CVPR2020:开源VIBE用于人体姿势和形状估计的最新算法
作者

介绍
人体的运动对于理解人类的行为是非常重要的。虽然目前基于视频的SOTA方法在单幅图像的三维姿态和运动估计方面已经取得了一定的进展,但由于缺乏真实的三维运动数据进行训练,因此不能产生准确、自然的运动序列。为了解决这一问题,本文提出了一种利用现有的大规模运动捕获数据集(AMASS)和未配对的二维关键点标记数据进行人体姿态和形状估计的视频推理(VIBE)方法。
本文的主要创新之处在于它是一个对抗性学习框架,它利用大量的数据集来区分真实的人类行为和本文中使用时间姿势和动作回归网络生成的行为。本文定义了一种时间序列网络结构,并证明了该结构可以在没有真实3D标签的情况下生成序列级合理的运动序列。本文进行了大量的实验,分析了运动的重要性,并证明了VIBE在一个非常具有挑战性的3D姿态估计数据集上的有效性,以实现SOTA性能。

如图上图所示,现有的视频位姿和运动估计方法无法产生真实合理的预测结果。其主要原因是缺乏对数据的三维标注,对于单个图像更难以获取,对于视频更是如此。一些先前的研究工作,他们将室内三维数据集与视频结合起来,使用二维注释或关键点伪注释。然而,存在以下几个局限性:
(1)室内三维数据集在受试者数量、运动范围和图像复杂度方面受到限制;(2)具有2D姿势标注的视频数量仍然不足以训练深层神经网络
(3)伪2D标记对三维人体运动建模不可靠。
为了解决这个问题,本文使用了最新的大型3D运动捕捉数据集AMASS,它足够丰富,可以训练模型来学习人们如何移动。本文的方法是利用二维关键点估计未标记视频的三维姿态序列。与之前的一些研究工作一样,本文也将使用3D关键点。本文的方法输出的是SMPL人体模型格式的一系列姿态和运动参数。
具体来说,本文通过训练一个基于序列的生成性对抗网络来利用两个未配对的信息源。在这里,给定一个人的视频,作者训练了一个时间模型来预测每个帧的SMPL人体模型参数,而运动鉴别器试图区分真实序列和回归序列。通过这样做,回归者可以通过最小化对抗性训练的损失来激励输出一个代表合理运动的姿势。作者称这种方法为VIBE,它代表“人体姿势和运动估计的视频推理”
在训练过程中,“VIBE”以未标记的图像作为输入,利用预先训练好的卷积神经网络对单个图像的人体姿态估计任务来预测SMPL人体模型参数。然后,运动鉴别器使用从AMASS数据集中采样的预测姿势和姿势来为每个序列输出真/假标签。整个模型由对抗损失和回归损失来监督,以最小化预测和标记的关键点、姿态和运动参数之间的误差。本文采用一种改进的旋转方法,利用基于模型的拟合器来训练深度回归器。然而,自旋是一种单帧方法。为了对视频序列进行处理,作者将SMPLify扩展到视频中,使自旋方法能够融入到定时信息中。
在测试过程中,给出一段视频,利用预先训练好的HMR和时间模块预测每帧的姿态和运动参数。在多个数据集上进行了大量实验,超过了所有最新的技术;VIBE输出示例见图1(底部)。重要的是,在具有挑战性的三维位姿估计基准数据集3DPW和MPI-INF-3DHP上,基于视频的方法总是比单帧方法好得多。这清楚地说明了在三维姿态估计中使用视频的好处。
综上所述,本文的主要贡献如下:首先,扩展了Kolotouros等人基于模型的拟合在环训练过程。以便更准确地监控视频。其次,利用AMASS运动数据集对VIBE进行对抗性训练。第三,定量比较了不同时间帧下的三维人体运动估计。第四,利用大型运动捕捉数据集训练鉴别器,从而得到SOTA的结果。
方法
整个VIBE方法的结构如下图2所示。输入是单人视频。对于每一帧,先用预先训练好的模型提取特征,然后用双GRUs构成的编码器进行训练。然后利用这些特征对SMPL人体模型的参数进行回归。最后从AMASS数据集中抽取样本,输入动作鉴别器,区分真假样本,完成整个过程。

