中,以种群中适应度最高的个体作为问题的解,则可以说该解有比较高的概率就是我们希望求得的最优解。
文字述说终究还是不如图表好理解,因此还是看图吧(下图将本题与自然遗传联系了起来):
通过以上描述,我们不难看出,遗传算法不能保证一定能求得最优解,而只能以一定的概率求最优解。但是使用遗传算法时,我们可以不用关心具体如何去找最优解,要做的只是简单的否定一些表现不好的个体。这一优点也是遗传算法能够取得广泛应用的原因之一。
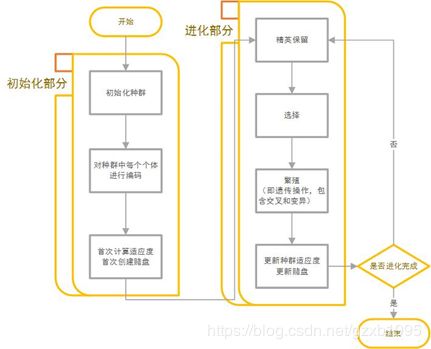
2.2、算法的流程
通过上文的阐述,对于如何模拟自然进化来求题中多峰函数的最优解已经比较明晰了。这里我将列出遗传算法的主要步骤,并一一解析:
第一步:随机产生一个种群,作为问题的初代解(通常,初代解可能与最优解相差较大,这是可以容忍的,只要保证初代解是随机产生的,以确保个体基因的多样性即可);
第二步:寻找一种合适的编码方案对种群中的个体进行编码,可以选择如浮点数编码或二进制编码等常用编码方案(需要指出的是,不同的编码方案直接影响后续遗传算子的实现细节);
第三步:以多峰函数的函数值 作为个体的适应度,计算种群中每个个体的适应度(算出的适应度将为后续的个体选择提供依据);
第四步:根据适应度的高低选择参与繁衍的父体与母体,选择的原则是适应度越高的个体越可能被选中(以此不断淘汰适应度低的个体);
第五步:对被选出的父体与母体执行遗传操作,即复制父体与母体的基因,并采用交叉、变异等算子产生出子代(在较大程度保留优秀基因的基础上,变异增加了基因的多样性,从而提高找到最优解的概率);
第六步:根据一定的准则判断是继续执行算法,还是找出所有子代中适应度最高个体作为解返回并结束程序(判断的准则可以是设定的解的阈值、指定的迭代次数等)。
2.3、算法的编码实现
2.3.1、编码
本文采用的是二进制编码方式,这种编码方式编解码过程简单易行,相应的交叉算子、变异算子等操作用位运算即可实现。当然,它也有一定的缺点,比如连续性不够强。为保证求解的精度,本文使用14个bit为 编码,使用11个bit为 编码,两者组合成25个bit的最终结果。不难算出,该方式的编码精度可达千分位。具体的编码操作可总结为,将 或 的取值区间映射到0~2n-1这一整数范围,其中n表示编码位数, 或 在其取值区间的某点,相应的映射到整数区间中的某点,改点即为 或 的基因编码。程序如下:
/*
基因编码
gene1 输入型参数,待编码的基因段1
gene2 输入型参数,待编码的基因段2
gene_code 输出型参数,基因编码
返回值:当输入的基因不符合要求时返回false,否则返回true
*/
static bool gene_encode(const double gene1, const double gene2, unsigned int *gene_code)
{
/* 判断基因是否合法 */
if (!is_gene_legal(gene1, gene2))
return false;
/* 若基因合法则对其进行编码 */
unsigned int gene1_code = (gene1 - GENE1_RANGE_LEFT) * (GENE1_CODE_MAX - 1) / (GENE1_RANGE_RIGHT - GENE1_RANGE_LEFT);
unsigned int gene2_code = (gene2 - GENE2_RANGE_LEFT) * (GENE2_CODE_MAX - 1) / (GENE2_RANGE_RIGHT - GENE2_RANGE_LEFT);
/* 组合基因片段 */
*gene_code = (gene1_code << 11) | gene2_code;
return true;
}
2.3.2、解码
解码是编码的逆过程,无需赘述,程序如下:
/*
基因解码
gene_code 输入型参数,基因编码
gene1 输出型参数,解码后的基因段1
gene2 输出型参数,解码后的基因段2
返回值:当输入的基因编码不符合要求时返回false,否则返回true
*/
static bool gene_decode(const unsigned int gene_code, double *gene1, double *gene2)
{
/* 判断基因编码是否合法 */
if (!is_gene_code_legal(gene_code))
