大数据采集与预处理技术
第一章 三个点
1.1数据的处理流程
数据采集 (系统日志采集,互联网数据采集,ETL) 在网上采集各种信息
数据预处理(数据清理,数据集成,数据变换,数据规约) 采集到信息杂乱,需要处理
数据存储 ( HDFS,NoSQL,云存储) 处理完数据我们要把它存储起来
数据分析与挖掘 (关联,聚类,分类,预测,回归,机器学习) 对数据分析产生价值
数据可视化 (标签云,流式地图,聚类图,信息流热力图) 将数据更好的表达出信息
1.2 大数据采集技术
1.系统日志采集
数据到来源 : 系统操作日志,Web服务器访问日志,应用程序日志

2.互联网数据采集
第二章 数据采集基础
1传统数据采集技术
采集系统分为 硬件 与 软件
硬件有分两类 1,微型计算机数据采集系统 2,集散型数据采集系统
第三章大数据采集基础
1
2
3大数据采集的挑战与困难 分布性 不稳定性 无结构与冗余性 错误性 结构复杂
4,系统日志文件采集 日志: 系统自动生成的记录文件.
5,ETL工具采集 数据源不同 格式不同 缺少整合 (E抽取 T转换 L 加载)
E(extract) 全量抽取 增量抽取(日志对比,时间戳,触发器,全表对比)
T(transform) 过滤 清洗 替换 验证 加解密
L(load) 自有数据的加载 非电子数据到数字化 对系统结构到清晰理解 ETL——ELT API接口提供数据
6,互联网数据采集 ——人 机 物
特性 多源异构 互交性 时效性 社会性 突发性 高噪声
采集——网络爬虫 通用网络爬虫 聚焦网络爬虫 增量式网络爬虫 分布式网络爬虫
第四次课 大数据采集架构 flume
(几种采集项目 )
面对到问题 :数据源多种多样 数据量大 变化快 如何保证数据采集的可靠性到性能 如何避免重复到数据 如何保证数据质量
1,Flume数据采集
数据源 (Web Server) 数据搜集Agent (Source,Channel,Sink) 数据存储目的地(HDFS)
第四讲
数据源 web Server 数据收集Agent Source Channel sink
channel 通道
memory channel 写入内存 非持久化存储 断电 碟机 丢失信息 file channel 写入文件持久化储存
第五讲 kafka
1,Scribe 数据采集 scribe 是facebook开源的日志收集系统 可以从各种日志源上收集日志存储到一个中央存储系统 特点 容错性好当后端的存储系统crash时scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe 将日志重新加载到存储系统中
2,kafka数据采集 是发布订阅消息系统构建实时数据管道和数据流应用程序
结构 生产者producer(数据采集的源头) 消费者consumer kafka集群 broker(topic partition broker 节点) zookeeper负责协调节点
(1)producer 负责向kafka的主题topic 提供数据(push) topic是kafka的核心抽象 数据源可以用kafka按topic发布信息给定阅者
topic 一个主题 与多个分区维护一个分区日志 要求顺序写入均匀分布批量传输
(2)consumer 按组消费
(3)发布—订阅 Push and pull 机制 有主动获取与被动获取
(4)zookeeper 分布式服务框架 统一命名服务 状态同步管理

第六次课 ELK
ELK是一种数据采集架构 E (ElasticSearch) L(Logstash) K(Kibana)
Logstash 日志采集 (重点) ES 日志存储和索引 (放在中间步骤) Kibana 分析与展示 数据可视化
logstash的工作过程 : input 数据收集 ——filters 修改数据——output 输出数据
input
(一)filters 的操作
1,grok 对数据进行切分整理

2,rename 重命名

3,update 更新文段

4,replace 替代
5,drop 删除满足条件的日志
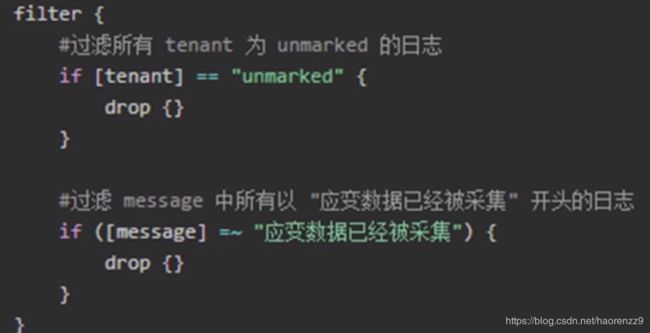
6,clone克隆操作 克隆增加 与克隆删除

7,geoip 对数据的IP地址增添维度

output 将通过索引数据输给ES 集群中

(二)ElasticSearch
(三)Kibana