图2:VIBE架构
-
时间编码器
在对编码器进行训练时,采用了4种损耗函数,包括二维损耗、三维损耗、姿态损耗和运动损耗。

各项目具体计算方法如下:
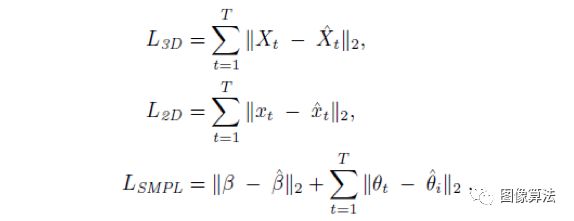
其中L_adv是动作鉴别器的损失。
-
运动鉴别器
作者使用动作鉴别器来确定生成的姿势序列是否与真实序列对应。如下图所示:

鉴别器的损耗项计算如下:
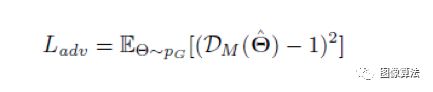
动作鉴别器的目标函数如下:

实验结果
作者首先介绍了训练和测试数据集。接下来,将本文方法的结果与以前最新的基于帧和基于视频的方法(SOTA)进行比较,如表1所示。此外,还进行了烧蚀实验来证明本文的贡献。最后,图4显示了可视化的结果。

表1:3DPW、MPI-INF-3DHP和H36M数据集的最新模型基准
该方法与SOTA方法的比较
研究表明,利用3DPW训练集有助于提高模型在野外数据中的处理能力。由于该方法保持了定时姿态和运动的一致性,使得MPJPE和PVE指标有了显著的提高。
消融实验(关于运动鉴别器)
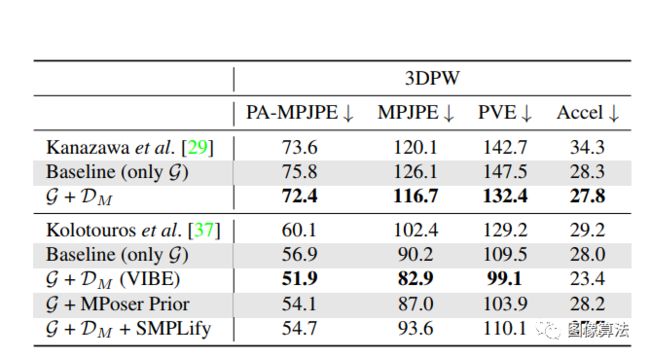
表2:运动鉴别器消融实验
可以观察到,由于缺少足够的视频训练数据,加上生成器G后,与基于帧的模型相比,本文得到的效果稍差,但视觉效果会更平滑。在时间HMR法中也观察到这种效应。此外,使用运动鉴别器有助于提高G的性能,同时还能产生更平滑的预测。
从本文方法的从下面可视化结果可以看出,该方法能够正确地恢复全局旋转。这是用以前的方法很难解决的问题。



结论
本文探讨了将静态方法扩展到视频处理中的几种方法:
(1)介绍了一种循环结构,它可以随着时间的推移而传播信息;
(2)介绍了使用AMASS数据集引入运动序列的判别训练;
(3)介绍了判别器中的自关注机制,以便它学习本文还从AMASS中学习了一种新的人类先验序列信息(MPoser),并证明该信息对训练效果也有一定的贡献,虽然不如分类器。
论文地址:
https://arxiv.org/pdf/1912.05656.pdf
开源地址:
https://github.com/mkocabas/VIBE
更多论文地址源码地址:关注“图像算法”微信公众号