return false;
/* 若基因编码合法则对其进行解码 */
unsigned int gene1_code = GET_GENE1_CODE(gene_code);
unsigned int gene2_code = GET_GENE2_CODE(gene_code);
*gene1 = (double)gene1_code * (GENE1_RANGE_RIGHT - GENE1_RANGE_LEFT) / (GENE1_CODE_MAX - 1) + GENE1_RANGE_LEFT;
*gene2 = (double)gene2_code * (GENE2_RANGE_RIGHT - GENE2_RANGE_LEFT) / (GENE2_CODE_MAX - 1) + GENE2_RANGE_LEFT;
return true;
}
2.3.3、计算适应度
适应度函数也称评价函数,通常用于区分群体中个体好坏的标准。适应度高的,也就是优秀的个体有更大的几率参与繁衍,遗传自己的基因。一般的,适应度函数根据目标函数来确定,有时候直接将目标函数值作为适应度。这里,考虑到待求解的多峰函数,尖峰分布密集而且峰的直径很窄,这不利于遗传算法的收敛,因此本文不直接将多峰函数值作为适应度,而是利用对数函数将多峰函数进行平缓,并将平缓后的函数值作为目标函数。具体做法是,将多峰函数进行两次求对数,因此,多峰函数与适应度的关系可如下表示:

用MATLAB做出适应度函数图像如下:
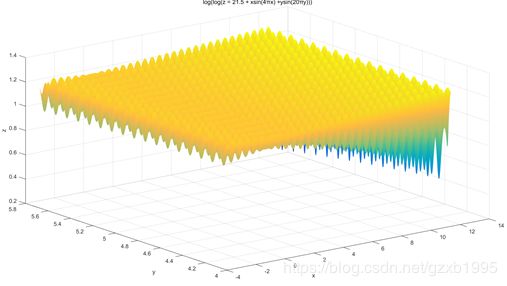
对比前文中的图不难看出,图像得到了有效的平缓,同时不同峰之间也保持着一定的高低之别。值得一提的是,这里更主要的是给出优化遗传算法的一个思路,即可以在适应度函数上做文章。本题的适应度函数只是对多峰函数本身做了一个简单的变换,读者不妨思考一下,就本题而言有没有什么非常好的适应度函数。
据上文所述,适应度求值函数如下:
/*
多峰函数:z = 21.5 + x *sin(4 * 3.1415926 * x) + y * sin(20 * 3.1415926 * y)
适 应 度:log(log(z))
约 束:-3.0 <= x <= 12.1; 4.1 <= y <= 5.8
精 度:精确到千分位
*/
double get_fitness(const double x, const double y)
{
return log(log(21.5 + x * sin(4 * PI * x) + y * sin(20 * PI * y)));
}
2.3.4、选择算子
本文的选择算法采用了非常常用的“轮盘赌算法”,赌盘算法的原理非常简单明了。创建赌盘时,我们将种群中所有个体的适应度求和,不妨将得到的结果称为总和适应度。然后,将每个个体的适应度除以总和适应度,然后将得到的商逐个累加,每加一次就得到赌盘的一个边界,累加完成后总和为1。如下的饼状图可以更形象的表明赌盘的原理:
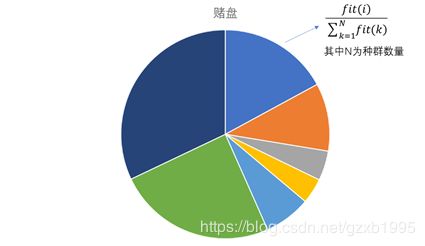
由上文所述,赌盘创建函数可如下编写:
/*
创建赌盘
ga 遗传算法器指针
*/
static void create_roulette(GA *ga)
{
/* 计算赌盘中的概率 */
ga->roulette[0] = ga->fitness[0] / ga->sum_fitness;
for (int num = 1; num < ga->population_num - 1; num++)
{
ga->roulette[num] = ga->roulette[num - 1] + ga->fitness[num] / ga->sum_fitness;
}
ga->roulette[ga->population_num - 1] = 1.0;
}
再回到选择算子,选择算子需要赌盘作为基础,其运行时,会产生一个0到1的随机数,然后在赌盘中找到该数所在的区间,这个区间对应的个体即为被选中的个体。因此,适应度越高的个体被选中的几率越大,这是合理的。当然,也存在较小的概率选出适应度较低的个体,为了避免这种情况,本文引入了竞争机制,即一次选择的过程选出2个个体,再取其中适应度较高的那个个体,具体的程序如下:
/*
基因选择函数
ga 遗传算法器指针
返回值:返回使用轮盘赌的方式选出的个体(编号)
