HMM
本文接着上一篇的POS tagging来讲hidden markov model,以及如何使用HMM来做NLP任务的训练。
概率模型
假设我们的目标是给定一句话w(也就是一个序列),希望获得一组最优的tagging序列t,
再利用相互独立假设,
我们就得到了HMM模型,这里我们可以看到每个词只由他的tag决定,而每个tag都只由他前一个tag决定(马尔科夫链),hidden就体现在tag实际上我们是看不到的,前一个式子就是emission概率,后者为transition概率。
训练
HMM可以使Maximum Likelihood Estimation(MLE)来训练,概率的计算可以由统计频率来得到。例如
我们使用表示句子开始,用<\s>表示句子结束,遇到没见过的count我们可以使用smoothing方法。
训练中,我们不能按照一个词一个词地去预测tag,因为这样就变成了寻找最大化词的概率了,我们要找的是使得整句话概率最大的tag序列!下面介绍一种动态算法来解决这个问题。
Viterbi算法
举个栗子(基于bigram),

我们按照HMM公式通过查表(如下概率表)依次计算每个格子里的值,


这里的s表示前面计算出的score值,然后依次计算下去,最后得到
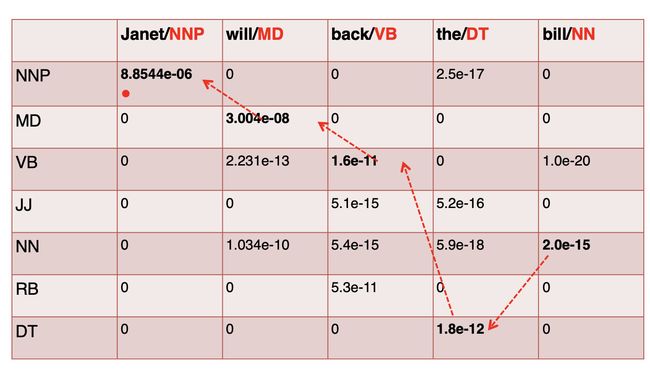
这个算法在bigram情况下的时间复杂度是O(T * T * N),T是tag集合的大小,N是序列的长度。
HMM作为一种非监督模型,也可以用作生成模型,根据我们训练好的数据来生成一些新的数据。
Discriminative model
除了使用贝叶斯假设,我们也可以通过其他更为直接的方法来描述\(P(t|w)\),
例如Maximum Entropy Markov Model(MEMM),Conditional random field (CRF), Connectionist Temporal Classification (CTC) 以及深度学习,这样我们可以加入更多需要的特征信息,但是模型不再是生成模型。