说 明:选择策略为轮盘赌+随机竞争
*/
static unsigned int select(GA *ga)
{
unsigned int index1 = 0, index2 = 0;
/* 产生一个[0.0, 1.0]之间的浮点数 */
double selector1 = rand() * 1.0 / RAND_MAX;
double selector2 = rand() * 1.0 / RAND_MAX;
/* 找出被选中的个体的索引 */
for (; selector1 > ga->roulette[index1]; index1++);
for (; selector2 > ga->roulette[index2]; index2++);
return (ga->fitness[index1] > ga->fitness[index2] ? index1 : index2);
}
2.3.5、交叉算子
遗传算法的交叉操作实质上是按某种方式交换父体和母体的部分基因,常见的交叉算子有单点交叉、两点交叉、多点交叉、均匀交叉及算术交叉等。本文选用两点交叉法,实现过程既不复杂,也有较好的随机性,该方法可由下图示意:
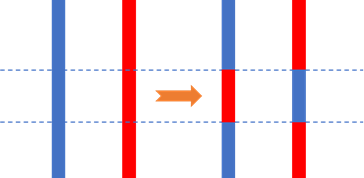
图中虚线指出的两个交叉点是随机产生的。具体程序如下:
/*
交叉函数
ga 遗传算法器指针
one 输出型参数,待交叉基因
another 输出型参数,待交叉基因
说明:
1.对传入的基因编码执行两点交叉操作
*/
static void cross(GA *ga, unsigned int *one, unsigned int *another)
{
/* 1.随机产生两个交叉点的位置 */
unsigned char pos1 = rand() % GENE_CODE_LENGTH + 1;
unsigned char pos2 = rand() % GENE_CODE_LENGTH + 1;
unsigned char min_pos = min(pos1, pos2);
unsigned char max_pos = max(pos1, pos2);
/* 2.截出需要交换的基因段 */
unsigned int one_gene_seg = get_bits(*one, min_pos, max_pos) << (min_pos - 1);
unsigned int another_gene_seg = get_bits(*another, min_pos, max_pos) << (min_pos - 1);
unsigned int mask = ~(get_bits(~(0U), min_pos, max_pos) << (min_pos - 1));
/* 3.执行交叉操作 */
*one = (*one & mask) | another_gene_seg;
*another = (*another & mask) | one_gene_seg;
}
2.3.6、变异算子
在自然界中,基因变异可以增加个体的多样性,这对于遗传算法来说是增加了个体的随机性,可以增加找到最优解的概率。本文采用的变异算子所做的操作是随机选择基因的某一位进行反转,程序如下:
/*
变异函数
gene_code 输入型参数
说明:
1.对传入的基因编码执行变异操作
2.随机选择基因编码中的一位做反转操作
*/
static void mutate(unsigned int *gene_code)
{
unsigned int mutate_bit = 1 << (rand() % GENE_CODE_LENGTH);
*gene_code ^= mutate_bit;
}
2.3.7、繁殖函数及进化函数
遗传算法的主要算子都在上文中分析过了,下面要做的就是根据遗传算法的流程将这些算子整合起来以实现算法功能。在本文中,这其中涉及到两个关键的函数,即繁殖函数和进化函数。繁殖函数包括基因的复制、交叉及变异,同时本文还采用了子代竞争策略,即父代产生的两个子代个体仅保留适应度最高的,程序如下:
/*
繁殖函数
ga 遗传算法器指针
father 从种群中选出的父体
mother 从种群中选出的母体
返回值: 适应度最高的子代的基因编码
说明:
1.一对父体与母体将繁殖出一对子代
2.选择出适应性更好的子代返回
*/
static unsigned int inherit(GA *ga, unsigned int father, unsigned int mother)
{
unsigned int son1 = ga->gene_code[father];
unsigned int son2 = ga->gene_code[mother];
/* 1.交叉 */
cross(ga, &son1, &son2);
/* 2.变异 */
mutate(&son1);
mutate(&son2);
/* 3.子代竞争 */
double son1_gene1, son1_gene2, son2_gene1, son2_gene2;
gene_decode(son1, &son1_gene1, &son1_gene2);
gene_decode(son2, &son2_gene1, &son2_gene2);
return (ga->get_fitness(son1_gene1, son1_gene2) > ga->get_fitness(son2_gene1, son2_gene2)) ? son1 : son2;
}
进化函数则实现了遗传算法的一次完整的迭代过程,根据上文给出的遗传算法流程图,不难进行如下编码:
/*
进化函数
ga 遗传算法器指针
*/
static void evolve(GA *ga)
{
/* 1.申请暂存子代基因编码的内存 */
unsigned int *descendants = (unsigned int *)calloc(ga->population_num, sizeof(unsigned int));
/* 2.精英保留(将上一代中适应度最高的个体的基因编码保留) */
descendants[0] = ga->gene_code[ga->best_individual];
/* 3.选择合适的父体与母体 */
unsigned int father = select(ga);
unsigned int mother = select(ga);
/* 4.繁殖(包含交叉与变异) */
for (int num = 1; num < ga->population_num; num++)
descendants[num] = inherit(ga, father, mother);
/* 5.将子代记录到ga中并进行基因解码(使新一代的基因编码与基因对应) */
for (int num = 0; num < ga->population_num; num++)
{
ga->gene_code[num] = descendants[num];
gene_decode(ga->gene_code[num], &ga->gene[num].gene1, &ga->gene[num].gene2);
}
/* 5.更新种群适应度 */
fit(ga);
/* 6.更新赌盘 */
create_roulette(ga);
/* 7.释放之前申请的空间 */
free(descendants);
}
3、运行结果及分析
至此,本文已经给出了一个遗传算法的C语言实现的所有关键程序。下面就调用编写的遗传算法进行测试。本文将创建含有100个个体的种群,并进行100代迭代以求解多峰函数的最大值,一次完整的调用本文实现的遗传算法的程序如下所示:
/* 创建遗传算法器 */
GA *ga = create_ga(get_fitness, 100);
/* 初始化遗传算法器 */
ga->init(ga);
/*迭代100代*/
for (int i = 0; i < 100; i++)
ga->evolve(ga);
/*销毁遗传算法器*/
delete_ga(ga);
经多次调用测试,算法执行的结果较为稳定,所得的多峰函数最大值大多在38以上,多次运行结果中最好的解为38.849744,对应的坐标为(11.625331, 5.725256)。将迭代求得的最大值用MATLAB作图如下:
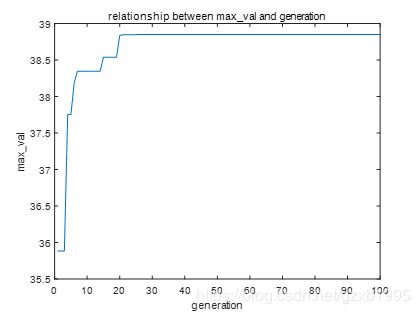
为验证是否找到了最优解,用MATLAB遍历求出该多峰函数在给定定义域内的最大值为38.8501,与本文求出的结果相差0.000356,可见本文实现的遗传算法表现还不算太差。
文中给出的程序比较散,这里给出完整程序的下载链接。